管理Hbase表中的记录
2016-05-29 18:19
239 查看
一、实验题目
管理Hbase表中的记录。二、实验要求
Systemetrics是一家全球人力资源外包公司,利用Hbase管理人才记录。每当有员工加入时,公司都要在创建的表中增加一条新记录,按要求更新记录,并在员工辞职后删除他们的详细信息。三、操作步骤
1.在Ubuntu上安装Hbase;2.在Hbase shell界面创建名为“Employee”的数据表;
3.使用“list”命令查看数据表;
4.在Employee数据表中插入员工数据;
5.使用“get”和“scan”命令查看表中数据;
6.使用“disable”命令禁用Employee表;
7.使用“drop”命令删除数据、删除数据表;
四、实验结果
首先进入到hadoop的目录下,启动hadoop。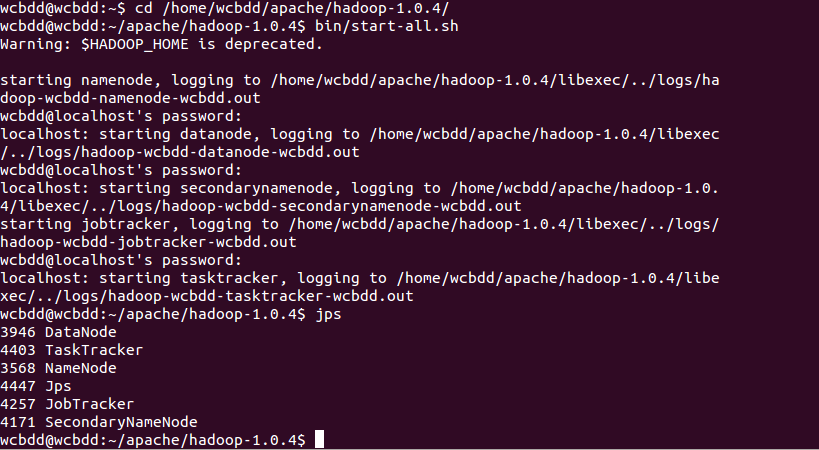
然后启动hbase
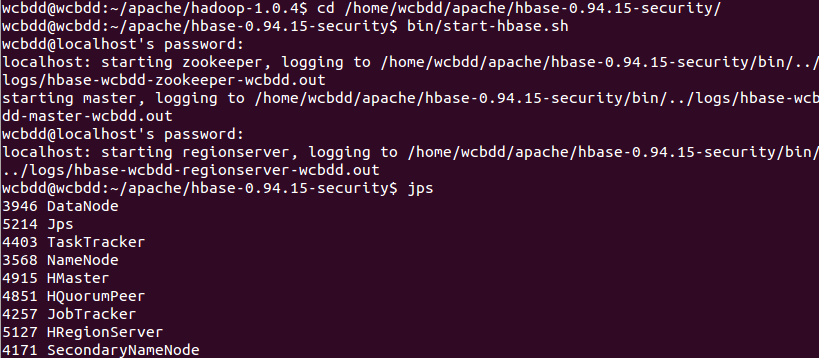
打开hbase shell开始实验。

输入list命令,查看现存表。

可以看到,目前是没有表的。通过create命令创建employee表。
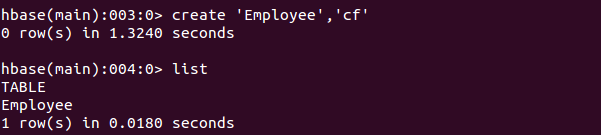
可以看到employee表创建成功,接着通过put命令来添加数据。
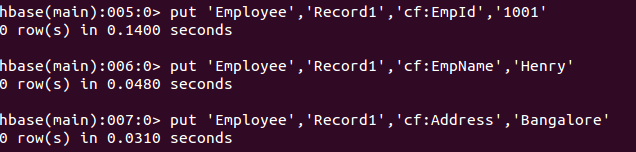
通过get来查看单条数据。

通过scan来获取整张表单的数据。

最后删除表。在使用drop之前要disable否则会报错。
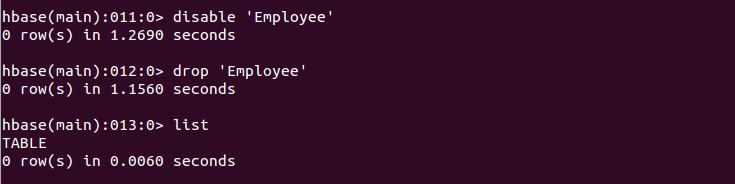
可以看到,表‘Employee成功被删除了,实验结束。

相关文章推荐
- 康诺云推出三款智能硬件产品,为健康管理业务搭建数据池
- MySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程
- php+ajax导入大数据时产生的问题处理
- C# 大数据导出word的假死报错的处理方法
- 用Python实现协同过滤的教程
- Python利用多进程将大量数据放入有限内存的教程
- mongodb常遇到的错误。
- Stack数据结构的特点后进先出的应用:大数据运算
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- Spark机器学习(二) 局部向量 Local-- Data Types - MLlib
- Spark机器学习(三) Labeled point-- Data Types
- YARN或将成为Hadoop新发力点
- Hadoop 1.x版本伪单机配置
- Glusterfs的编译选项 #pragma GCC poison system popen
- Python 大数据思维导图
- Spark HA部署方案
- Spark HA原理架构图
- HADOOP的HA部署方案