Spark Broadcast运行机制解密(42)
2016-05-15 13:40
429 查看
一、Broadcast彻底解密 1、Broadcast就是将数据从一个节点发送到其他节点。
2、Broadcast是分布式的共享数据,默认情况下只要程序运行Broadcast变量就会存在,因为Broadcast底层是由BlockManager管理的,但是也可以手动销毁Broadcast变量。 3、Broadcast一般用于处理共享的配置文件,通用的Dataset、常用的数据结构等等,但是不适合存放太大的数据在Broadcast,Broadcast不会内存溢出,因为其数据的保存的StorageLevel是MEMORY_AND_DISK,虽然如此,也不可以放太大的数据,因为网络IO和可能的单点压力会非常大。 4、广播的Broadcast变量是只读变量,保持了数据的一致性。 5、Broadcast的使用: * {{{ * scala> val broadcastVar = sc.broadcast(Array(1, 2, 3)) * broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0) * * scala> broadcastVar.value * res0: Array[Int] = Array(1, 2, 3) * }}}
6、HttpBroadcast方式的Broadcast:最开始的时候数据存在Driver的文件系统中,Driver会在本地创建一个文件夹存放Broadcast中的data,然后启动HttpServer来访问文件夹中的数据,同时写入到BlockManager中,获得BlockId(BroacastBlockId)。当第一次Executor中Task要访问Broadcast变量的时候,会向Driver通过HttpServer来访问数据,然后会在Executor中的BlockManager中注册,这样后续的Task需要访问Broadcast变量的时候会首先查询当前Executor的BlockManager中是否存在,如果存在就就直接获取数据。 7、BroadcastManager是用来管理Broadcast的,该对象是在SparkContext创建SparkEnv的时候创建的。在实例化BroadcastManager的时候会创建BroadcastFactory工厂来构建具体的Broadcst类型,默认是TorrentBroadcastFactory。 8、HttpBroadcast存在单点故障和网络IO性能问题,所以默认使用TorrentBroadcast的方式,开始数据存放在Driver端,假设A点需要访问数据,就会去Driver端拿数据,然后在本地存储一份,A节点也就拥有了一个副本,A节点也就成了数据源,降低了节点压力。 9、TorrentBroadcast按照BLOCK_SIZE(默认4m)将Broadcast中的数据划分成不同的block,然后讲分块信息也就是meta信息存放到Driver端的BlockManager中,同时会通知BlockManagerMaster说明meta信息存放完毕。二、Broadcast源码解密 当广播数据的时候,会调用SparkContext的broadcast方法,在方法内部,Broadcast是由BroadcastManager管理创建的,而BroadcastManager又是有SparkEnv管理的,
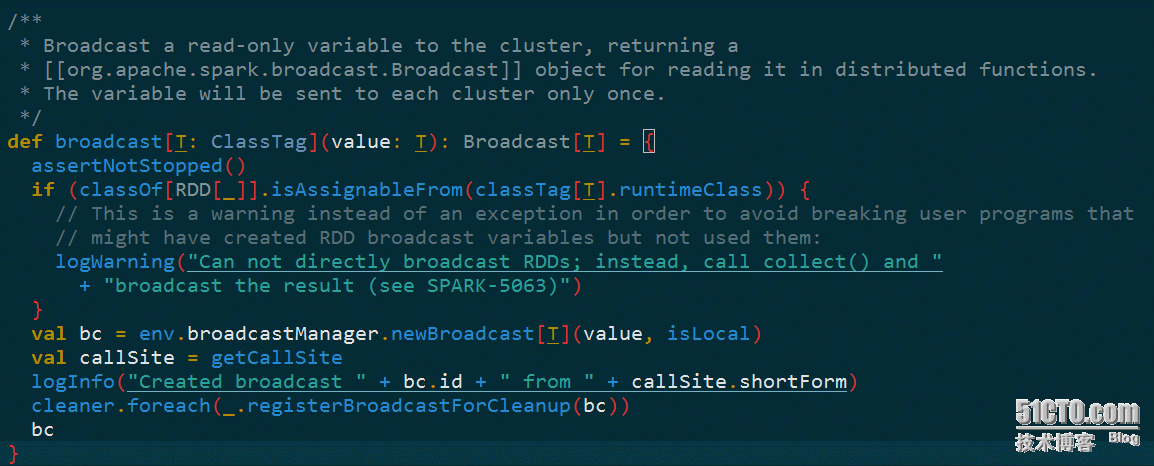
SparkEnv是由SparkContext中的createSparkEnv创建的,进而调用SparkEnv的createDriverEnv方法,最终会调用create自身的方法,构建一些所需的组建。管理Broadcast的BoradcastManager就在此方法中创建。

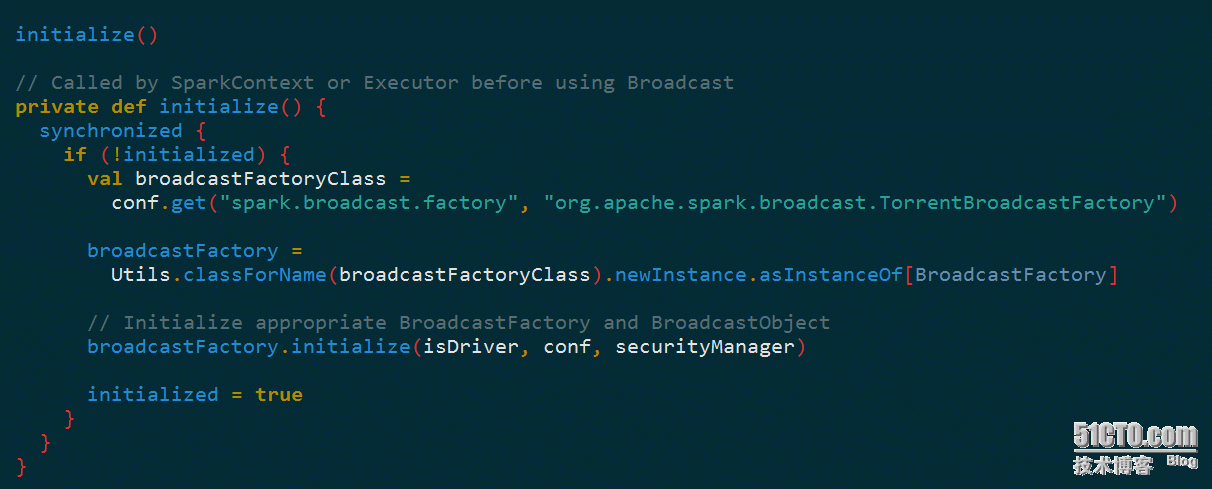
在创建BroadcastManager实例的时候,回调用initialize初始化方法,创建BoradcastFactory,默认是TorrentBroadcastFactory:咋
BroadcastManager初始化之后,就可以调用newBroadcast方法,根据BroadcastFactory创建相应的Broadcast(TorrentBroadcast)进行数据的广播:

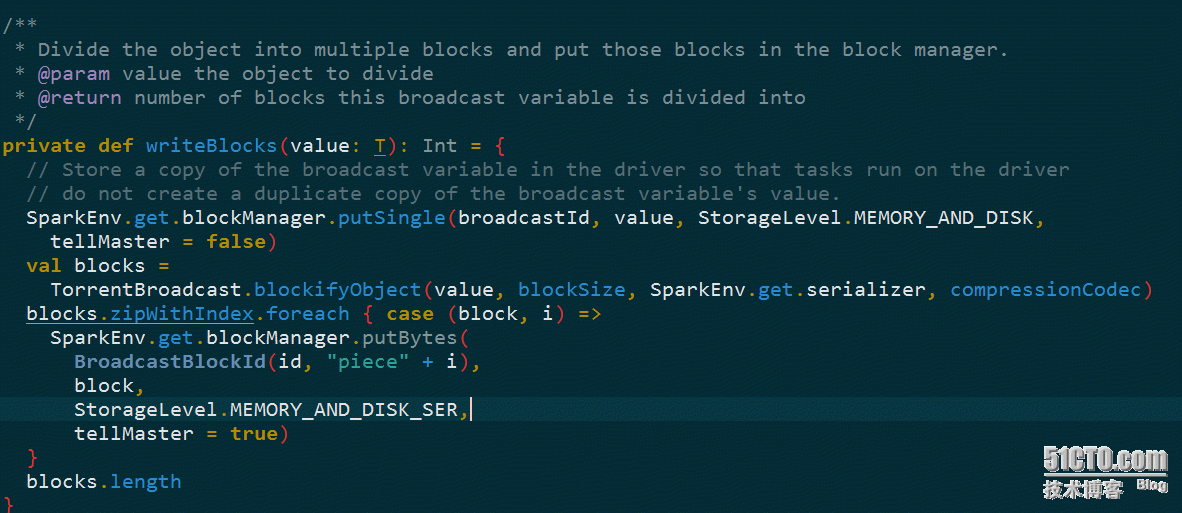
TorrentBroadcastFactory的newBroadcast方法创建一个TorrentBroadcast实例。当我们进行数据的广播的时候,会调用writeBlocks方法,将广播的数据划分成多个block块(默认是4m),把这些block块存放在Driver端:
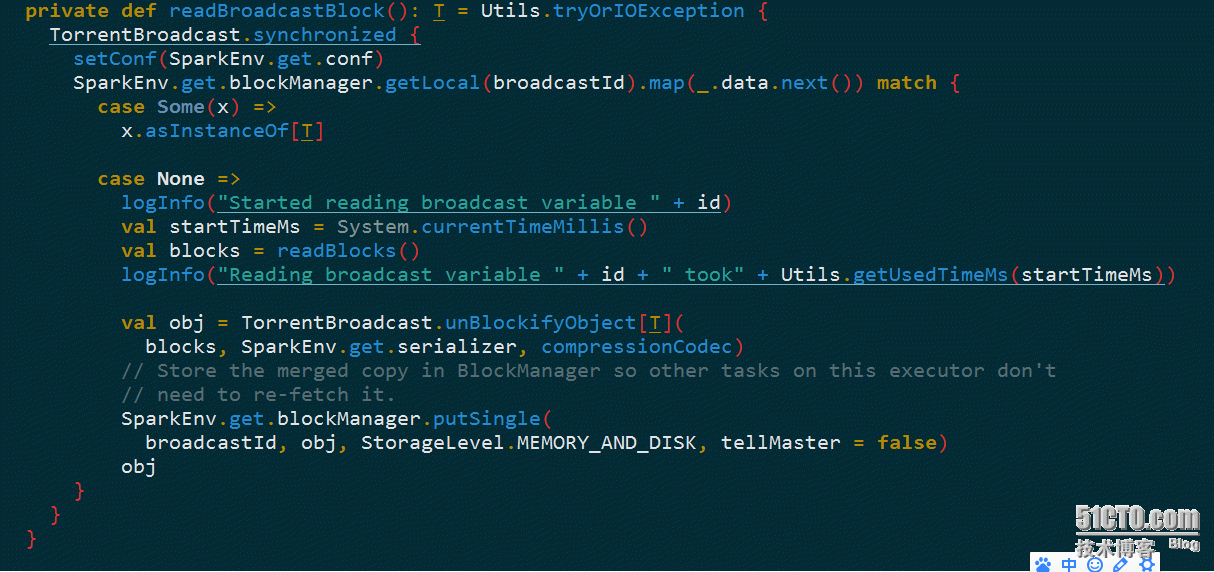
当获取广播变量的值时,会调用相应Broadcast的getValue方法,在TorrentBroadcast中readBroadcastBlock方法,首先会在本地的BlockManager根据BroadcastBlockId获取数据,如果获取不到进而调用readBlocks方法
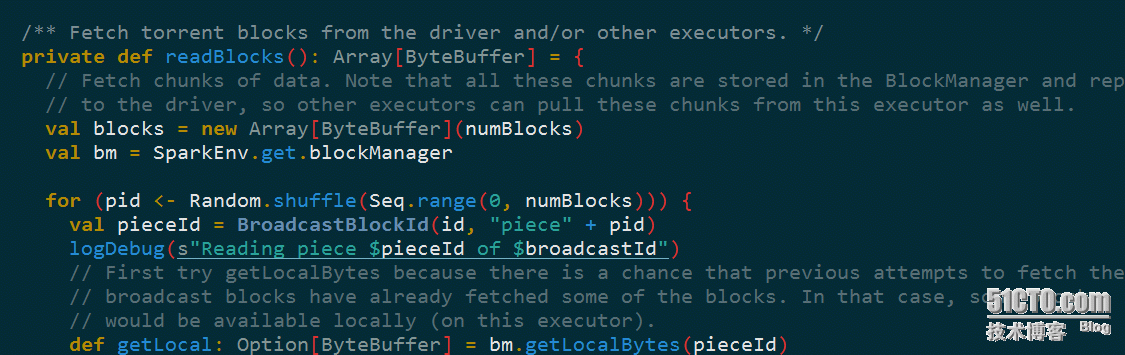
TorrentBroadcast中的readBlocks方法会从Driver端或者其他的Executor获取相应的block快数据,然后把获取的block数据保存到Executor的BlockManager中:

2、Broadcast是分布式的共享数据,默认情况下只要程序运行Broadcast变量就会存在,因为Broadcast底层是由BlockManager管理的,但是也可以手动销毁Broadcast变量。 3、Broadcast一般用于处理共享的配置文件,通用的Dataset、常用的数据结构等等,但是不适合存放太大的数据在Broadcast,Broadcast不会内存溢出,因为其数据的保存的StorageLevel是MEMORY_AND_DISK,虽然如此,也不可以放太大的数据,因为网络IO和可能的单点压力会非常大。 4、广播的Broadcast变量是只读变量,保持了数据的一致性。 5、Broadcast的使用: * {{{ * scala> val broadcastVar = sc.broadcast(Array(1, 2, 3)) * broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0) * * scala> broadcastVar.value * res0: Array[Int] = Array(1, 2, 3) * }}}
6、HttpBroadcast方式的Broadcast:最开始的时候数据存在Driver的文件系统中,Driver会在本地创建一个文件夹存放Broadcast中的data,然后启动HttpServer来访问文件夹中的数据,同时写入到BlockManager中,获得BlockId(BroacastBlockId)。当第一次Executor中Task要访问Broadcast变量的时候,会向Driver通过HttpServer来访问数据,然后会在Executor中的BlockManager中注册,这样后续的Task需要访问Broadcast变量的时候会首先查询当前Executor的BlockManager中是否存在,如果存在就就直接获取数据。 7、BroadcastManager是用来管理Broadcast的,该对象是在SparkContext创建SparkEnv的时候创建的。在实例化BroadcastManager的时候会创建BroadcastFactory工厂来构建具体的Broadcst类型,默认是TorrentBroadcastFactory。 8、HttpBroadcast存在单点故障和网络IO性能问题,所以默认使用TorrentBroadcast的方式,开始数据存放在Driver端,假设A点需要访问数据,就会去Driver端拿数据,然后在本地存储一份,A节点也就拥有了一个副本,A节点也就成了数据源,降低了节点压力。 9、TorrentBroadcast按照BLOCK_SIZE(默认4m)将Broadcast中的数据划分成不同的block,然后讲分块信息也就是meta信息存放到Driver端的BlockManager中,同时会通知BlockManagerMaster说明meta信息存放完毕。二、Broadcast源码解密 当广播数据的时候,会调用SparkContext的broadcast方法,在方法内部,Broadcast是由BroadcastManager管理创建的,而BroadcastManager又是有SparkEnv管理的,
SparkEnv是由SparkContext中的createSparkEnv创建的,进而调用SparkEnv的createDriverEnv方法,最终会调用create自身的方法,构建一些所需的组建。管理Broadcast的BoradcastManager就在此方法中创建。
在创建BroadcastManager实例的时候,回调用initialize初始化方法,创建BoradcastFactory,默认是TorrentBroadcastFactory:咋
BroadcastManager初始化之后,就可以调用newBroadcast方法,根据BroadcastFactory创建相应的Broadcast(TorrentBroadcast)进行数据的广播:
TorrentBroadcastFactory的newBroadcast方法创建一个TorrentBroadcast实例。当我们进行数据的广播的时候,会调用writeBlocks方法,将广播的数据划分成多个block块(默认是4m),把这些block块存放在Driver端:
当获取广播变量的值时,会调用相应Broadcast的getValue方法,在TorrentBroadcast中readBroadcastBlock方法,首先会在本地的BlockManager根据BroadcastBlockId获取数据,如果获取不到进而调用readBlocks方法
TorrentBroadcast中的readBlocks方法会从Driver端或者其他的Executor获取相应的block快数据,然后把获取的block数据保存到Executor的BlockManager中:

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- Android使用广播(BroadCast)实现强制下线的方法
- Android中的广播(BroadCast)详细介绍
- eclipse 开发 spark Streaming wordCount
- Understanding Spark Caching
- ClassNotFoundException:scala.PreDef$
- Windows 下Spark 快速搭建Spark源码阅读环境
- Spark中将对象序列化存储到hdfs
- 使用java代码提交Spark的hive sql任务,run as java application
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- Spark机器学习(二) 局部向量 Local-- Data Types - MLlib
- Spark机器学习(三) Labeled point-- Data Types
- Spark初探
- Spark Streaming初探
- Spark本地开发环境搭建
- 搭建hadoop/spark集群环境
- Spark HA部署方案