机器学习中各种距离计算
2016-05-21 16:54
253 查看
机器学习中,经常需要计算各种距离。
比如KNN近邻的距离,Kmeans距离,相似度中的距离计算。
这种距离不一定都是欧氏距离,针对不同需求,数据的不同特点,距离的计算方式不同。
下面给出机器学习中常用的距离计算方式,及其应用特点。
对于距离,有如下基本特性:
1、d(x, x)=0 //到自己的距离为0
2、d(x ,y)>=0 //距离非负
3、d(x, y)=d(y, x) //距离对称性,A到B的距离,B到A的距离是相等的
4、d(x, z)+d(z, y)>=d(x, y) //三角形法则,两边之和大于第三边
1、闵可夫斯基距离(Minkowski distance)
衡量数值点之间距离的常用方法。公式如下。
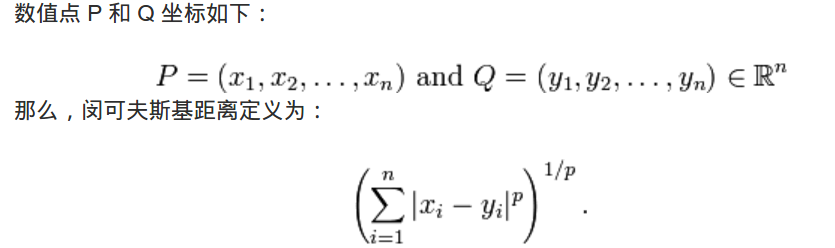
该距离最常见形式是P=2或者1,分别对应欧氏距离、曼哈顿距离。
见下图,网格表示城市街区交通道路,直线表示欧式距离,显示情况在存在高楼,不能直接穿过,折线表示曼哈顿距离,其长度是相等的。
但公司中的P趋于无穷大时,闵可夫斯基距离就转化为切比雪夫距离(Chebyshev distance).
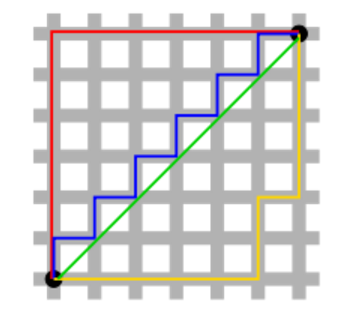
我们知道,平面上的距离原点欧氏距离(P=2)为1的点组成的形状为圆,但P取其他值时?见下图。

可知,切比雪夫距离近似一个正方形。
注意:当P<1时,闵可夫斯基距离不符合三角形法则。比如:P<1时,(0,0)(1,1)两点的距离为(1,1)^1/p>2,而(0,1)到这两点的距离都为1.
特点:闵可夫斯基距离比较直观,与数据分布无关,具有一定局限性。比如X方向的幅值远远大于Y方向的值,则闵可夫斯基距离会过度放大X维度的作用。可以在计算距离时,利用Z-transform处理,减去均值,除以方差。

可知,此时处理体现数据的统计特性了,但其假设是,数据之间不是相关的。比如,人的身高跟体重是有相关性的,这样的数据,就需要用马氏距离了。
2、马氏距离(mahalanobis distance)
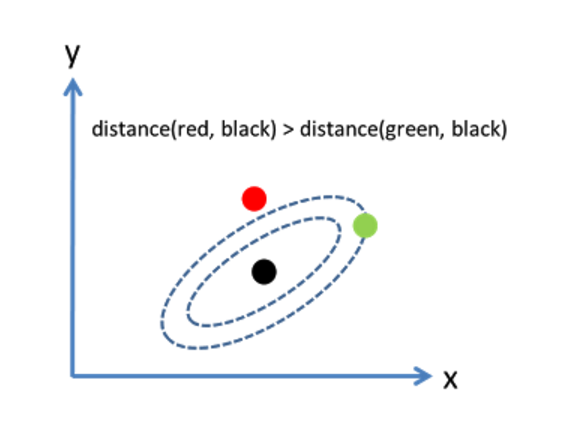
先看例子,图中黑绿球的欧氏距离>黑红球;相反,黑绿球的马氏距离<黑红球。
这是因为马氏距离考虑了数据之间的相关性,利用cholesky transformation消除了不同维度之间的相关性和尺寸不同。
具体换换公式参考文章1.
举个例子,如图,下面的样本点。
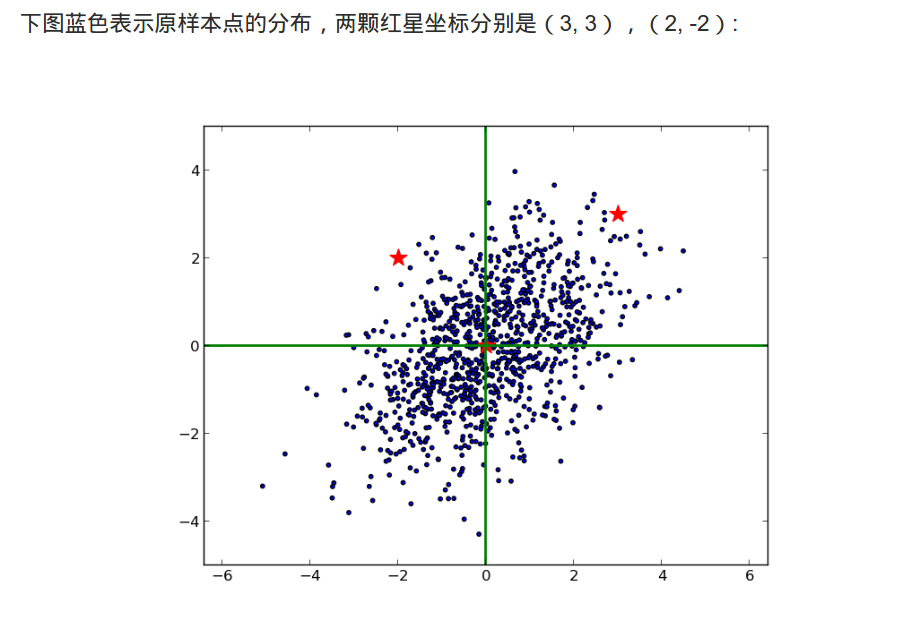
xy方向尺度不同,不能简单求欧氏距离。
由于xy实现相关的,大致斜向上,不能标准化处理:减去均值,除以方差。
最恰当的方法是,进行cholesky变换,求马氏距离。变换后马氏距离空间如下:
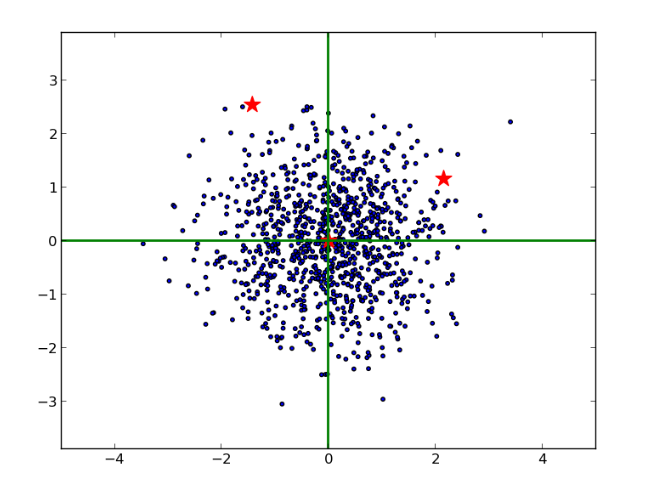
可知,后边的红星离原点更近。与开始直观感觉有偏差。
3、向量内积
常见、有效、直观的相似性测量手段。
向量内积没有剔除向量长度影响,如果计算单位长度向量的内积,就是余弦相似度(Consine similarity),公式如下:
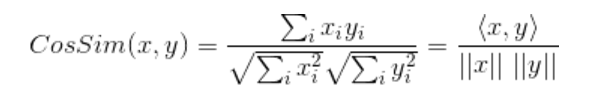
余弦相似度只与向量方向相关,与幅度无关。在TF-IDF及图片相似度计算过程中,经常看到。
不足的是,余弦相似度受向量平移影响,如果x变为x+1,则余弦相似度值会发生变化。
解决此方法就是——皮尔逊相似度(Person correlation),既避免幅度影响,又避免向量平移影响。
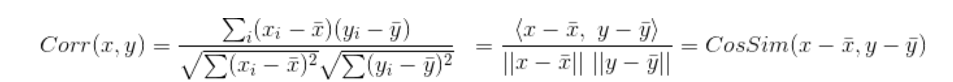
皮尔逊相关系数具有平移不变性和尺寸不变性。
4、分类数据间的距离
汉明距离:两个等长字符串,其中一个变为另一个需要的最小变换次数。
5、概率分布之间的距离
前面讨论的是数值点的距离,实际上概率分布之间的距离也是可以计算的。
常见方法有卡方验证(chi-square)和KL散度(KL-divergence)
小结:
Jaccard计算集合之间的相似度/距离
KL衡量两个分布之间的相似度/距离
Consine计算向量之间的相似度/距离
参考文章
1、http://blog.jobbole.com/84876/
比如KNN近邻的距离,Kmeans距离,相似度中的距离计算。
这种距离不一定都是欧氏距离,针对不同需求,数据的不同特点,距离的计算方式不同。
下面给出机器学习中常用的距离计算方式,及其应用特点。
对于距离,有如下基本特性:
1、d(x, x)=0 //到自己的距离为0
2、d(x ,y)>=0 //距离非负
3、d(x, y)=d(y, x) //距离对称性,A到B的距离,B到A的距离是相等的
4、d(x, z)+d(z, y)>=d(x, y) //三角形法则,两边之和大于第三边
1、闵可夫斯基距离(Minkowski distance)
衡量数值点之间距离的常用方法。公式如下。
该距离最常见形式是P=2或者1,分别对应欧氏距离、曼哈顿距离。
见下图,网格表示城市街区交通道路,直线表示欧式距离,显示情况在存在高楼,不能直接穿过,折线表示曼哈顿距离,其长度是相等的。
但公司中的P趋于无穷大时,闵可夫斯基距离就转化为切比雪夫距离(Chebyshev distance).
我们知道,平面上的距离原点欧氏距离(P=2)为1的点组成的形状为圆,但P取其他值时?见下图。
可知,切比雪夫距离近似一个正方形。
注意:当P<1时,闵可夫斯基距离不符合三角形法则。比如:P<1时,(0,0)(1,1)两点的距离为(1,1)^1/p>2,而(0,1)到这两点的距离都为1.
特点:闵可夫斯基距离比较直观,与数据分布无关,具有一定局限性。比如X方向的幅值远远大于Y方向的值,则闵可夫斯基距离会过度放大X维度的作用。可以在计算距离时,利用Z-transform处理,减去均值,除以方差。
可知,此时处理体现数据的统计特性了,但其假设是,数据之间不是相关的。比如,人的身高跟体重是有相关性的,这样的数据,就需要用马氏距离了。
2、马氏距离(mahalanobis distance)
先看例子,图中黑绿球的欧氏距离>黑红球;相反,黑绿球的马氏距离<黑红球。
这是因为马氏距离考虑了数据之间的相关性,利用cholesky transformation消除了不同维度之间的相关性和尺寸不同。
具体换换公式参考文章1.
举个例子,如图,下面的样本点。
xy方向尺度不同,不能简单求欧氏距离。
由于xy实现相关的,大致斜向上,不能标准化处理:减去均值,除以方差。
最恰当的方法是,进行cholesky变换,求马氏距离。变换后马氏距离空间如下:
可知,后边的红星离原点更近。与开始直观感觉有偏差。
3、向量内积
常见、有效、直观的相似性测量手段。
向量内积没有剔除向量长度影响,如果计算单位长度向量的内积,就是余弦相似度(Consine similarity),公式如下:
余弦相似度只与向量方向相关,与幅度无关。在TF-IDF及图片相似度计算过程中,经常看到。
不足的是,余弦相似度受向量平移影响,如果x变为x+1,则余弦相似度值会发生变化。
解决此方法就是——皮尔逊相似度(Person correlation),既避免幅度影响,又避免向量平移影响。
皮尔逊相关系数具有平移不变性和尺寸不变性。
4、分类数据间的距离
汉明距离:两个等长字符串,其中一个变为另一个需要的最小变换次数。
5、概率分布之间的距离
前面讨论的是数值点的距离,实际上概率分布之间的距离也是可以计算的。
常见方法有卡方验证(chi-square)和KL散度(KL-divergence)
小结:
Jaccard计算集合之间的相似度/距离
KL衡量两个分布之间的相似度/距离
Consine计算向量之间的相似度/距离
参考文章
1、http://blog.jobbole.com/84876/

相关文章推荐
- GPS定位坐标计算距离
- 机器学习中的距离计算
- 机器学习中的各种距离
- MATLAB 距离计算
- MATLAB小贴士(2)
- Matlab中 pdist 函数详解(各种距离的生成)
- PHP,Mysql-根据一个给定经纬度的点,进行附近地点查询
- 通过当前用户的经纬度,查询附近的店铺
- Android 计算地球上任意两点(经纬度)距离
- 百度坐标点计算
- 相似度算法种类
- [聚类一]之距离计算
- 几种距离计算公式在数据挖掘中的应用场景分析
- MachingLearning中的距离和相似性计算以及python实现
- iOS——两地理坐标直接距离的计算
- 碰撞练习
- 通过两个位置的经纬度坐标计算距离(Java版本)
- 机器学习和大数据中运用的距离计算方法
- JAVA计算两个经纬度之间的距离
- 经纬度坐标列表直线(坐标)距离排序