Flask(5)-数据库
2016-05-19 14:03
495 查看
数据库按一定的规则保存数据,程序再发起查询取回所需的数据。
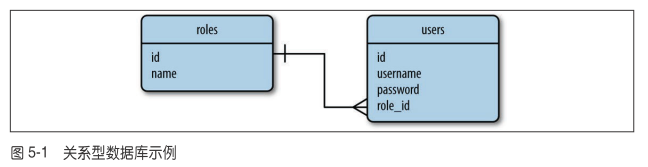
在这个数据库关系图中,roles存储用户可用的角色名,每个角色都使用一个唯一的id值(主键)进行标识。users表包含用户列表,每个用户也有唯一id值,除此以为,表中还有username列,password列,role_id是外键,引用角色的id,通过这种方式为每个用户指定角色。
关系型数据库把数据存储在表中,表模拟程序中不同的实体。
表中列固定,行可变。列定义表所表示的实体的数据数据属性。
表中特殊的列,称为主键,其值为表中各行的唯一标识符。表中还拥有称为外键的列,引用同一个表或不同表中某行的主键。行之间的这种联系称为关系,这是关系型数据库模型的基础。
NoSQL数据库一般使用集合代替表,使用文档代替记录。
在Flask-SQLAlchemy中,数据库用URL指定。程序使用的数据库URL必须保存到Flask配置对象的SQLAHCHEMY_DATABASE_URI键中。另外SQLALCHEMY_COMMIT_ON_TEARDOWN键,将其设为True时,每次请求结束后都会自动提交数据库中的变动。
如下初始化及配置一个SQLite数据库。
hello.py: 配置数据库
db对象是SQLAlchemy类的实例,表示程序使用的数据库,同时还获得了Flask-SQLAlchemy提供的所有功能。
Flask-SQLAlchemy创建的数据库实例为模型提供了一个基类以及一系列辅助类和辅助函数,可用于定义模型的结构。
hello.py: 定义Role和User模型
定义两个模型,Role和User,各自拥有属性id、name和id、username。
db.Column类构造函数的第一个参数是数据库列和模型属性的类型。其余的参数指定属性的配置选项。
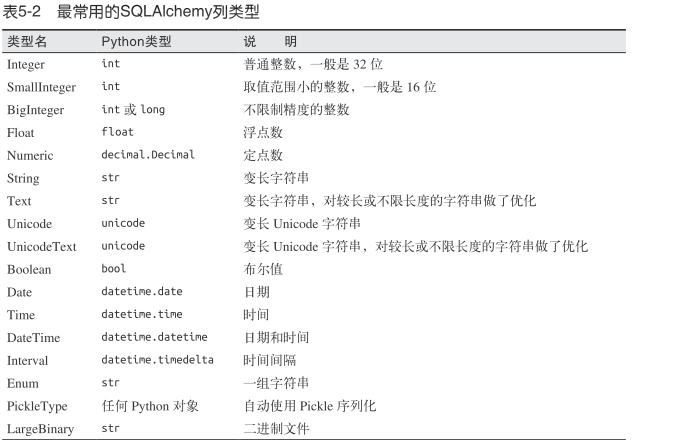

Flask-SQLAlchemy要求每个模型都要定义主键,这一列经常命名为id。
模型又定义了__repr()__方法,返回一个具有可读性的字符串表示模型,可在调试和测试时使用。
一对多关系在模型类中的表示方法如下:
hello.py: 关系
添加到Role模型中的Users属性代表这个关系的面向对象视角。对于一个Role类的实例,其users属性将返回与角色相关联的用户组成的列表(一对多)。db.relationship()的第一个参数表示这个关系的另一端是哪个模型。
db.relationshio()中的backref参数向User模型中添加一个role属性,从而定义反向关系。这一属性可替代role_id访问Role模型,此时获取的是模型对象,而不是外键的值。
传给db.ForeignKey()的参数’roles.id’表明,这列的值是roles表中行的id值。
模型的构造函数接受的参数是使用关键字参数指定的模型属性初始值。role属性也可以使用,尽管它不是真正的数据库列,是一种高级的一对多表示。这些新建对象的id属性并没有明确设定,因为主键是由Flask-SQLAlchemy管理的。
通过数据库会话对数据库做的改动,在Flask-SQLAlchemy中,会话由db.session表示。准备把对象写入数据库之前,先要添加到会话中:
或简写成:
然后调用commit()方法提交会话:
此时这些对象就拥有了id属性。
数据库会话db.session和Flasksession没有关系。数据库会话也成为事务。
数据库会话也可回滚。调用db.session.rollback()后,添加到数据库会话中的所有对象会还原到它们在数据库时的状态。
使用过滤器
若果退出shell会话,前面创建的对象就不会以Python对象的形式出现,而是作为各自数据库表中的行。如果打开一个新的shell会话,就要从数据库读取行,再重新创建Python对象。
如下发起一个查询:

关系和查询的处理方式类似。
SQL数据库
基于关系模型的数据库:SQL数据库在这个数据库关系图中,roles存储用户可用的角色名,每个角色都使用一个唯一的id值(主键)进行标识。users表包含用户列表,每个用户也有唯一id值,除此以为,表中还有username列,password列,role_id是外键,引用角色的id,通过这种方式为每个用户指定角色。
关系型数据库把数据存储在表中,表模拟程序中不同的实体。
表中列固定,行可变。列定义表所表示的实体的数据数据属性。
表中特殊的列,称为主键,其值为表中各行的唯一标识符。表中还拥有称为外键的列,引用同一个表或不同表中某行的主键。行之间的这种联系称为关系,这是关系型数据库模型的基础。
NoSQL数据库
所有不遵循关系模型的数据库称为NoSQL数据库。NoSQL数据库一般使用集合代替表,使用文档代替记录。
使用Flask-SQLAlchemy管理数据库
Flask-SQLAlchemy是一个扩展,简化了在Flask中使用SQLAlchemy的操作。在Flask-SQLAlchemy中,数据库用URL指定。程序使用的数据库URL必须保存到Flask配置对象的SQLAHCHEMY_DATABASE_URI键中。另外SQLALCHEMY_COMMIT_ON_TEARDOWN键,将其设为True时,每次请求结束后都会自动提交数据库中的变动。
如下初始化及配置一个SQLite数据库。
hello.py: 配置数据库
from flask.ext.sqlalchemy import SQLAlchemy basedir = os.path.abspath(os.path.dirname(__file__)) app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI']=\ 'sqlite:///' + os.path.join(basedir, 'data.sqlite') app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True db = SQLAlchemy(app)
db对象是SQLAlchemy类的实例,表示程序使用的数据库,同时还获得了Flask-SQLAlchemy提供的所有功能。
定义模型
模型表示程序使用的持久化实体。在ORM中,模型一般是一个Python类,类中的属性对应数据库表中的列。Flask-SQLAlchemy创建的数据库实例为模型提供了一个基类以及一系列辅助类和辅助函数,可用于定义模型的结构。
hello.py: 定义Role和User模型
class Role(db.Model): __tablename__ = 'roles' #数据库的表名 id = db.Column(db.Integer, primary_key=True) # id属性 name = db.Colum(db.String(64), unique=True) # name属性 def __repr_(self): return '<Role %r>' % self.name class User(db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), unique=True, index=True) def b824 __repr__(self): return '<User %r>' % self.username
定义两个模型,Role和User,各自拥有属性id、name和id、username。
db.Column类构造函数的第一个参数是数据库列和模型属性的类型。其余的参数指定属性的配置选项。
Flask-SQLAlchemy要求每个模型都要定义主键,这一列经常命名为id。
模型又定义了__repr()__方法,返回一个具有可读性的字符串表示模型,可在调试和测试时使用。
关系
关系型数据库使用关系把不同表中的行连接起来。图5.1所示的关系图表示用户和角色之间的一种简单关系,这是角色到用户的一对多关系。一对多关系在模型类中的表示方法如下:
hello.py: 关系
class Role(db.Model):
# ...
users = db.relationship('User', backref='role')
class User(db.Model):
# ...
role.id = db.Column(db.Integer, db.ForeignKey('roles.id')添加到Role模型中的Users属性代表这个关系的面向对象视角。对于一个Role类的实例,其users属性将返回与角色相关联的用户组成的列表(一对多)。db.relationship()的第一个参数表示这个关系的另一端是哪个模型。
db.relationshio()中的backref参数向User模型中添加一个role属性,从而定义反向关系。这一属性可替代role_id访问Role模型,此时获取的是模型对象,而不是外键的值。
传给db.ForeignKey()的参数’roles.id’表明,这列的值是roles表中行的id值。
数据库操作
模型已按照数据库关系完成配置,在Python shell中学习使用模型。创建表
(venv)PS python hello.py shell >>> from hello import db >>> db.create_all()
插入行
>>> from hello import Role, User >>> admin_role = Role(name='Admin') >>> mod_role = Role(name='Moderator') >>> user_role = Role(name='User') >>> user_john = User(username='john', role=admin_role) >>> user_susan = User(username='susan', role=user_role) >>> user_david = User(username='david', role=user_role)
模型的构造函数接受的参数是使用关键字参数指定的模型属性初始值。role属性也可以使用,尽管它不是真正的数据库列,是一种高级的一对多表示。这些新建对象的id属性并没有明确设定,因为主键是由Flask-SQLAlchemy管理的。
通过数据库会话对数据库做的改动,在Flask-SQLAlchemy中,会话由db.session表示。准备把对象写入数据库之前,先要添加到会话中:
>>> db.session.add(admin_role) >>> db.session.add(mod_role) >>> db.session.add(user_role) >>> db.session.add(user_john) >>> db.session.add(user_susan) >>> db.session.add(user_david)
或简写成:
>>> db.session.add_all([admin_role, mod_role, user_role, user_john, user_susan, user_david])
然后调用commit()方法提交会话:
db.session.commit()
此时这些对象就拥有了id属性。
数据库会话db.session和Flasksession没有关系。数据库会话也成为事务。
数据库会话也可回滚。调用db.session.rollback()后,添加到数据库会话中的所有对象会还原到它们在数据库时的状态。
修改行
在会话中更改模型:>>> admin_role.name = 'Administrator' >>> db.session.add(admin_role) >>> db.session.commit()
删除行
db.session.delete(mod_role) db.session.commit()
查询行
最基本查询——取回所有记录>>> Role.quwry.all() [<Role u'Administrator'>, <Role u'User'>] >>> User.query.all() [<Role u'Administrator'>, <Role u'User'>]
使用过滤器
>>> User.query.filter_by(role=user_role).all() >[<User u'susan'>, <User u'david'>]
若果退出shell会话,前面创建的对象就不会以Python对象的形式出现,而是作为各自数据库表中的行。如果打开一个新的shell会话,就要从数据库读取行,再重新创建Python对象。
如下发起一个查询:
>>> user_role = Role.query.filter_by(name='User').first()
关系和查询的处理方式类似。

相关文章推荐
- ubuntu12.04安装mysql-connector-c-6.1.6和mysql-connector-cpp-1.1.6
- PHP Memcache函数详解
- 求一篇关于nosql,mongodb数据库的外文资料加翻译
- plsql,为什么plsql的database下拉为空??要设置TNS_ADMIN环境变量
- mysql存储引擎测试
- mysql max_connection config
- SQL Server 连接字符串和身份验证详解
- Mysql高级SQL语句
- go sql
- PostgreSQL学习手册(函数和操作符<一>)
- ubuntu postgresql的安装与配置
- mysqldump
- mysql 提高mysql查询速度
- sqlite3交叉编译
- mysql message from server: "Too many connections
- 数据库 coreData 入门(转)
- php扩展redis
- Oracle控制文件
- debian 64 安装mysql++
- mysql导入导出包括函数或者存储过程