kafka与streaming集成两种方式
2016-05-18 10:57
471 查看
hadoop,spark,kafka交流群:224209501
标签(空格分隔): spark简介
Apache Kafka是分布式发布-订阅消息系统。它最初由Linkedln公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展、设计内在就是分布式的,分区的和可复制的提交日志服务。Apache Kafka与传统消息系统相比有以下不同:
它被设计为一个分布式系统,易于向外扩展
他同时为发布和订阅提供高吞吐量
它支持多订阅者,当失败时能自动平衡消费者;
它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
kafka架构
生产者(Producer)是能够发布消息到话题的任何对象。
已发布的消息保存在一组服务器中,他们被称为代理(Broker)或者Kafka集群
消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
话题(Topic)是特定类型的消息流。消息是字节的有效负载Payload),话题是消息的分类或者种子(feed)名。
kafka集群模式单集群
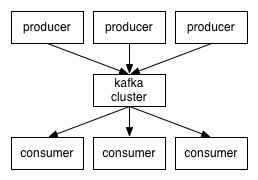
详细的kafka结构图
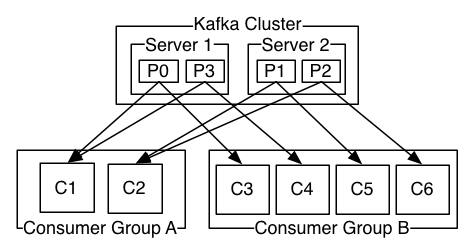
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
1,配置kafka
1,produce.properties
metadata.broker.list=miaodonghua.host:9092
2,server.properties
host.name=miaodonghua.host log.dirs=/opt/cdh5.3.6/kafka_2.10-0.8.2.1/kafka-logs zookeeper.connect=miaodonghua.host:2181
3,使用kafka
bin/kafka-server-start.sh config/server.properties
1) 创建 Topic
bin/kafka-topics.sh --create --zookeeper miaodonghua.host:2181 --replication-factor 1 --partitions 1 --topic test
查看topic
bin/kafka-topics.sh --list --zookeeper miaodonghua.host:2181
2) 发布信息到Topic
bin/kafka-console-producer.sh --broker-list miaodonghua.host:9092 --topic ucloudSafe
3) 订阅者订阅消息
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
2,Receiver-based Approach
1,启动spark-shell
bin/spark-shell \ --jars /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/spark-streaming-kafka_2.10-1.5.2.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/kafka_2.10-0.8.2.2.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/kafka-clients-0.8.2.2.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/metrics-core-2.2.0.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/zkclient-0.3.jar \ --master local[2]
2,编写kafkaWordCount.scala
Approach 1: Receiver-based Approachimport org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
val ssc = new StreamingContext(sc, Seconds(5))
val topicMap = Map("test" -> 1)
val lines = KafkaUtils.createStream(ssc, "miaodonghua.host:2181", "testWordCountGroup", topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val counts = words.map((_, 1L)).reduceByKey(_ + _)
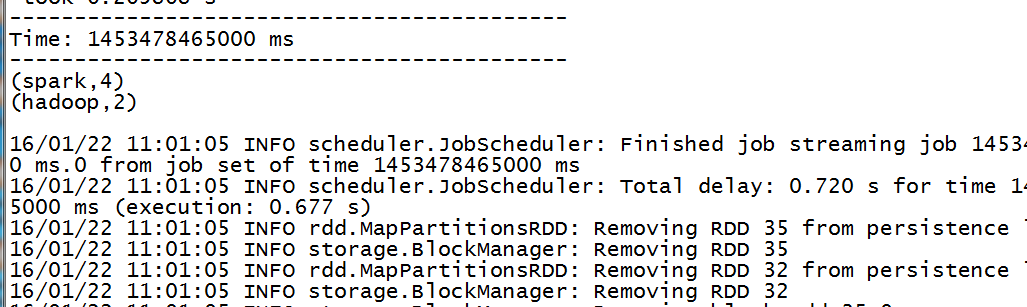
counts.print()
ssc.start()
ssc.awaitTermination()3,执行脚本
:load /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/kakaWordCount.scala
3,Direct Approach
1,启动spark-shell
bin/spark-shell \ --jars /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/spark-streaming-kafka_2.10-1.3.0.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/kafka_2.10-0.8.2.1.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/kafka-clients-0.8.2.1.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/metrics-core-2.2.0.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/zkclient-0.3.jar \ --master local[2]
2,编写kafkaWordCount2.scala
Approach 2: (No Receivers)import kafka.serializer.StringDecoder
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
val ssc = new StreamingContext(sc, Seconds(5))
val kafkaMapParams = Map("metadata.broker.list" -> "miaodonghua.host:9092")
val topicsSet = Set("test")
val lines = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaMapParams, topicsSet).map(_._2)
val words = lines.flatMap(_.split(" "))
val counts = words.map((_, 1L)).reduceByKey(_ + _)
counts.print()
ssc.start()
ssc.awaitTermination()3,执行脚本
:load /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/kakaWordCount2.scala
![kafka接受数据2.png-29.3kB][9]
4,UpdateStateByKey
1,启动spark-shell
bin/spark-shell \ --jars /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/spark-streaming-kafka_2.10-1.3.0.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/kafka_2.10-0.8.2.1.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/kafka-clients-0.8.2.1.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/metrics-core-2.2.0.jar,\ /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externaljars/zkclient-0.3.jar \ --master local[2]
2,UpdateStateByKey
import kafka.serializer.StringDecoder
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint(".")
val kafkaMapParams = Map("metadata.broker.list" -> "miaodonghua.host:9092")
val topicsSet = Set("test")
// Option[S]
val updateFunc =(values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
val lines = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaMapParams, topicsSet).map(_._2)
val words = lines.flatMap(_.split(" "))
val counts = words.map((_, 1)) // (hello,list(1,2,3,4,5)) (spark,1)
// updateStateByKey
val state = counts.updateStateByKey[Int](updateFunc)
state.print()
ssc.start()
ssc.awaitTermination()3,执行脚本
:load /opt/cdh5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/UpdateStateByKey.scala

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- Kafka 之 中级
- Spark随谈——开发指南(译)
- 分布式版本管理git入门指南使用资料汇总及文章推荐
- 单机版搭建Hadoop环境图文教程详解
- Spark,一种快速数据分析替代方案
- C#分布式事务的超时处理实例分析
- Erlang分布式节点中的注册进程使用实例
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- C++实现的分布式游戏服务端引擎KBEngine详解
- Linux下Kafka单机安装配置方法(图文)
- ASP.NET通过分布式Session提升性能
- Apache Hadoop版本详解