字符集、编码和Unicode
2016-05-29 22:23
579 查看
部分来自《深入理解C++11》。
在计算机中,总是使用二进制位组合来表示复杂的信息。首当其冲需要被标识的就是字符。为了使二进制组合标识字符的方法在不同设计的计算机间通用,就迫切需要统一的字符编码方法。于是在20世纪60年代的时候,ASCII字符编码就出现了。在ANSI颁布的标准中,基本ASCII的字符使用了7个二进制位进行标识,这意味着可以标识128种不同的字符。这对英文字符(以及一些控制字符、标点符号等)来说绰绰有余,不过随着计算机在全世界的普及,非字符构成的语言(如中文)也需要得到支持,
128个字符对于全世界众多语言而言就显得力不从心了。
到了20世纪90年代, ISO与Unicode两个组织共同发布了能够唯一地表示各种语言中的字符的标准。通常情况下, 我们将一个标准中能够表示的所有字符的集合称为字符集。通常,我们称ISO/Unicode所定义的字符集为Unicode。在Unicode中,每个字符占据一个码位(Code point)。Unicode字符集共定义了1 114 112个这样的位,使用从0到10FFFF的十六进制数唯一地表示所有的字符。虽然字符集中的码位唯一,但由于计算机存储数据通常是以字节为单位的,而且出于兼容之前的ASCII、大数小段数段、节省存储空间等诸多原因,通常情况下,我们需要一种具体的编码方式来对字符码位进行标识。比较常见的基于Unicode字符集的编码方式有UTF-8、UTF-16及UTF-32(一般人常常把UTF-16和Unicode混为一谈)。
以UTF-8为例,其采用了1-6字节的变长编码方式编码Unicode,英文通常使用1字节表示,且与ASCII是兼容的,而中文常用3字节标示。 下图表示的就是UTF-8的编码方式。UTF(Unicode Transformation Format ).
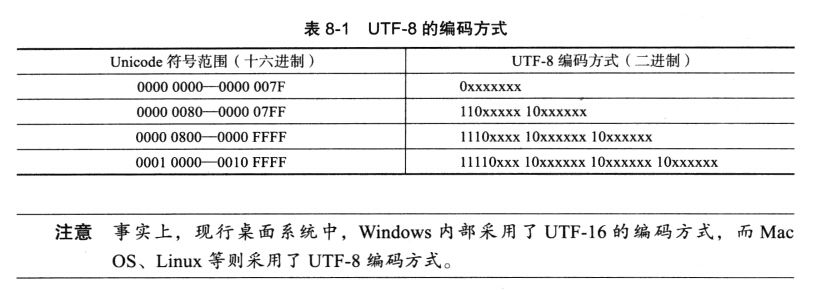
请注意UTF-8编码的规律! 提取出的x序列为 code-point的二进制数。
这篇文章很好:http://www.cnblogs.com/chenwenbiao/archive/2011/08/11/2134503.html
例如:
'黄' 的code-point为40644(也就是字符编号), 使用UTF-16的编码为 0x9EC4, 使用UTF-8的编码为 e9 bb 84(字节序列), 转成二进制如下:
11101001, 10111011, 10000100,根据上表,提取出x的序列为 1001111011 000100, 表示十进制的值为40644
这个网站可以查看Unicode字符集的code-point:http://unicode-table.com/cn/
请务必看此文:http://blog.csdn.net/natsu1211/article/details/8518398
这是英文原文:http://www.joelonsoftware.com/articles/Unicode.html
在计算机中,总是使用二进制位组合来表示复杂的信息。首当其冲需要被标识的就是字符。为了使二进制组合标识字符的方法在不同设计的计算机间通用,就迫切需要统一的字符编码方法。于是在20世纪60年代的时候,ASCII字符编码就出现了。在ANSI颁布的标准中,基本ASCII的字符使用了7个二进制位进行标识,这意味着可以标识128种不同的字符。这对英文字符(以及一些控制字符、标点符号等)来说绰绰有余,不过随着计算机在全世界的普及,非字符构成的语言(如中文)也需要得到支持,
128个字符对于全世界众多语言而言就显得力不从心了。
到了20世纪90年代, ISO与Unicode两个组织共同发布了能够唯一地表示各种语言中的字符的标准。通常情况下, 我们将一个标准中能够表示的所有字符的集合称为字符集。通常,我们称ISO/Unicode所定义的字符集为Unicode。在Unicode中,每个字符占据一个码位(Code point)。Unicode字符集共定义了1 114 112个这样的位,使用从0到10FFFF的十六进制数唯一地表示所有的字符。虽然字符集中的码位唯一,但由于计算机存储数据通常是以字节为单位的,而且出于兼容之前的ASCII、大数小段数段、节省存储空间等诸多原因,通常情况下,我们需要一种具体的编码方式来对字符码位进行标识。比较常见的基于Unicode字符集的编码方式有UTF-8、UTF-16及UTF-32(一般人常常把UTF-16和Unicode混为一谈)。
以UTF-8为例,其采用了1-6字节的变长编码方式编码Unicode,英文通常使用1字节表示,且与ASCII是兼容的,而中文常用3字节标示。 下图表示的就是UTF-8的编码方式。UTF(Unicode Transformation Format ).
请注意UTF-8编码的规律! 提取出的x序列为 code-point的二进制数。
这篇文章很好:http://www.cnblogs.com/chenwenbiao/archive/2011/08/11/2134503.html
例如:
'黄' 的code-point为40644(也就是字符编号), 使用UTF-16的编码为 0x9EC4, 使用UTF-8的编码为 e9 bb 84(字节序列), 转成二进制如下:
11101001, 10111011, 10000100,根据上表,提取出x的序列为 1001111011 000100, 表示十进制的值为40644
这个网站可以查看Unicode字符集的code-point:http://unicode-table.com/cn/
请务必看此文:http://blog.csdn.net/natsu1211/article/details/8518398
这是英文原文:http://www.joelonsoftware.com/articles/Unicode.html

相关文章推荐
- 2016 UESTC Training for Math(没有B H I)
- 第二阶段冲刺第三天
- 团队项目-个人博客5.29
- HDU 4535 吉哥系列故事——礼尚往来
- 消息机制
- Spring MVC 指定默认首页的办法
- MySQL学习16:多表连接
- C primer plus 第九章 练习3:
- Java面试题
- Struts2入门详解
- c语言学习笔记17之函数
- 推荐算法:基于内容的推荐_3: 用户特征
- Android RelativeLayout 属性详解
- Tinyhttp源码分析
- Mac配置 nginx Scrapy 安装问题解决方案
- 生活管家app
- Redis源码分析
- K-近邻算法
- Android 图片压缩之多种压缩方式结合使用
- Spring-JDBC