【干货】C++哈希桶(开链法解决哈希冲突)类的实现
2016-05-28 18:37
281 查看
开链法(哈希桶)是解决哈希冲突的常用手法,结构如下:
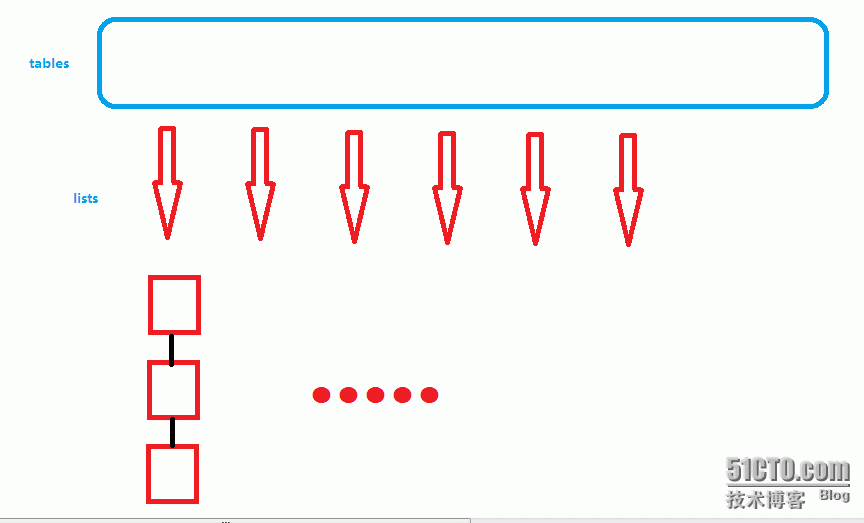
数据结构的设计思路是这样的,定义一个K—V的链式节点(Node),以数组方式存储节点指针
实现代码如下:
#include<vector>
#include"HashTable.h"
size_t GetSize()
{
static size_t index = 0;
const int _PrimeSize = 28;
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
return _PrimeList[index++];
}
template<class K,class V>
struct HashBucketNode
{
HashBucketNode(const K& key, const V& value)
:_key(key)
, _value(value)
, _next(NULL)
{}
K _key;
V _value;
HashBucketNode* _next;
};
template<class K, class V, class HashFunc = DefaultHash<K> >
class HashBucket
{
public:
typedef HashBucketNode<K,V> Node;
HashBucket()
:_size(0)
{
_tables.resize(0);
}
bool Push(const K& key, const V& value)
{
_CheckCapacity();
size_t index = HashFunc()(key) % _tables.size();
Node*cur = _tables[index];
while (cur)
{
if (cur->_key == key&&cur->_value == value)
return false;
cur = cur->_next;
}
Node*tmp = new Node(key, value);
if (_tables[index])
{
_tables[index]->_next = tmp->_next;
}
_tables[index] = tmp;
++_size;
return true;
}
void Swap(HashBucket & h)
{
swap(_size, h._size);
_tables.swap(h._tables);
}
Node* find(const K& key, const V& value)
{
size_t index = HashFunc()(key) % _tables.size();
Node*cur = _tables[index];
while (cur)
{
if (cur->_key == key&&cur->_value == value)
return cur;
cur = cur->_next;
}
return NULL;
}
bool Remove(const K& key)
{
size_t index = HashFunc()(key) % _tables.size();
if (_tables[index])
{
if (_tables[index]->key == key)
{
Node*tmp = _tables[index];
_tables[index] = tmp->_next;
delete tmp;
return true;
}
else
{
Node*cur = _tables[index];
while (cur->_next)
{
if (cur->_next->_key == key)
{
Node*tmp = cur->_next;
cur->_next = cur->_next->_next;
delete tmp;
return true;
}
cur = cur->_next;
}
}
}
return false;
}
protected:
void _CheckCapacity()
{
if (_size >= _tables.size())
{
HashBucket tmp;
tmp._tables.resize(GetSize());
for (size_t i = 0; i < tmp._tables.size(); ++i)
{
Node*cur = tmp._tables[i];
while (cur)
{
tmp.Push(cur->_key, cur->_value);
cur = cur->_next;
}
}
Swap(tmp);
}
}
protected:
vector<Node*> _tables;
size_t _size;
}; 如有不足希望指正,有疑问希望提出
数据结构的设计思路是这样的,定义一个K—V的链式节点(Node),以数组方式存储节点指针
实现代码如下:
#include<vector>
#include"HashTable.h"
size_t GetSize()
{
static size_t index = 0;
const int _PrimeSize = 28;
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
return _PrimeList[index++];
}
template<class K,class V>
struct HashBucketNode
{
HashBucketNode(const K& key, const V& value)
:_key(key)
, _value(value)
, _next(NULL)
{}
K _key;
V _value;
HashBucketNode* _next;
};
template<class K, class V, class HashFunc = DefaultHash<K> >
class HashBucket
{
public:
typedef HashBucketNode<K,V> Node;
HashBucket()
:_size(0)
{
_tables.resize(0);
}
bool Push(const K& key, const V& value)
{
_CheckCapacity();
size_t index = HashFunc()(key) % _tables.size();
Node*cur = _tables[index];
while (cur)
{
if (cur->_key == key&&cur->_value == value)
return false;
cur = cur->_next;
}
Node*tmp = new Node(key, value);
if (_tables[index])
{
_tables[index]->_next = tmp->_next;
}
_tables[index] = tmp;
++_size;
return true;
}
void Swap(HashBucket & h)
{
swap(_size, h._size);
_tables.swap(h._tables);
}
Node* find(const K& key, const V& value)
{
size_t index = HashFunc()(key) % _tables.size();
Node*cur = _tables[index];
while (cur)
{
if (cur->_key == key&&cur->_value == value)
return cur;
cur = cur->_next;
}
return NULL;
}
bool Remove(const K& key)
{
size_t index = HashFunc()(key) % _tables.size();
if (_tables[index])
{
if (_tables[index]->key == key)
{
Node*tmp = _tables[index];
_tables[index] = tmp->_next;
delete tmp;
return true;
}
else
{
Node*cur = _tables[index];
while (cur->_next)
{
if (cur->_next->_key == key)
{
Node*tmp = cur->_next;
cur->_next = cur->_next->_next;
delete tmp;
return true;
}
cur = cur->_next;
}
}
}
return false;
}
protected:
void _CheckCapacity()
{
if (_size >= _tables.size())
{
HashBucket tmp;
tmp._tables.resize(GetSize());
for (size_t i = 0; i < tmp._tables.size(); ++i)
{
Node*cur = tmp._tables[i];
while (cur)
{
tmp.Push(cur->_key, cur->_value);
cur = cur->_next;
}
}
Swap(tmp);
}
}
protected:
vector<Node*> _tables;
size_t _size;
}; 如有不足希望指正,有疑问希望提出

相关文章推荐
- 【代码】c++堆的简单实现
- 【代码】C++实现二叉树基本操作及测试用例
- 【代码】C++实现广义表及其测试用例
- 【干货】C++通过模板特化实现类型萃取实例--实现区分基本类型与自定义类型的memcpy
- 【总结】C++静态成员函数及测试用例
- 【总结】C++静态成员变量的特性总结及测试用例
- 【总结】C++静态成员变量的特性总结及测试用例
- 【总结】C++基类与派生类的赋值兼容规则
- 【C语言位运算的应用】如何按bit位翻转一个无符号整型
- 双向链表的C++实现
- C++单链表的设计与实现
- 求最大公约数的设计与C语言实现
- 用C语言实现二分查找算法
- C++复数类的运算符重载
- c++日期类的实现级运算符的重载
- C++实现链表的进本操作及测试用例
- C语言实现顺序表的增删查改以及排序
- C语言实现C到C++的注释转换
- C语言用结构体写一个通讯录
- C语言模拟实现memset.memcmp函数