GPDB的数据倾斜问题
2016-05-18 10:20
288 查看
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/jameswangcnbj/article/details/51441718
DB运行了一段时间后,数据发生了变化,在不同节点的数据分布会发生问题,有的节点分配的数据较多有的较少,这样在查询的时候会导致性能的降低,我们常规的查询手段是通过
Select gp_segment_id,count(*) from tablename group by 1 ;
但是如果库中的表比较多,这样查询很费事,有人编写了函数,拿来主义
CREATE OR REPLACE FUNCTION public.fn_get_skew(out schema_name varchar,
out table_name varchar,
out pTableName varchar,
out total_size_GB numeric(15,2),
out seg_min_size_GB numeric(15,2),
out seg_max_size_GB numeric(15,2),
out seg_avg_size_GB numeric(15,2),
out seg_gap_min_max_percent numeric(6,2),
out seg_gap_min_max_GB numeric(15,2),
out nb_empty_seg int) RETURNS SETOF record AS
$$
DECLARE
v_function_name text := 'fn_get_skew';
v_location int;
v_sql text;
v_db_oid text;
v_num_segments numeric;
v_skew_amount numeric;
v_res record;
BEGIN
v_location := 1000;
SELECT oid INTO v_db_oid
FROM pg_database
WHERE datname = current_database();
v_location := 2200;
v_sql := 'DROP EXTERNAL TABLE IF EXISTS public.db_files_ext';
v_location := 2300;
EXECUTE v_sql;
v_location := 3000;
v_sql := 'CREATE EXTERNAL WEB TABLE public.db_files_ext ' ||
'(segment_id int, relfilenode text, filename text, ' ||
'size numeric) ' ||
'execute E''ls -l $GP_SEG_DATADIR/base/' || v_db_oid ||
' | ' ||
'grep gpadmin | ' ||
E'awk {''''print ENVIRON["GP_SEGMENT_ID"] "\\t" $9 "\\t" ' ||
'ENVIRON["GP_SEG_DATADIR"] "/' || v_db_oid ||
E'/" $9 "\\t" $5''''}'' on all ' || 'format ''text''';
v_location := 3100;
EXECUTE v_sql;
v_location := 4000;
for v_res in (
select sub.vschema_name,
sub.vtable_name,
(sum(sub.size)/(1024^3))::numeric(15,2) AS vtotal_size_GB,
--Size on segments
(min(sub.size)/(1024^3))::numeric(15,2) as vseg_min_size_GB,
(max(sub.size)/(1024^3))::numeric(15,2) as vseg_max_size_GB,
(avg(sub.size)/(1024^3))::numeric(15,2) as vseg_avg_size_GB,
--Percentage of gap between smaller segment and bigger segment
(100*(max(sub.size) - min(sub.size))/greatest(max(sub.size),1))::numeric(6,2) as vseg_gap_min_max_percent,
((max(sub.size) - min(sub.size))/(1024^3))::numeric(15,2) as vseg_gap_min_max_GB,
count(sub.size) filter (where sub.size = 0) as vnb_empty_seg
from (
SELECT n.nspname AS vschema_name,
c.relname AS vtable_name,
db.segment_id,
sum(db.size) AS size
FROM ONLY public.db_files_ext db
JOIN pg_class c ON split_part(db.relfilenode, '.'::text, 1) = c.relfilenode::text
JOIN pg_namespace n ON c.relnamespace = n.oid
WHERE c.relkind = 'r'::"char"
and n.nspname not in ('pg_catalog','information_schema','gp_toolkit')
and not n.nspname like 'pg_temp%'
GROUP BY n.nspname, c.relname, db.segment_id
) sub
group by 1,2
--Extract only table bigger than 1 GB
-- and with a skew greater than 20%
/*having sum(sub.size)/(1024^3) > 1
and (100*(max(sub.size) - min(sub.size))/greatest(max(sub.size),1))::numeric(6,2) > 20
order by 1,2,3
limit 100*/ ) loop
schema_name = v_res.vschema_name;
table_name = v_res.vtable_name;
total_size_GB = v_res.vtotal_size_GB;
seg_min_size_GB = v_res.vseg_min_size_GB;
seg_max_size_GB = v_res.vseg_max_size_GB;
seg_avg_size_GB = v_res.vseg_avg_size_GB;
seg_gap_min_max_percent = v_res.vseg_gap_min_max_percent;
seg_gap_min_max_GB = v_res.vseg_gap_min_max_GB;
nb_empty_seg = v_res.vnb_empty_seg;
return next;
end loop;
v_location := 4100;
v_sql := 'DROP EXTERNAL TABLE IF EXISTS public.db_files_ext';
v_location := 4200;
EXECUTE v_sql;
return;
EXCEPTION
WHEN OTHERS THEN
RAISE EXCEPTION '(%:%:%)', v_function_name, v_location, sqlerrm;
END;
$$
language plpgsql;
执行方式:
select * from public.fn_get_skew();
通过查询我们可以发现
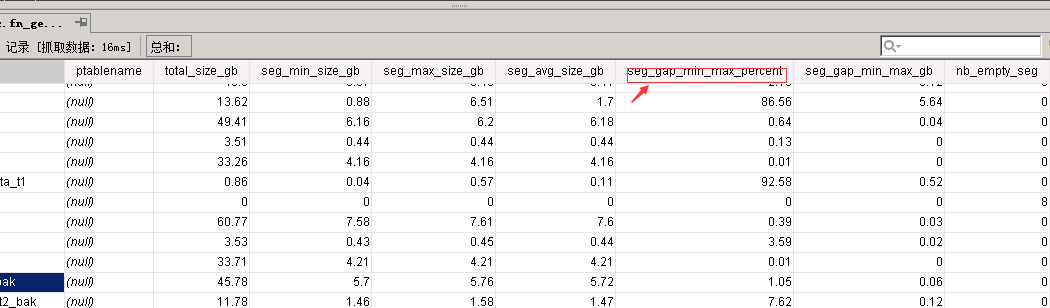
如果gap数据过大,我们就需要调整分布键来调整分布情况。

相关文章推荐
- spark数据倾斜问题
- Hive数据倾斜问题
- hive数据倾斜问题
- CityBuilder导入倾斜数据OSGB,生成3DML常见问题解决
- HIVE数据倾斜问题
- spark的数据倾斜问题的解决
- hive 数据倾斜实际问题中总结
- 大数据常见问题之数据倾斜
- hive数据倾斜问题
- 自定义分区随机分配解决数据倾斜的问题
- 解决spark中遇到的数据倾斜问题
- hive数据倾斜问题
- HiveQL中如何排查数据倾斜问题
- 【Kafka】Kafka-数据倾斜问题-参考资料-解决方案
- 数据倾斜问题简单几句话
- hive调优 数据倾斜问题
- hive数据倾斜问题
- spark 通过打散热点key解决数据倾斜问题
- 数据倾斜问题和滑动窗口uv统计问题
- hive数据倾斜问题