树链剖分求LCA(最近公共祖先)
2016-05-15 11:02
162 查看
LCA(Lowest Common Ancestor 最近公共祖先)定义如下:在一棵树中两个节点的LCA为这两个节点所有的公共祖先中深度最大的节点。

如图,节点11与节点6的LCA为节点4,节点12与节点1的LCA为8,节点11与节点10的LCA为10。
现在我们来了解一下LCA我认为最好的算法:树链剖分。
我们来看一个对话:
A:我考你一个问题:给你一个100000节点的树,问你两个点的LCA,你会怎么求?
B:很简单啊,要求a,b的LCA,只要每次把a,b中深度较大的一个往根走,直到a,b相遇。
A:如果有100000个询问呢?
B:没关系,每个询问很快。如果是完全二叉树,树的深度是log_2 100000的,实际的树叉更多,所以深度更小,很容易就跑出来了。
A:假如树是一条链呢?
B:……好像会超时。不过,一条链还用得着求LCA吗?取深度较小的点就行了。
A:如果长这样呢:
/\
/ \
/ \
B:那就把没有分支的链合并成一条,这样就简单了。
A:如果长这样呢:
/\
/\
/\
B:好吧……还是不行。
树链剖分就是一类解决树上路径问题的方法。对于随机生成的树,树高较小,用暴力法就够了,但对于一些树高较大的情况,暴力法便无法处理。这时我们可以将树分成若干条重链,把每条链看成一个整体,以优化算法。
比如,对于以下的树,假如两条加粗的路径AA’,BB’为重链,则求A、B的LCA时,只需取链顶深度较大的B’并将B跳到B’的父节点C,C在链AA’上,于是就能很快得到A、B的LCA为C,而不需要一次次往上寻找。

然而如果链选得不正确,则没有什么好的效果,比如这样:
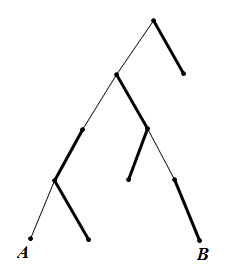
这时候A先走到上面的一条重链,B再走到上面的一条重链,最后A往上走,才能找到LCA。
可见,链的选取很重要。
如何选取重链呢?一种简单的方法是:取每个节点u的所有子节点中,子树最大的子节点v,然后将边(u,v)作为重边,其余边作为轻边,重边构成的链就是重链。
这样的话,任意一条从根到某节点的路径,每遇到一条轻边,子树大小就会减半,因此可以保证经过的重链条数不超过O(logn)。
这就是树链剖分基本思想。
好了看完之后,我想你们大概了解了LCA的树链剖分的基本思路,那我们开始写了。
写法是两遍深搜,第一遍建树,第二遍构造重链。
这是我的代码
用来求根为1的一棵树的LCA。
这就是LCA了,读者们,你们听懂了吗?
如图,节点11与节点6的LCA为节点4,节点12与节点1的LCA为8,节点11与节点10的LCA为10。
现在我们来了解一下LCA我认为最好的算法:树链剖分。
我们来看一个对话:
A:我考你一个问题:给你一个100000节点的树,问你两个点的LCA,你会怎么求?
B:很简单啊,要求a,b的LCA,只要每次把a,b中深度较大的一个往根走,直到a,b相遇。
A:如果有100000个询问呢?
B:没关系,每个询问很快。如果是完全二叉树,树的深度是log_2 100000的,实际的树叉更多,所以深度更小,很容易就跑出来了。
A:假如树是一条链呢?
B:……好像会超时。不过,一条链还用得着求LCA吗?取深度较小的点就行了。
A:如果长这样呢:
/\
/ \
/ \
B:那就把没有分支的链合并成一条,这样就简单了。
A:如果长这样呢:
/\
/\
/\
B:好吧……还是不行。
树链剖分就是一类解决树上路径问题的方法。对于随机生成的树,树高较小,用暴力法就够了,但对于一些树高较大的情况,暴力法便无法处理。这时我们可以将树分成若干条重链,把每条链看成一个整体,以优化算法。
比如,对于以下的树,假如两条加粗的路径AA’,BB’为重链,则求A、B的LCA时,只需取链顶深度较大的B’并将B跳到B’的父节点C,C在链AA’上,于是就能很快得到A、B的LCA为C,而不需要一次次往上寻找。
然而如果链选得不正确,则没有什么好的效果,比如这样:
这时候A先走到上面的一条重链,B再走到上面的一条重链,最后A往上走,才能找到LCA。
可见,链的选取很重要。
如何选取重链呢?一种简单的方法是:取每个节点u的所有子节点中,子树最大的子节点v,然后将边(u,v)作为重边,其余边作为轻边,重边构成的链就是重链。
这样的话,任意一条从根到某节点的路径,每遇到一条轻边,子树大小就会减半,因此可以保证经过的重链条数不超过O(logn)。
这就是树链剖分基本思想。
好了看完之后,我想你们大概了解了LCA的树链剖分的基本思路,那我们开始写了。
写法是两遍深搜,第一遍建树,第二遍构造重链。
这是我的代码
用来求根为1的一棵树的LCA。
#include <cstdio>
#include <cstdlib>
#define maxm 200010
struct edge{int to,len,next;}E[maxm];
int cnt,last[maxm],fa[maxm],top[maxm],deep[maxm],siz[maxm],son[maxm],val[maxm];
void addedge(int a,int b,int len=0)
{
E[++cnt]=(edge){b,len,last[a]},last[a]=cnt;
}
void dfs1(int x)
{
deep[x]=deep[fa[x]]+1;siz[x]=1;
for(int i=last[x];i;i=E[i].next)
{
int to=E[i].to;
if(fa[x]!=to&&!fa[to]){
val[to]=E[i].len;
fa[to]=x;
dfs1(to);
siz[x]+=siz[to];
if(siz[son[x]]<siz[to])son[x]=to;
}
}
}
void dfs2(int x)
{
if(x==son[fa[x]])top[x]=top[fa[x]];
else top[x]=x;
for(int i=last[x];i;i=E[i].next)if(fa[E[i].to]==x)dfs2(E[i].to);
}
void init(int root){dfs1(root),dfs2(root);}
int query(int x,int y)
{
for(;top[x]!=top[y];deep[top[x]]>deep[top[y]]?x=fa[top[x]]:y=fa[top[y]]);
return deep[x]<deep[y]?x:y;
}
int n,m,x,y,v;
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<n;i++)
{
scanf("%d%d",&x,&y);addedge(x,y,v);addedge(y,x,v);
}
init(1);
for(int i=1;i<=m;i++)
{
scanf("%d%d",&x,&y);
printf("%d\n",query(x,y));
}
return 0 ;
}这就是LCA了,读者们,你们听懂了吗?

相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法
- 基于C++实现的各种内部排序算法汇总
- C++线性时间的排序算法分析
- C++实现汉诺塔算法经典实例
- PHP实现克鲁斯卡尔算法实例解析