大话网站分布式架构
2016-05-17 12:53
344 查看
这里是自己的个人经验,有不对或者需要补充的地方,欢迎评论,一起完善技术结构,后续会写一下各个层已经组件的详细功能和配置使用方式, 请多关注;
分布式一般主要是处理大访问量,通过把请求分发到多台机器或者服务来提升访问速度和访问量下面是现在多数服务器的配置

我们从下往上说:
代码层,这里一般都用过一些架构进行配置,可以配置最大连接数、文件上传大小、用户登录信息保留时间等等,另外就架构本身会涉及到一些设计模式,对象创建、保存,代码业务逻辑的优化。这些都会影响到程序处理请求的速度和并发量。
如果请求很慢,而且很明显熟读卡在这个地方了,可以考虑优化代码,当然如果是数据库压力过大,那就要对数据库进行分布式等方式的优化,这里暂时不进行详细接受,后续会对数据库分布式进行讲解。
容器层:比较常用的有tomcat,jetty等,他们是代码运行的容器,拿tomcat举例说明,tomcat就请求的量来说可以配置最大线程数,每一个线程可以处理一个请求,
线程数对于tomcat处理最大请求的数量是至关重要的一个配置,当然线程配置的很大也是不可能的也是不现实的,虽然它本身没有限制最大线程数,但是它受到硬件、操作系统,容器版本的限制,具体的情况要根据情况而定
容器应该也有一个最大等待队列数,对请求的最大数也是有影响的。
每一个线程都要占用一定内存的,所以容器相关的内存也需要进行配置,一适应你配置的线程,
tomcat默认可以使用的内存为128MB,在较大型的应用项目中,这点内存是不够的,需要调大。
Unix下,在文件{tomcat_home}/bin/catalina.sh的前面,增加如下设置:
JAVA_OPTS='-Xms【初始化内存大小】 -Xmx【可以使用的最大内存】'
需要把这个两个参数值调大。例如:
JAVA_OPTS='-Xms256m -Xmx512m'
表示初始化内存为256MB,可以使用的最大内存为512MB
代理层:
代理服务器已经是很常用的服务器了,nginx就挺好用的,请求来的时候,由代理服务器进行分析匹配,分发到各个容器服务器,当容器服务器压力大的时候可以考虑多配几台容器服务器到代理服务器下,通过匹配,均衡等方式交由多个容器进行处理。
使用代理的方式,请求数一般情况下都是代理服务器接受到的请求数交多,可能会出现请求数超过机器所允许的最大连接数,特别是被恶意攻击的时候,
可以调节下面的两个参数
/proc/sys/net/netfilter/nf_conntrack_max
/sys/module/nf_conntrack/parameters/hashsize
个人用过的配置:
echo 262144 > /sys/module/nf_conntrack/parameters/hashsize
echo 1048576 > /proc/sys/net/netfilter/nf_conntrack_max
代理层有调节的话最好放在一台机器上,这样方便检查和调整配置。
代理层一般不做业务逻辑,所以内存不用很大,相反,容器层对内存有一定的要求,一台机器一般会放对个容器服务器
由上可以看到,容器层需要注意内存和线程,而代理层对请求数需要特别注意,
这里提一下,遇到恶意攻击,可以在代理层做一些拦截,一般代理服务器都有这样的功能可以用
nginx:
1. ngx_http_limit_conn_module 可以用来限制单个IP的连接数
2. ngx_http_limit_req_module 可以用来限制单个IP每秒请求数 3. nginx_limit_speed_module 可以用来对IP限速
具体配置可以看专门的网站配置nginx 还可以拦截屏蔽一些爬虫请求
路由层:如果是小公司,路由层一般不需要考虑,对于现在很多都是用云服务,所有也不用考虑了,路由器也是可以编辑设置的,毕竟也是计算机的一种,大致了解到了有路由选择协议之类的东西,暂时不深究这里了。DNS: 忽略路由层,如果一台nginx 的连接数已经超过100w甚至更多,那么可以选择通过DNS进行分发请求到不同的nginx(nginx 独自一台服务),这些可以在运营服务商后台进行操作,但是可能是要钱的不便宜,话说回来,你有几百万上千万的并发访问量,还会缺钱吗,哈哈。
服务器架构配置 ===============================================
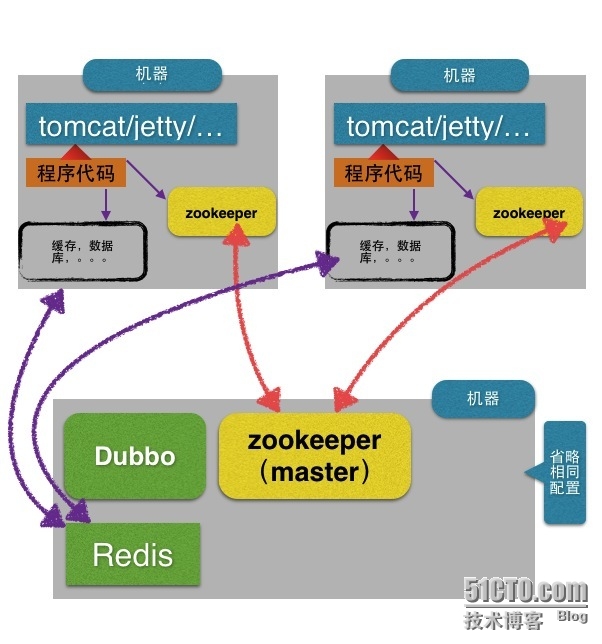
本文主要讲的服务器架构,项目架构这里不细说,
项目中比较常用的服务: 缓存服务,一致性服务,数据库服务,远程服务, 下面我们一个个的讲解,不一定完整,后期进行补充解说
缓存服务:使用量最大的三种 redis、memcache、mongoDB
网上也看到了一些他们的对比http://blog.csdn.net/tea_wu/article/details/19050277
性能都很高
这里简单说一下,redis 的单点问题也得到了部分解决,官方出了redis-cluster
100w的访问速度应该对redis来说不是问题,再高就卡在网卡上面了,当然连接数也可能是问题,这两点是配置上需要检查的。特别注意,程序也不要过长时间只有redis连接。
具体的坑还要自己踩一下的,少不了
一致性服务: 简单的一致性redis也可以代替实现,但是在一致性方面,redis可以实现的程度有限,
这里有比较专业的一致性服务,zookeeper,它可以动态的跟新数据,同时所有的zookeeper节点都可以
监听到数据的变动,可以出发一致性的一些操作,当然真的一致性还是zookeeper存储的数据的一致。
在项目数据一致性,服务器集群部署等方面,zookeeper使用很方便。
数据库服务:数据库服务对于网站的访问量往往也是一个瓶颈,如果不是像阿里,京东这样的大网站,那么,主从+分库分表应该可以应对大数据的访问了
处理大数据的优化点:程序减少时间较长的数据库操作,避免复杂的联合查询。
缓存优化:对一些及时性要求不是很高的数据,添加缓存,避免不必要的大数据访问,这样可以优化相当大是数据库访问问题。
如果数据访问请求的领已经很高了,那么可以对数据库进行主从集群,主进行数据跟新操作,从进行查询操作,这个以优化可以提升数据库访问量很多倍了,毕竟数据库还是查询多一些,而且从库可以添加 多台。说到这里,数据的更新如果不是及时性的要求,例如人员 访问记录等,可以先放入缓存服务,然后在清理到数据库中去。
如果一个服务器的数据项很多,数据之间有的没有很紧的关系,那么可以考虑把不同的数据放到不同的数据库中,这叫做分库,当然,这样你的数据结构设计的时候最好就考虑到这里。
数据库的表的长度是有限的,当数据达到一定量的时候,对表结构也需要拆分,把原来一个表的数据,按照某种规则放入不同的数据表中。
远程调用: 对于分布式远程调用也是必不可少的一个组件,以实现跨服务的逻辑一致性,也算是代码复用的一部分吧,现有的框架中,阿狸的dubbo算是挺不错的。他的架构如下图所示:
Dubbo 架构如下图:
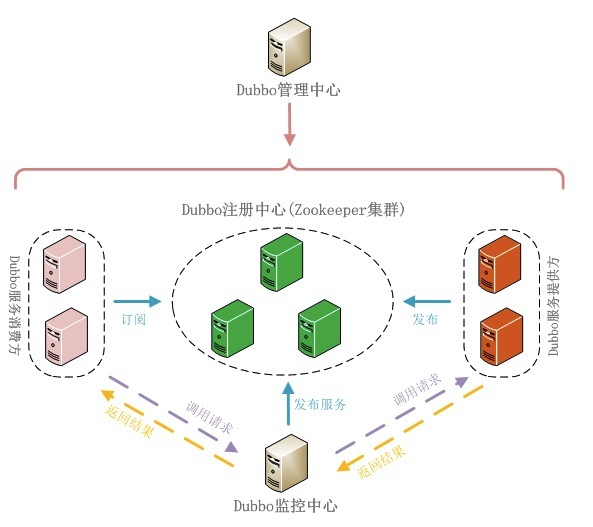
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
此时,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键。
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
此时,用于提高机器利用率的 资源调度和治理中心(SOA) 是关键
以上 这些Dubbo 都可以给予很好的解决,
图文说明:
RPC功能 部分:
抽离出来的公用的服务,向注册中心进行注册,注册信息中含有提供哪些服务的说明;
服务消费者或者说调用服务者,像注册中心订阅需要的服务;注册中心充注册的服务中找到合适的推送给服务消费者,如果注册中心使用的是zookeeper 那么基于一致性特性,提供方有任何变动都能及时的推送给相关的 消费者。
SOA功能部分:
Dubbo有监控中心,记录分析消费者和服务提供者的性能情况,同时把这些信息发送给这两者,
服务消费者根据监控中心的数据选择要调用的服务,也根据监控得到的数据分析两者的性能点问题,
开发人员有针对性的优化提升服务。
具体的Dubbo 的使用会有专门的博文进行描述。
数据存储服务配置:====================================
现在的很多数据库本身其实已经有很强的负载能力,对于一般的中型网站,在项目代码架构合理的情况下,完全可以支撑,当量级进一步提高,那么就要通过其他方式提升性能了,
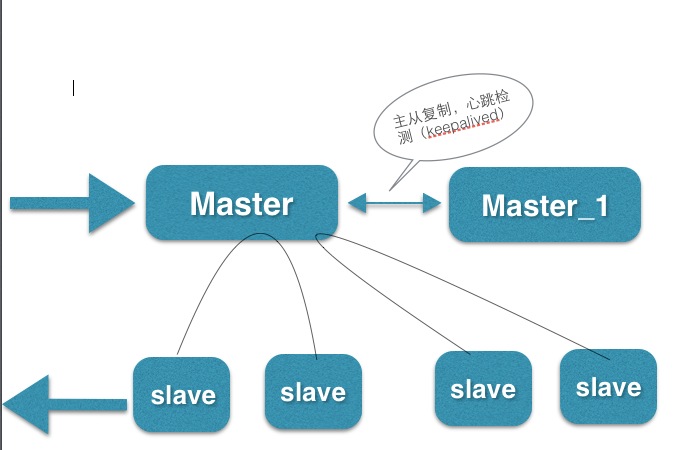
提升1:从集群方面优化 提升
数据库的访问大多数是数据的查询,可以采用主从的方式,从库备份主库数据,优化性能,master数据库主要处理数据更新的访问,slave主要处理数据查询的访问,可以方便的添加slave大幅度的提升访问速度,为了防止单点问题,master配置充主主互备份,其中master挂掉,直接切换到 master_1, keeaplived做,所有的从库都从master_1复制,有1~3秒的延时处理这个情况。
一般性能的数据库分布式集群配置如下图
提升2:从单机方面进行优化设计
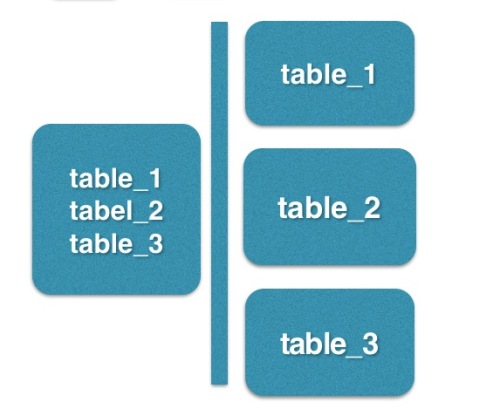
单机优化可以在纵向和横向进行优化 主要是进行分库分表的方案;
纵向:系统的业务逻辑和数据结构设计的相对独立,可以把不同个业务数据放到多个数据库中,不同的业务逻辑到不同的库中进行处理,这样单个库的压力就减小了;如下图:
横向:数据表中数据量很大的时候单表查询会很慢,另外一张表中的数据存储量是有限的,因此可以把数据原来一张表中的数据放到多张表中存储,单张表的操作速度就提高了;如下图:

数据存储层做这个级别调整好的话,除了淘宝,京东,电信这样的不保证可以很好的支持,其他国内的网站应该没什么问题了。作为架构师来说这方面已经是牛叉的了
一般的数据库分库分表集群的方案
keepalived(集群高HA解决方案)+mycat/sjdbc(分库分表的解决方案)
项目整体架构简略说明就到这里,有不同的见解和补充欢迎评述。
分布式一般主要是处理大访问量,通过把请求分发到多台机器或者服务来提升访问速度和访问量下面是现在多数服务器的配置
我们从下往上说:
代码层,这里一般都用过一些架构进行配置,可以配置最大连接数、文件上传大小、用户登录信息保留时间等等,另外就架构本身会涉及到一些设计模式,对象创建、保存,代码业务逻辑的优化。这些都会影响到程序处理请求的速度和并发量。
如果请求很慢,而且很明显熟读卡在这个地方了,可以考虑优化代码,当然如果是数据库压力过大,那就要对数据库进行分布式等方式的优化,这里暂时不进行详细接受,后续会对数据库分布式进行讲解。
容器层:比较常用的有tomcat,jetty等,他们是代码运行的容器,拿tomcat举例说明,tomcat就请求的量来说可以配置最大线程数,每一个线程可以处理一个请求,
<Connector port="8080" maxThreads="150" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" redirectPort="8443" acceptCount="100" debug="0" connectionTimeout="20000" disableUploadTimeout="true" />
线程数对于tomcat处理最大请求的数量是至关重要的一个配置,当然线程配置的很大也是不可能的也是不现实的,虽然它本身没有限制最大线程数,但是它受到硬件、操作系统,容器版本的限制,具体的情况要根据情况而定
容器应该也有一个最大等待队列数,对请求的最大数也是有影响的。
每一个线程都要占用一定内存的,所以容器相关的内存也需要进行配置,一适应你配置的线程,
tomcat默认可以使用的内存为128MB,在较大型的应用项目中,这点内存是不够的,需要调大。
Unix下,在文件{tomcat_home}/bin/catalina.sh的前面,增加如下设置:
JAVA_OPTS='-Xms【初始化内存大小】 -Xmx【可以使用的最大内存】'
需要把这个两个参数值调大。例如:
JAVA_OPTS='-Xms256m -Xmx512m'
表示初始化内存为256MB,可以使用的最大内存为512MB
代理层:
代理服务器已经是很常用的服务器了,nginx就挺好用的,请求来的时候,由代理服务器进行分析匹配,分发到各个容器服务器,当容器服务器压力大的时候可以考虑多配几台容器服务器到代理服务器下,通过匹配,均衡等方式交由多个容器进行处理。
使用代理的方式,请求数一般情况下都是代理服务器接受到的请求数交多,可能会出现请求数超过机器所允许的最大连接数,特别是被恶意攻击的时候,
可以调节下面的两个参数
/proc/sys/net/netfilter/nf_conntrack_max
/sys/module/nf_conntrack/parameters/hashsize
个人用过的配置:
echo 262144 > /sys/module/nf_conntrack/parameters/hashsize
echo 1048576 > /proc/sys/net/netfilter/nf_conntrack_max
Linux下高并发socket最大连接数
事列:
第一步,修改/etc/security/limits.conf文件,在文件中添加如下行:
speng soft nofile 10240 speng hard nofile 10240 其中speng指定了要修改哪个用户的打开文件数限制,可用'*'号表示修改所有用户的限制; soft或hard指定要修改软限制还是硬限制;10240则指定了想要修改的新的限制值,即最大打开文件数(请注意软限制值要小于或等于硬限制)。修改完后保存文件。 第二步,修改/etc/pam.d/login文件,在文件中添加如下行: session required /lib/security/pam_limits.so 这是告诉Linux在用户完成系统登录后,应该调用pam_limits.so模块来设置系统对该用户可使用的各种资源数量的最大限制(包括用户可打开的最大文件数限制),而pam_limits.so模块就会从/etc/security/limits.conf文件中读取配置来设置这些限制值。修改完后保存此文件。 第三步,查看Linux系统级的最大打开文件数限制,使用如下命令: [speng@as4 ~]$ cat /proc/sys/fs/file-max 12158nignx socket 请求的配置也要加一些东西代理层有调节的话最好放在一台机器上,这样方便检查和调整配置。
代理层一般不做业务逻辑,所以内存不用很大,相反,容器层对内存有一定的要求,一台机器一般会放对个容器服务器
由上可以看到,容器层需要注意内存和线程,而代理层对请求数需要特别注意,
这里提一下,遇到恶意攻击,可以在代理层做一些拦截,一般代理服务器都有这样的功能可以用
nginx:
1. ngx_http_limit_conn_module 可以用来限制单个IP的连接数
2. ngx_http_limit_req_module 可以用来限制单个IP每秒请求数 3. nginx_limit_speed_module 可以用来对IP限速
具体配置可以看专门的网站配置nginx 还可以拦截屏蔽一些爬虫请求
路由层:如果是小公司,路由层一般不需要考虑,对于现在很多都是用云服务,所有也不用考虑了,路由器也是可以编辑设置的,毕竟也是计算机的一种,大致了解到了有路由选择协议之类的东西,暂时不深究这里了。DNS: 忽略路由层,如果一台nginx 的连接数已经超过100w甚至更多,那么可以选择通过DNS进行分发请求到不同的nginx(nginx 独自一台服务),这些可以在运营服务商后台进行操作,但是可能是要钱的不便宜,话说回来,你有几百万上千万的并发访问量,还会缺钱吗,哈哈。
服务器架构配置 ===============================================
本文主要讲的服务器架构,项目架构这里不细说,
项目中比较常用的服务: 缓存服务,一致性服务,数据库服务,远程服务, 下面我们一个个的讲解,不一定完整,后期进行补充解说
缓存服务:使用量最大的三种 redis、memcache、mongoDB
网上也看到了一些他们的对比http://blog.csdn.net/tea_wu/article/details/19050277
性能都很高
这里简单说一下,redis 的单点问题也得到了部分解决,官方出了redis-cluster
100w的访问速度应该对redis来说不是问题,再高就卡在网卡上面了,当然连接数也可能是问题,这两点是配置上需要检查的。特别注意,程序也不要过长时间只有redis连接。
具体的坑还要自己踩一下的,少不了
一致性服务: 简单的一致性redis也可以代替实现,但是在一致性方面,redis可以实现的程度有限,
这里有比较专业的一致性服务,zookeeper,它可以动态的跟新数据,同时所有的zookeeper节点都可以
监听到数据的变动,可以出发一致性的一些操作,当然真的一致性还是zookeeper存储的数据的一致。
在项目数据一致性,服务器集群部署等方面,zookeeper使用很方便。
数据库服务:数据库服务对于网站的访问量往往也是一个瓶颈,如果不是像阿里,京东这样的大网站,那么,主从+分库分表应该可以应对大数据的访问了
处理大数据的优化点:程序减少时间较长的数据库操作,避免复杂的联合查询。
缓存优化:对一些及时性要求不是很高的数据,添加缓存,避免不必要的大数据访问,这样可以优化相当大是数据库访问问题。
如果数据访问请求的领已经很高了,那么可以对数据库进行主从集群,主进行数据跟新操作,从进行查询操作,这个以优化可以提升数据库访问量很多倍了,毕竟数据库还是查询多一些,而且从库可以添加 多台。说到这里,数据的更新如果不是及时性的要求,例如人员 访问记录等,可以先放入缓存服务,然后在清理到数据库中去。
如果一个服务器的数据项很多,数据之间有的没有很紧的关系,那么可以考虑把不同的数据放到不同的数据库中,这叫做分库,当然,这样你的数据结构设计的时候最好就考虑到这里。
数据库的表的长度是有限的,当数据达到一定量的时候,对表结构也需要拆分,把原来一个表的数据,按照某种规则放入不同的数据表中。
远程调用: 对于分布式远程调用也是必不可少的一个组件,以实现跨服务的逻辑一致性,也算是代码复用的一部分吧,现有的框架中,阿狸的dubbo算是挺不错的。他的架构如下图所示:
Dubbo 架构如下图:
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
此时,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键。
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
此时,用于提高机器利用率的 资源调度和治理中心(SOA) 是关键
以上 这些Dubbo 都可以给予很好的解决,
图文说明:
RPC功能 部分:
抽离出来的公用的服务,向注册中心进行注册,注册信息中含有提供哪些服务的说明;
服务消费者或者说调用服务者,像注册中心订阅需要的服务;注册中心充注册的服务中找到合适的推送给服务消费者,如果注册中心使用的是zookeeper 那么基于一致性特性,提供方有任何变动都能及时的推送给相关的 消费者。
SOA功能部分:
Dubbo有监控中心,记录分析消费者和服务提供者的性能情况,同时把这些信息发送给这两者,
服务消费者根据监控中心的数据选择要调用的服务,也根据监控得到的数据分析两者的性能点问题,
开发人员有针对性的优化提升服务。
具体的Dubbo 的使用会有专门的博文进行描述。
数据存储服务配置:====================================
现在的很多数据库本身其实已经有很强的负载能力,对于一般的中型网站,在项目代码架构合理的情况下,完全可以支撑,当量级进一步提高,那么就要通过其他方式提升性能了,
提升1:从集群方面优化 提升
数据库的访问大多数是数据的查询,可以采用主从的方式,从库备份主库数据,优化性能,master数据库主要处理数据更新的访问,slave主要处理数据查询的访问,可以方便的添加slave大幅度的提升访问速度,为了防止单点问题,master配置充主主互备份,其中master挂掉,直接切换到 master_1, keeaplived做,所有的从库都从master_1复制,有1~3秒的延时处理这个情况。
一般性能的数据库分布式集群配置如下图
提升2:从单机方面进行优化设计
单机优化可以在纵向和横向进行优化 主要是进行分库分表的方案;
纵向:系统的业务逻辑和数据结构设计的相对独立,可以把不同个业务数据放到多个数据库中,不同的业务逻辑到不同的库中进行处理,这样单个库的压力就减小了;如下图:
横向:数据表中数据量很大的时候单表查询会很慢,另外一张表中的数据存储量是有限的,因此可以把数据原来一张表中的数据放到多张表中存储,单张表的操作速度就提高了;如下图:
数据存储层做这个级别调整好的话,除了淘宝,京东,电信这样的不保证可以很好的支持,其他国内的网站应该没什么问题了。作为架构师来说这方面已经是牛叉的了
一般的数据库分库分表集群的方案
keepalived(集群高HA解决方案)+mycat/sjdbc(分库分表的解决方案)
项目整体架构简略说明就到这里,有不同的见解和补充欢迎评述。

相关文章推荐
- 如何在 Ubuntu 和其他 Linux 发行版中启动、停止和重启服务
- linux
- 架构纵横谈之二 ---- 架构的模式与要点
- 一步一步跟我学易语言之第二个易程序菜单设计
- 安全帐户管理器初始化失败:目录服务无法启动,错误状态 0xc00002e1 lsass.exe
- BS项目中的CSS架构_仅加载自己需要的CSS
- 将批处理文件注册成服务在系统启动的时候自动调用
- 全球路由DNS服务器
- 用sc删除mysql服务技巧
- 关于三种主流WEB架构的思考
- Powershell获取系统中所有可停止的服务
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- C#中设计、使用Fluent API
- 在同一台机器上运行多个 MySQL 服务
- Android操作系统的架构设计分析
- C语言实现在windows服务中新建进程的方法
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- w3c技术架构介绍
- JavaScript设计模式初探
- JavaScript 组件之旅(一)分析和设计