数组元素奇偶排序程序中的死循环引起的思考
2016-05-27 22:57
260 查看
一、问题描述
有一数组:a[8] = {56,68,20,15,17,101,132,119,}对该数组进行排序使得奇数全部在偶数的前面,并且不可以引进分配新的数组空间。
二、问题解决
看到这样的题目,也许会觉得很简单,因为题目的目的很明确,只要将奇数全部移到偶数的前面即可,而奇数与奇数之间、偶数与偶数之间都不要求顺序。最开始我想到了如下代码:void sort_one(int * a,int len)
{
int i, j;
int temp;
for (i=1; i<len; i++)
{
if (a[i]%2 != 0)
{
temp = a[i];
for (j=i; j>0; j--)
a[j] = a[j-1];
a[0] = temp;
}
}
}由于该段代码中a[i]只要是奇数就将a[i]移动到数组首位置,而a[0]至a[i-1]依次向后移动到a[2]至a[i]的位置,该方法决定了判断只需从a[1]开始。若是不满足if语句,i就加1,判断下一个即可,外层for循环执行完成时,奇偶排序也就完成了。
三、虽为“同胞兄弟”确是“死胎”的一段代码
上面的程序是我自己见到这样的问题时的第一想法,当时写完之后没有出错也就没有再管,而一个月后,又看到别人写了下面这段类似于sort_one(int * a,int len),却无任何输出的程序:void sort_error(int * a, int len)
{
int temp;
int i = 0;
while(i<len)//只要数组中有一个偶数就会陷入死循环
{
if(a[i]%2 != 0)
i++;
else
{
temp = a[i];
for(int j = i; j<len; j++)
a[j] = a[j+1];
a[j] = temp;
}
}
}该程序思路与sort_one(int * a,int len)思路刚好相反,sort_one(int * a,int len)是将奇数放到最前面,sort_error(int * a,int len)则是将偶数移到到数组最后面,判断并处理完成之后,也是奇数在前偶数在后。从思路上看起来似乎可行,但是却没有任何输出,这段程序引发了我的思考。用图来说明:
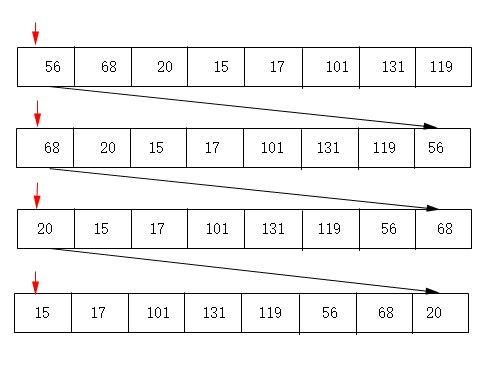
当i=0时,a[0]=56是偶数,移到最后面;68向前移到a[0],依旧是偶数,移到后面;20向前移到a[0],仍然是偶数,再移到最后面;15向前移到a[0],不是偶数,则i++;17、101、131、119均是奇数,i继续自加。
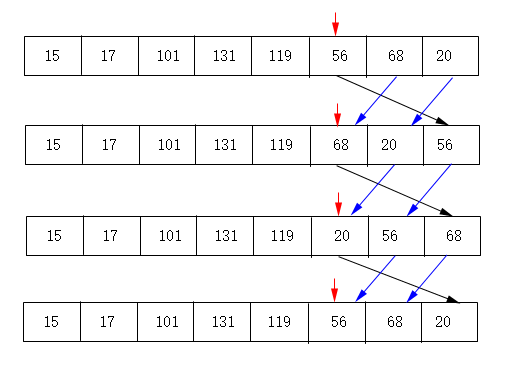
当i加到如上图所示:a[i]=56,是偶数,则56移到数组最后;68、20前移,a[i]=68,是偶数,则68移到数组最后;20、56前移,a[i]=20,是偶数,则20移到数组最后;56、68再前移,a[i]=56……,由于没有奇数,i便不能自加,i < len一直成立,循环无法退出便进入了死循环。只要数组中有一个偶数,便会形成死循环,此段程序也就没有任何作用。
四、妙手回春
对于sort_error(int * a,int len),其主要问题在于它自身的退出循环条件与程序的执行方式相互冲突:i在遇到偶数时不能自加,而把偶数都移到最后导致i始终不能加到len,程序陷入死循环可谓是“自作孽,不可活”。那么我们的解决方法就是使循环结束条件与执行方式不冲突。而唯一的办法就是当偶数向后移动一次,退出循环的条件就不能再是i < len了,而是在i < len-1,若是移动了两次,那么数组最后应有两个偶数,而退出条件也应该成为i < len-2 ……,所以我们不妨设定一个标志point = len-1,每当偶数向后移动一个,point就自减一次,而退出循环的条件改为i < point即可。代码如下:
void sort_two(int * a, int len)
{
int i = 0;
int j, temp;
int point = len-1;
while(i < point)
{
if(a[i] % 2 != 0)
i ++;
else
{
temp = a[i];
for(j = i; j < point; j++)
a[j] = a[j+1];
a[j] = temp;
point --;
}
}
}即使数组全是偶数i不自加,但每移动一次point自减一次,最终i < point也能不成立,不会陷入死循环。
五、更胜一筹的算法
以上两种算法,都是我们最直接最容易想到的,但是一般情况下最直接的方法都不是最高效的算法。因为我们为了解决问题而解决问题都会想到思维量小的方法,而思维量越小发现问题的本质不会深入,得出的结果自然不会高效。void sort_two()和void sort_one()由于每次移动一个满足判断条件的数,都要成批地依次移动起点到目的点之间的所有数据元素,把不必要的步骤执行了许多遍。那么如果我们让i从前往后找偶数,让j从后向前找奇数,并把从前面找到的第一个偶数与从后面找到的第一个奇数互换位置,而不动其它不相关的数,之后继续执行以上操作,把从前面找到的第二个偶数与从后面找到的第二个奇数互换位置……当i与j的相对位置变成i后j前时,奇数就全部移到偶数的前面了。代码如下:
void sort_three(int * a, int len)
{
int i = 0;
int j = len-1;
int temp;
while(i<j)
{
while(i<len && a[i]%2 != 0)
i++;
while(j>-1 && a[j]%2 == 0)
j--;
if(i<j)
{
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}循环继续执行的条件是i < j,而a[i]与a[j]交换的条件也是i < j。因为当i > j时,如果交换a[i]与a[j],就又把奇数从前面移到后面,偶数从后面移到前面了。
例如:原题中代码
a[8] = {56,68,20,15,17,101,132,119,}用sort_three()只需要将不同的a[i]与a[j]互换三次即可,即使奇数全在偶数后面,最多也仅仅是需要互换len/2次。而sort_one()和sort_two()仅仅是移动元素就需要移动二三十次,当数组过长时其缺点就显得尤为突出。
六、算法时间复杂度与高效性的非必然联系
在以上所有程序都是两层循环,时间复杂度都是O(n^2),我们将sort_three()稍作修改就可以降低其时间复杂度,代码如下:void sort_four(int *a, int len)
{
int i = 0;
int j = len-1;
int temp;
while (i<j)
{
if(a[i] % 2 != 0)
i++;
else if(a[j] % 2 == 0)
j--;
else
{
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}少了一层循环嵌套,时间复杂度虽然降低了,但是并没有比sort_three()高效,因为其算法相同,代码执行步骤也是一样的。

相关文章推荐
- Ukey,网页,web demo访问U盘用户验证
- 什么是架构
- 自适应网页设计的方法
- HDU 1016 Prime Ring Problem
- 线程的五种状态
- 考研复习第四天-线性代数-矩阵的初等线性变换
- 但是安装完之后,发现ifconfig没看到熟悉的eth0,却是enp0s3,于是想把他改回来
- Xcode的Hello World(简单易懂)
- 团队第二次冲刺03(5.27)
- 《构建之法》8,9,10章读后感和总结
- C语言知识点
- 给外网访问本地网站
- 第二轮冲刺-Runner站立会议05
- [javaSE] 集合工具类(Collections-sort)
- 经典面试题:一张表区别DOM解析和SAX解析XML
- 搞机器学习需要哪些技能
- 经典面试题:一张表区别DOM解析和SAX解析XML
- Hdu 3552 I can do it!(贪心)
- OC语言基础知识
- Web中的无状态含义