数据结构与对象
2016-05-24 17:08
525 查看
第 1 步:阅读数据结构实现
刚开始阅读 Redis 源码的时候, 最好从数据结构的相关文件开始读起, 因为这些文件和 Redis 中的其他部分耦合最少, 并且这些文件所实现的数据结构在大部分算法书上都可以了解到, 所以从这些文件开始读是最轻松的、难度也是最低的。
下表列出了 Redis 源码中, 各个数据结构的实现文件:
文件 内容
sds.h 和 sds.c Redis 的动态字符串实现。
adlist.h 和 adlist.c Redis 的双端链表实现。
dict.h 和 dict.c Redis 的字典实现。
redis.h 中的 zskiplist 结构和 zskiplistNode 结构, 以及 t_zset.c 中所有以 zsl 开头的函数, 比如 zslCreate 、 zslInsert 、 zslDeleteNode ,等等。 Redis 的跳跃表实现。
hyperloglog.c 中的 hllhdr 结构, 以及所有以 hll 开头的函数。 Redis 的 HyperLogLog 实现。
动态字符串与C字符串的区别:
①常数复杂度获取字符串长度。
strlen() sdshdr.len
②杜绝缓冲区溢出。
strcat(),sdshdr.free当需要对sds修改时,会先检查空间是否满足修改所需的要求,如果不满足,会先扩展空间,然后才执行修改。
③减少修改字符串时带来的内存重分配次数。
通过未使用空间,sds实现了空间预分配和惰性空间释放两种优化策略。
④二进制安全。
sds.buf称为“字节数组”的原因:redis不是用这个数组来保存字符,而是用它来保存一系列二进制数据。

⑤兼容部分C字符串函数。

链表节点
链表结构
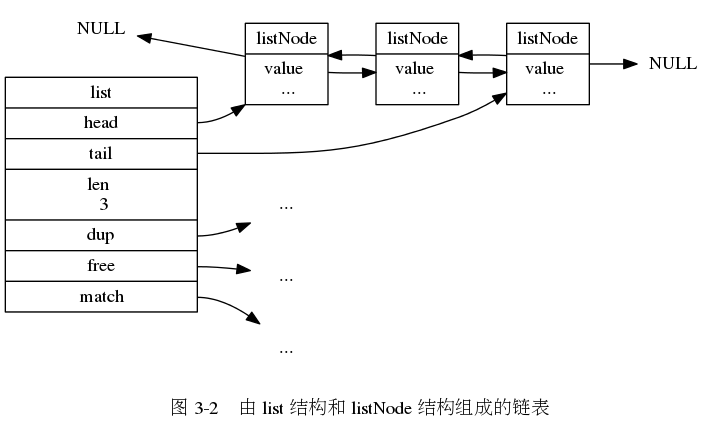
特性总结

哈希表节点
哈希表
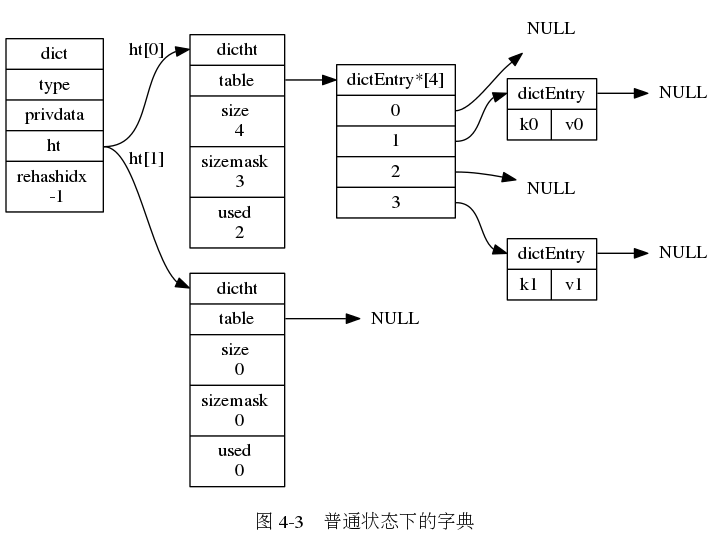
字典:
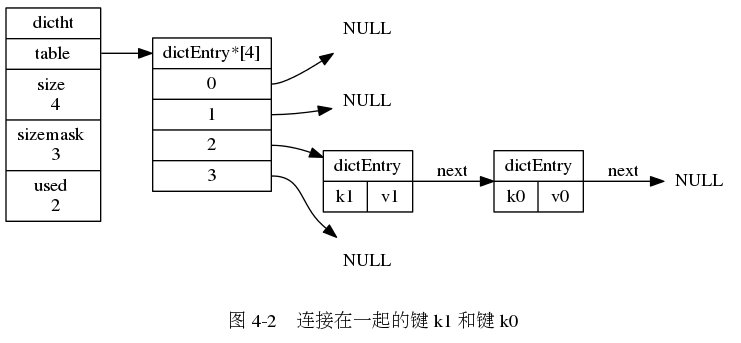
使用链地址法解决冲突的哈希表:


跳跃表节点,定义在redis.h中
跳跃表
跳跃表示意图

跳跃表的实现:http://origin.redisbook.com/internal-datastruct/skiplist.html#id3
刚开始阅读 Redis 源码的时候, 最好从数据结构的相关文件开始读起, 因为这些文件和 Redis 中的其他部分耦合最少, 并且这些文件所实现的数据结构在大部分算法书上都可以了解到, 所以从这些文件开始读是最轻松的、难度也是最低的。
下表列出了 Redis 源码中, 各个数据结构的实现文件:
文件 内容
sds.h 和 sds.c Redis 的动态字符串实现。
adlist.h 和 adlist.c Redis 的双端链表实现。
dict.h 和 dict.c Redis 的字典实现。
redis.h 中的 zskiplist 结构和 zskiplistNode 结构, 以及 t_zset.c 中所有以 zsl 开头的函数, 比如 zslCreate 、 zslInsert 、 zslDeleteNode ,等等。 Redis 的跳跃表实现。
hyperloglog.c 中的 hllhdr 结构, 以及所有以 hll 开头的函数。 Redis 的 HyperLogLog 实现。
1、动态字符串
sds.h 和 sds.c Redis 的动态字符串实现。/*
* 保存字符串对象的结构
*/
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};动态字符串与C字符串的区别:
①常数复杂度获取字符串长度。
strlen() sdshdr.len
②杜绝缓冲区溢出。
strcat(),sdshdr.free当需要对sds修改时,会先检查空间是否满足修改所需的要求,如果不满足,会先扩展空间,然后才执行修改。
③减少修改字符串时带来的内存重分配次数。
通过未使用空间,sds实现了空间预分配和惰性空间释放两种优化策略。
④二进制安全。
sds.buf称为“字节数组”的原因:redis不是用这个数组来保存字符,而是用它来保存一系列二进制数据。
⑤兼容部分C字符串函数。
2、链表
adlist.h 和 adlist.c Redis 的双端链表实现。链表节点
/*
* 双端链表节点
*/
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value; //可见,链表中保存的是指向数据的指针.void*可用来保存不同类型的值。
} listNode;链表结构
/*
* 双端链表结构
*/
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
// 链表所包含的节点数量
unsigned long len;
} list;特性总结
3、字典
dict.h 和 dict.c Redis 的字典实现。redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典的一个键值对。(注:STL中std::map的底层实现是红黑树)
哈希表节点
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表,将多个哈希值相同的键值对连接在一起,以此解决键冲突的问题。
struct dictEntry *next;
} dictEntry;哈希表
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
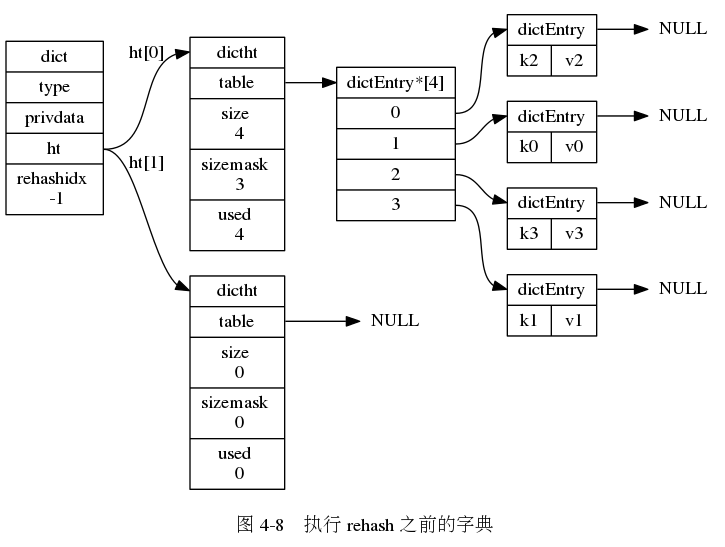
} dictht;字典:
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;冲突:两个或以上数量的键值散列到哈希表数组的同一个索引上面。 redis的哈希表使用“分离链接法”解决冲突。每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引的多个节点可以用这个单向链表链接起来,解决键值冲突问题。
使用链地址法解决冲突的哈希表:
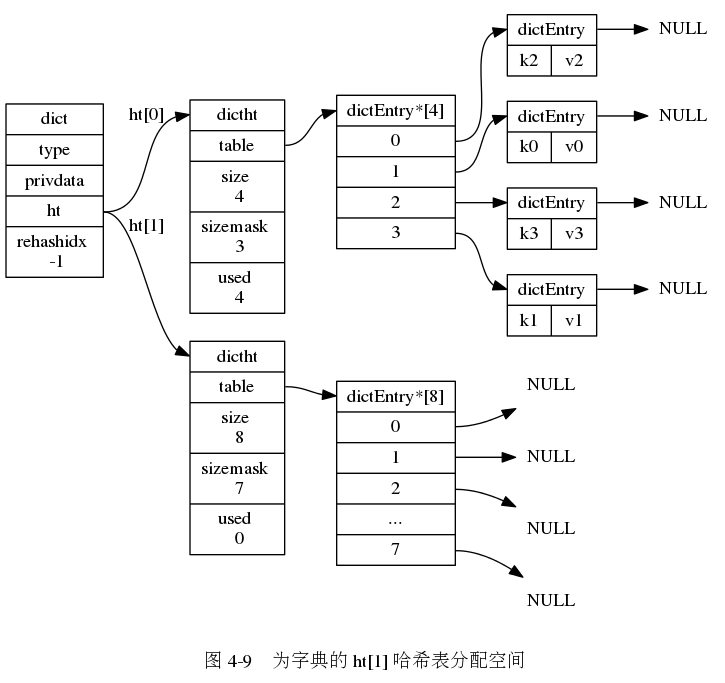
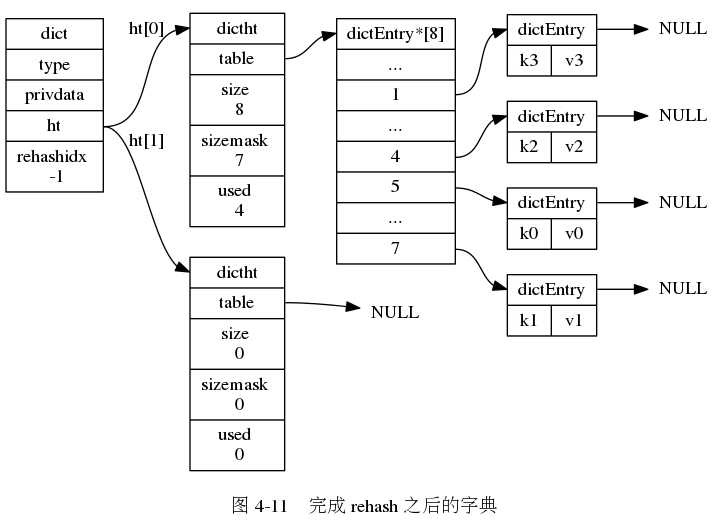
rehash: 为了让哈希表的负载因子维持在一个合理的范围之内,当哈希表保存的键值对数量太多或太少时,程序需要对哈希表的大小进行扩展或者收缩。扩展或收缩哈希表的工作通过rehash(再散列)操作完成。 每个字典带有两个哈希表,一个平时使用,另一个仅在进行rehash时使用。
4、跳跃表
Redis 的跳跃表实现: redis.h 中:的 zskiplist 结构和 zskiplistNode 结构, 以及 t_zset.c 中所有以 zsl 开头的函数, 比如 zslCreate 、 zslInsert 、 zslDeleteNode ,等等。跳跃表节点,定义在redis.h中
/* ZSETs use a specialized version of Skiplists */
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;跳跃表
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;跳跃表示意图
跳跃表的实现:http://origin.redisbook.com/internal-datastruct/skiplist.html#id3

相关文章推荐
- python中的数据结构与算法
- 【原】iOS学习之XML与JSON两种数据结构比较和各自底层实现
- 数据结构---线段树
- 堆排序
- 数据结构课后题源码
- 数据结构之堆(Heap)的实现
- 基本数据结构概念
- 基本数据结构概念
- 基本数据结构概念
- 比较无聊的一个东西:用数据结构的内容整合成的一个程序900多行代码.
- 数据结构 --- 栈和队列
- 数据结构之------深度优先搜索(DFS)
- 算法之------错排问题
- 数据结构之堆的实现
- 冒泡排序及其改进
- 使用不完全填满数组的实现的循环FIFO(队列)
- Gson
- 串的模式匹配(BF算法,KMP算法)
- 绘图神器 —— Graphviz 绘制数据结构相关图形
- 数据结构和算法 – 7.散列和 Hashtable 类