Wooyun最新确认漏洞爬虫V0.02
2016-05-22 15:48
489 查看
Wooyun最新确认漏洞爬虫v0.02
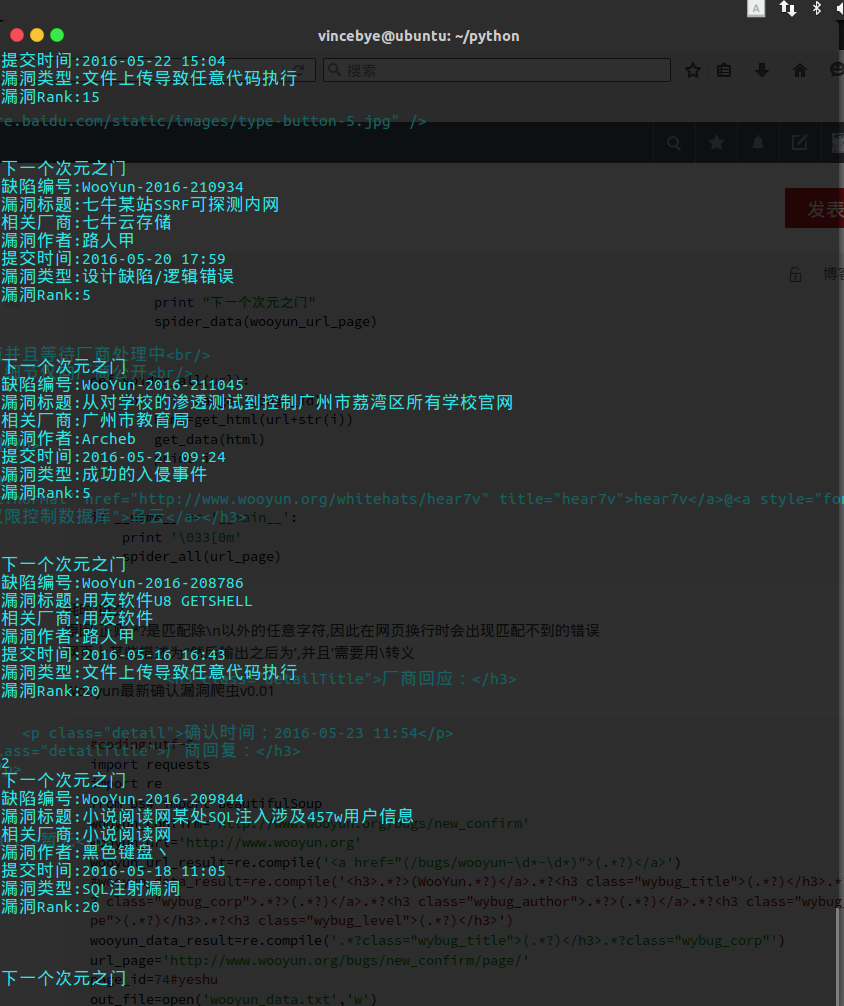
耗时:挺久
原因:正则.*?是匹配除\n以外的任意字符,因此在网页换行时会出现匹配不到的错误
网页上某些描述为”然后输出之后为’,并且’需要用\转义
Wooyun最新确认漏洞爬虫v0.01
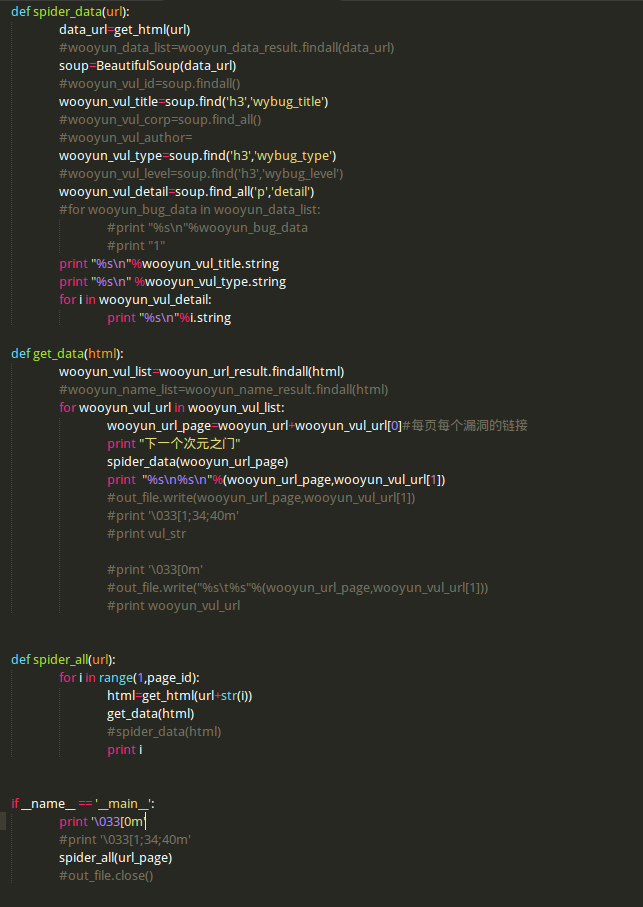
耗时:挺久
代码是个半成品,很多问题,很多空格,很多很多。起初用正则,匹配的时候有点问题,怎么都匹配不到目标字符。后来采用BeautifulSoup,还是在细节匹配上有些问题,rank排序,完全没到那一步
#coding:utf-8
import requests
import re
from bs4 import BeautifulSoup
wooyun_confirm='http://www.wooyun.org/bugs/new_confirm'
wooyun_url='http://www.wooyun.org'
wooyun_url_result=re.compile('<a href="(/bugs/wooyun-\d*-\d*)">(.*?)</a>')
wooyun_data_result=re.compile(u'<h3>缺陷编号:.*?">(.*)</a>[\w\W]*漏洞标题:(.*?)</h3>[\s\S]*?<h3 class=\'wybug_corp\'>相关厂商: <a href="http://www.wooyun.org/corps/(.*?)">[\w\W]*?<h3 class=\'wybug_author\'>漏洞作者: <a href="http://www.wooyun.org/whitehats/(.*?)">[\w\W]*?<h3 class=\'wybug_date\'>提交时间:(.*?)</h3>[\w\W]*?<h3 class=\'wybug_type\'>漏洞类型: (.*?)</h3>[\w\W]*?<p class="detail">漏洞Rank:(.*?) </p>')
url_page='http://www.wooyun.org/bugs/new_confirm/page/'
page_id=74#yeshu
req_header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept':'text/html;q=0.9,*/*;q=0.8',
'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding':'gzip',
'Connection':'close',
'Referer':None
}
def get_html(url):
return requests.get(url,headers=req_header).text
def spider_data(url):
data_url=get_html(url)
wooyun_data_list=wooyun_data_result.findall(data_url)
for wooyun_bug_data in wooyun_data_list:
print u"缺陷编号:%s\n漏洞标题:%s\n相关厂商:%s\n漏洞作者:%s\n提交时间:%s\n漏洞类型:%s\n漏洞Rank:%s\n\n\n"%(wooyun_bug_data[0],wooyun_bug_data[1].strip(),wooyun_bug_data[2].strip(),wooyun_bug_data[3].strip(),wooyun_bug_data[4].strip(),wooyun_bug_data[5].strip(),wooyun_bug_data[6].strip())
def get_data(html):
wooyun_vul_list=wooyun_url_result.findall(html)
for wooyun_vul_url in wooyun_vul_list:
wooyun_url_page=wooyun_url+wooyun_vul_url[0]#每页每个漏洞的链接
print "下一个次元之门"
spider_data(wooyun_url_page)
def spider_all(url):
for i in range(1,page_id):
html=get_html(url+str(i))
get_data(html)
print i
if __name__ == '__main__':
print '\033[0m'
spider_all(url_page)耗时:挺久
原因:正则.*?是匹配除\n以外的任意字符,因此在网页换行时会出现匹配不到的错误
网页上某些描述为”然后输出之后为’,并且’需要用\转义
Wooyun最新确认漏洞爬虫v0.01
#coding:utf-8
import requests
import re
from bs4 import BeautifulSoup
wooyun_confirm='http://www.wooyun.org/bugs/new_confirm'
wooyun_url='http://www.wooyun.org'
wooyun_url_result=re.compile('<a href="(/bugs/wooyun-\d*-\d*)">(.*?)</a>')
#wooyun_data_result=re.compile('<h3>.*?>(WooYun.*?)</a>.*?<h3 class="wybug_title">(.*?)</h3>.*?<h3 class="wybug_corp">.*?>(.*?)</a>.*?<h3 class="wybug_author">.*?>(.*?)</a>.*?<h3 class="wybug_type">(.*?)</h3>.*?<h3 class="wybug_level">(.*?)</h3>')
wooyun_data_result=re.compile('.*?class="wybug_title">(.*?)</h3>.*?class="wybug_corp"')
url_page='http://www.wooyun.org/bugs/new_confirm/page/'
page_id=74#yeshu
out_file=open('wooyun_data.txt','w')
#wooyun_name_result=re.compile('<a href=.*>(.*)</a>')
req_header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept':'text/html;q=0.9,*/*;q=0.8',
'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding':'gzip',
'Connection':'close',
'Referer':None
}
def get_html(url):
return requests.get(url,headers=req_header).text
def spider_data(url):
data_url=get_html(url)
#wooyun_data_list=wooyun_data_result.findall(data_url)
soup=BeautifulSoup(data_url)
#wooyun_vul_id=soup.findall()
wooyun_vul_title=soup.find('h3','wybug_title')
#wooyun_vul_corp=soup.find_all()
#wooyun_vul_author=
wooyun_vul_type=soup.find('h3','wybug_type')
#wooyun_vul_level=soup.find('h3','wybug_level')
wooyun_vul_detail=soup.find_all('p','detail')
#for wooyun_bug_data in wooyun_data_list:
#print "%s\n"%wooyun_bug_data
#print "1"
print "%s\n"%wooyun_vul_title.string
print "%s\n" %wooyun_vul_type.string
for i in wooyun_vul_detail:
print "%s\n"%i.string
def get_data(html):
wooyun_vul_list=wooyun_url_result.findall(html)
#wooyun_name_list=wooyun_name_result.findall(html)
for wooyun_vul_url in wooyun_vul_list:
wooyun_url_page=wooyun_url+wooyun_vul_url[0]#每页每个漏洞的链接
print "下一个次元之门"
spider_data(wooyun_url_page)
print "%s\n%s\n"%(wooyun_url_page,wooyun_vul_url[1])
#out_file.write(wooyun_url_page,wooyun_vul_url[1])
#print '\033[1;34;40m'
#print vul_str
#print '\033[0m'
#out_file.write("%s\t%s"%(wooyun_url_page,wooyun_vul_url[1]))
#print wooyun_vul_url
def spider_all(url):
for i in range(1,page_id):
html=get_html(url+str(i))
get_data(html)
#spider_data(html)
print i
if __name__ == '__main__':
print '\033[0m'
#print '\033[1;34;40m'
spider_all(url_page)
#out_file.close()耗时:挺久
代码是个半成品,很多问题,很多空格,很多很多。起初用正则,匹配的时候有点问题,怎么都匹配不到目标字符。后来采用BeautifulSoup,还是在细节匹配上有些问题,rank排序,完全没到那一步

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法