浅谈信息学竞赛中逆序对问题的求法
2016-05-29 15:33
281 查看
在信息学竞赛中,有一类问题叫做逆序对问题。对于该类问题的描述如下:
给你N个整数,每个数a[i]都是非负整数,求解其中满足这样性质的数对(i , j)的个数: 1
≤ i < j ≤ n 而且 a[i] > a[j].
其中1 ≤ N ≤
100000,时限为1s.
一种显然的思路是通过模拟冒泡排序算法的运行过程进行数对的统计,但冒泡排序算法的时间复杂度为O(n^2),显然无法在时限内完成题目的要求。
Niklaus
Wirth有一句人尽皆知的名言:“算法 + 数据结构 = 程序”。既然在算法上无法降低时间复杂度,那么我们可以去求助于万能的数据结构。
本题主要的难点在于,如何在时限内快速求出对于每一个j,满足i
< j ,而且 a[i] > a[j]的i的个数。
一种可行的方法是利用BIT(树状数组),其具有良好的树的二分结构,总时间复杂度为O(nlogn),可以在时限内完成求解。(本文中所有图片均来源于网络,且所有数据结构本文不予讲解,初学者可以自行搜索其他博客进行学习)
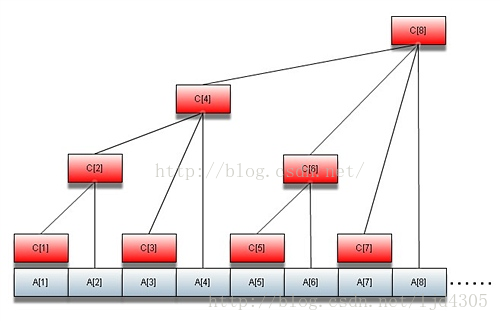
由于逆序对问题中我们只关注数字的大小关系而非其本身的数值,所以我们首先应对其进行离散化处理,即将其的值覆盖为其在序列中的大小次序,这样会使算法的时限容易很多。离散化预处理请读者自行完成,之后提供的代码默认离散化已完成。
我们可以这么搞:
1、设函数getsum(a[j]),其表示通过BIT查询得到的前j项的满足1
≤ i < j ≤ n 而且 a[i] > a[j]的数对的个数。
2、把j
- getsum(a[j])加到ans中。
3、把BIT中a[j]位置上的值+1。
为什么执行第三步呢?假设a[i]离散化后映射的值为x,那么比a[i]小的数的个数为getsum(x-1)。所以我们需要用BIT维护这个x位置,所以要有add(x,1)。理解了这里后代码便不难给出。
如果对于树状数组的运用不是特别熟练的话,这里还有一个易于理解且时间复杂度与BIT相同的方法:利用归并排序的思路分治解决逆序对的统计。
对于原先的数列A,模拟排序的过程会由于N的过大而超时。那么,我们可不可以折半这个时间呢?答案是可以。
我们将数列A拆分成两个数列----数列B与数列C,设a[i] a[j]是一对符合逆序对定义的数对。那么,有以下显然的三种情况:
1、i , j同属于数列B的逆序对
2、i , j同属于数列C的逆序对
3、i属于数列B但j属于数列C
对于情况1、2,我们可以递归的统计出逆序对的个数。而对于情况3,我们可以在归排的运行流程中统计出数列C中比a[i]大的数字个数,累加至答案即可。以上算法的时间复杂度为O(nlogn)。(以下程序参考《挑战程序设计竞赛》)
vector<int> A;
int merge_count(vector<int> &a){
int n=a.size(),cnt=0;
if(n<=1) return 0;
vector<int> b(a.begin(),a.begin()+(n>>1));
vector<int> c(a.begin()+(n>>1),a.end());
cnt+=merge_count(b);
cnt+=merge_count(c);
int ai=0,bi=0,ci=0;
while(ai<n){
if(bi<b.size() && ci==c.size() || b[bi]<=c[ci]){
a[ai++]=b[bi++];
}
else{
cnt+=(n>>1)-bi;
a[ai++]=c[ci++];
}
}
return cnt;
}
给你N个整数,每个数a[i]都是非负整数,求解其中满足这样性质的数对(i , j)的个数: 1
≤ i < j ≤ n 而且 a[i] > a[j].
其中1 ≤ N ≤
100000,时限为1s.
一种显然的思路是通过模拟冒泡排序算法的运行过程进行数对的统计,但冒泡排序算法的时间复杂度为O(n^2),显然无法在时限内完成题目的要求。
Niklaus
Wirth有一句人尽皆知的名言:“算法 + 数据结构 = 程序”。既然在算法上无法降低时间复杂度,那么我们可以去求助于万能的数据结构。
本题主要的难点在于,如何在时限内快速求出对于每一个j,满足i
< j ,而且 a[i] > a[j]的i的个数。
一种可行的方法是利用BIT(树状数组),其具有良好的树的二分结构,总时间复杂度为O(nlogn),可以在时限内完成求解。(本文中所有图片均来源于网络,且所有数据结构本文不予讲解,初学者可以自行搜索其他博客进行学习)
由于逆序对问题中我们只关注数字的大小关系而非其本身的数值,所以我们首先应对其进行离散化处理,即将其的值覆盖为其在序列中的大小次序,这样会使算法的时限容易很多。离散化预处理请读者自行完成,之后提供的代码默认离散化已完成。
我们可以这么搞:
1、设函数getsum(a[j]),其表示通过BIT查询得到的前j项的满足1
≤ i < j ≤ n 而且 a[i] > a[j]的数对的个数。
2、把j
- getsum(a[j])加到ans中。
3、把BIT中a[j]位置上的值+1。
为什么执行第三步呢?假设a[i]离散化后映射的值为x,那么比a[i]小的数的个数为getsum(x-1)。所以我们需要用BIT维护这个x位置,所以要有add(x,1)。理解了这里后代码便不难给出。
#include <cstdio>
#include <iostream>
#include <cstring>
#define ll long long
using namespace std;
const int MAXN=100000+10;
int N,a[MAXN],bit[MAXN];
inline int lowbit(int i){return i&-i;}
inline int getsum(int i){
int s=0;
while(i>0){
s+=bit[i];
i-=lowbit(i);
}
return s;
}
inline void add(int i,int x){
while(i<=N){
bit[i]+=x;
i+=lowbit(i);
}
}
int main(){
while(scanf("%d",&N) && N){
for(int i=0;i<N;i++) scanf("%d",&a[i]);
ll ans=0;
for(int j=0;j<N;j++){
ans+=j-getsum(a[j]);
add(a[j],1);
}
printf("%lld\n",ans);
}
return 0;
}如果对于树状数组的运用不是特别熟练的话,这里还有一个易于理解且时间复杂度与BIT相同的方法:利用归并排序的思路分治解决逆序对的统计。
对于原先的数列A,模拟排序的过程会由于N的过大而超时。那么,我们可不可以折半这个时间呢?答案是可以。
我们将数列A拆分成两个数列----数列B与数列C,设a[i] a[j]是一对符合逆序对定义的数对。那么,有以下显然的三种情况:
1、i , j同属于数列B的逆序对
2、i , j同属于数列C的逆序对
3、i属于数列B但j属于数列C
对于情况1、2,我们可以递归的统计出逆序对的个数。而对于情况3,我们可以在归排的运行流程中统计出数列C中比a[i]大的数字个数,累加至答案即可。以上算法的时间复杂度为O(nlogn)。(以下程序参考《挑战程序设计竞赛》)
vector<int> A;
int merge_count(vector<int> &a){
int n=a.size(),cnt=0;
if(n<=1) return 0;
vector<int> b(a.begin(),a.begin()+(n>>1));
vector<int> c(a.begin()+(n>>1),a.end());
cnt+=merge_count(b);
cnt+=merge_count(c);
int ai=0,bi=0,ci=0;
while(ai<n){
if(bi<b.size() && ci==c.size() || b[bi]<=c[ci]){
a[ai++]=b[bi++];
}
else{
cnt+=(n>>1)-bi;
a[ai++]=c[ci++];
}
}
return cnt;
}

相关文章推荐
- C#数据结构之顺序表(SeqList)实例详解
- Lua教程(七):数据结构详解
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- C#数据结构之队列(Quene)实例详解
- C#数据结构揭秘一
- C#数据结构之单链表(LinkList)实例详解
- 数据结构之Treap详解
- 用C语言举例讲解数据结构中的算法复杂度结与顺序表
- C#数据结构之堆栈(Stack)实例详解
- C#数据结构之双向链表(DbLinkList)实例详解
- JavaScript数据结构和算法之图和图算法
- Java数据结构及算法实例:冒泡排序 Bubble Sort
- Java数据结构及算法实例:插入排序 Insertion Sort
- Java数据结构及算法实例:考拉兹猜想 Collatz Conjecture
- java数据结构之java实现栈
- java数据结构之实现双向链表的示例
- Java数据结构及算法实例:选择排序 Selection Sort
- Java数据结构及算法实例:朴素字符匹配 Brute Force
- Java数据结构及算法实例:汉诺塔问题 Hanoi
- Java数据结构及算法实例:快速计算二进制数中1的个数(Fast Bit Counting)