【DAY12】第十二天集合&泛型&IO学习笔记
2016-05-29 21:10
169 查看
hash:散列
------------------
Hashset集合内部是通过HashMap进行实现的。使用的是HashMap中key部分。
对象在添加进集合中时,首选会对hashcode进行处理(hashcode右移16位和
自身做异或运算)得到一个经过处理的hash值,然后该值和集合的容量进行
&运算,得到介于0和集合容量值之间一个数字。该数字表示着数组的下标。
也就是该元素应该存放在哪个元素中。
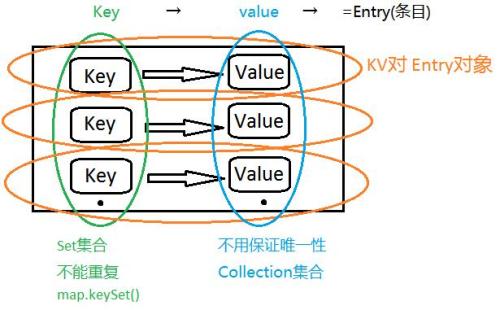
Map与Collection
--------------
Map与Collection在集合框架中属并列存在
Map存储的是键值(KV)(Key-Vaule)对
Map存储元素使用put方法,Collection使用add方法
Map集合没有直接取出元素的方法,而是先转成Set集合,在通过迭代获取元素
Map集合中键要保证唯一性
Map集合常用类
---------------
Hashtable:线程安全,速度慢,不允许存放null键,null值,已被HashMap替代。
HashMap:线程不安全,速度快,允许存放null键,null值。
TreeMap:对键进行排序,排序原理与TreeSet相同。
增强FOR循环
--------------
Collection在JDK1.5后出现的父接口Iterable就是提供了这个for语句。
格式:
可变长参数函数(只能有一个变长参数而且必须是最后一个)
---------------
提高了程序的安全性
将运行期遇到的问题转移到了编译期
省去了类型强转的麻烦
泛型类的出现优化了程序设计
IO流
----------------------
java.io.
IO流用来处理设备之间的数据传输
Java对数据的操作是通过流的方式
Java用于操作流的对象都在IO包中
流按操作数据分为两种:字节流与字符流。
流按流向分为:输入流,输出流。
IO流常用基类
-----------------------
字节流的抽象基类:
InputStream ,OutputStream。
字符流的抽象基类:
Reader , Writer。
注:由这四个类派生出来的子类名称都是以其父类名作为子类名的后缀。
如:InputStream的子类FileInputStream。
如:Reader的子类FileReader。
TIPS2:
进行IO异常处理
在finally中对流进行关闭 Close()
字符流+字节流
---------------
FilterWriter fw = new FileWriter();
FileReader : 不支持Rest,不支持mark,skip跳过指定字符数,>=0.
-------------------
输入流 + 输出流
------------------
本文出自 “yehomlab” 博客,转载请与作者联系!
------------------
Hashset集合内部是通过HashMap进行实现的。使用的是HashMap中key部分。
对象在添加进集合中时,首选会对hashcode进行处理(hashcode右移16位和
自身做异或运算)得到一个经过处理的hash值,然后该值和集合的容量进行
&运算,得到介于0和集合容量值之间一个数字。该数字表示着数组的下标。
也就是该元素应该存放在哪个元素中。
Map与Collection
--------------
Map与Collection在集合框架中属并列存在
Map存储的是键值(KV)(Key-Vaule)对
Map存储元素使用put方法,Collection使用add方法
Map集合没有直接取出元素的方法,而是先转成Set集合,在通过迭代获取元素
Map集合中键要保证唯一性
Map集合常用类
---------------
Hashtable:线程安全,速度慢,不允许存放null键,null值,已被HashMap替代。
HashMap:线程不安全,速度快,允许存放null键,null值。
TreeMap:对键进行排序,排序原理与TreeSet相同。
增强FOR循环
--------------
Collection在JDK1.5后出现的父接口Iterable就是提供了这个for语句。
格式:
for(数据类型 变量名 : 数组或Collection集合)
{
执行语句;
} 简化了对数组,集合的遍历。可变长参数函数(只能有一个变长参数而且必须是最后一个)
返回值类型 函数名(参数类型… 形式参数)
{
执行语句;
}泛型---------------
提高了程序的安全性
将运行期遇到的问题转移到了编译期
省去了类型强转的麻烦
泛型类的出现优化了程序设计
List<Srting> list1 = new ArrayList<String>(); //<E>类型通配符上限通过形如Box<? extends Number>形式定义,相对应的,类型通配符下限为 Box<? super Number>形式,其含义与类型通配符上限正好相反
IO流
----------------------
java.io.
IO流用来处理设备之间的数据传输
Java对数据的操作是通过流的方式
Java用于操作流的对象都在IO包中
流按操作数据分为两种:字节流与字符流。
流按流向分为:输入流,输出流。
IO流常用基类
-----------------------
字节流的抽象基类:
InputStream ,OutputStream。
字符流的抽象基类:
Reader , Writer。
注:由这四个类派生出来的子类名称都是以其父类名作为子类名的后缀。
如:InputStream的子类FileInputStream。
如:Reader的子类FileReader。
TIPS2:
进行IO异常处理
在finally中对流进行关闭 Close()
字符流+字节流
---------------
FilterWriter fw = new FileWriter();
FileReader : 不支持Rest,不支持mark,skip跳过指定字符数,>=0.
-------------------
输入流 + 输出流
------------------
本文出自 “yehomlab” 博客,转载请与作者联系!

相关文章推荐
- maven 详解
- C++走向远洋——58(项目二3、动物这样叫、改进版)
- java枚举:初学(2)
- pojFinancial Management1004
- U盘修复的一点小实践
- 多线程
- cojs QAQ的矩阵 题解报告
- 1445 送Q币
- 附3 springboot源码解析 - 构建SpringApplication
- 混合使用ForkJoin+Actor+Future实现一千万个不重复整数的排序(Scala示例)
- 第二阶段冲刺(第三天)
- html5 模块
- 面向对象
- 【css】选择器+盒子模型
- iOS离屏渲染优化
- SpringMVC下载服务器上的文件到本地
- 【面试】【MySQL常见问题总结】【01】
- C++作业6
- Hibernate:Caused by: java.sql.SQLException: Incorrect string value: '\xE8\x8F异常
- java枚举:初学(1)