算法之冒泡排序
2016-05-22 09:36
447 查看
什么是冒泡排序
冒泡排序是排序中经典排序之一,它利用相邻元素比较并进行位置的互换,让元素按照从小到大的顺序排列。原理解释:
相邻的两个元素比较,如果如果元素1大于元素2则元素1与元素二的位置互换。怎么进行位置互换呢?把元素1先定义到额外的变量里面,让元素1与元素2进行互换,如果互换完成了。再把互换后的元素1也就是现在的元素2,重新定义回原来的变量,这样就实现了互换。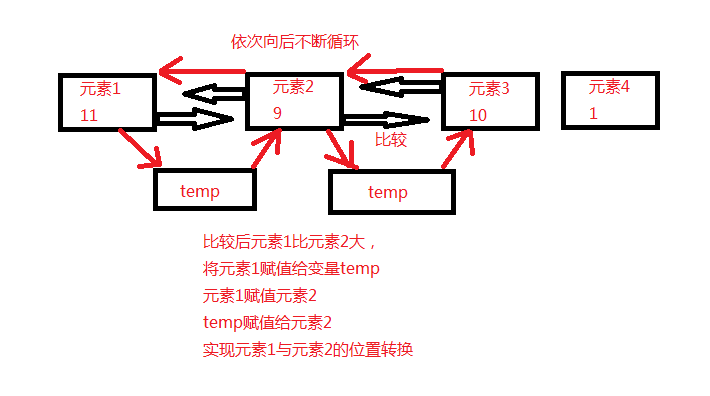
单元素比较
li = [11, 9, 10, 1] for m in range(len(li)-1): #确定循环的次数-1是因为从0开始的 if li[m] > li[m+1]: #相邻的元素比较 temp = li[m+1] li[m+1] = li[m] li[m] = temp print(li)
冒泡排序的基本比较方式已经有了,现在进一步解析冒泡排序的原理
需求:
将所有元素按照从小到大的顺序排列
li = [11, 9, 10, 1] for m in range(len(li)-1): if li[m] > li[m+1]: temp = li[m+1] li[m+1] = li[m] li[m] = temp
已经把最大的数字移动到最后个元素位了,下面把第二大的移动到倒数第二位元素
for m in range(len(li)-2): if li[m] > li[m+1]: temp = li[m+1] li[m+1] = li[m] li[m] = temp
依次类推,继续操作:
for m in range(len(li)-3): if li[m] > li[m+1]: temp = li[m+1] li[m+1] = li[m] li[m] = temp for m in range(len(li)-3): if li[m] > li[m+1]: temp = li[m+1] li[m+1] = li[m] li[m] = temp
for m in range(len(li)-4): if li[m] > li[m+1]: temp = li[m+1] li[m+1] = li[m] li[m] = temp print(li)
因为列表li的字符一共有4个元素,-3就已经到了最前面两个字符做比较了,这样就不用继续下去了。
上面繁琐重复的代码可以达到我们预期的效果,那么能不能运用for循环的方式,精简代码达到同样的目的呢?
li = [11, 9, 10, 1] for m in range(1, len(li)): for i in range(len(li) - m): if li[i] > li[i + 1]: temp = li[i+1] li[i+1] = li[i] li[i] = temp print(li) [1, 9, 10, 11]
最终我们得到以上语句,到此冒泡排序就已经出来了。
注意:
len(li) 如果只查看位数的话,是占4位;如果进行for循环位数的话是用0开始循环。两个for循环的关系有点复杂,第一个for循环得出来的是li的位数,其实最重要的是第二个for循环,第二次for循环完成的时候,就已经完成了一次排序。

相关文章推荐
- 冒泡排序
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- c语言实现的带通配符匹配算法
- C++实现对输入数字组进行排序
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法
- 基于C++实现的各种内部排序算法汇总