Spark Streaming源码解读之Job动态生成和深度思考
2016-05-15 00:00
537 查看
摘要: 一、Spark Streaming JOB生成深度思考
二、Spark Streaming JOB生成源码分析
从JobGenerator作为入口,JobGenerator是动态生成JOB的封装。主要是基于Dstream的依赖关系根据batchDuration生成JOB,及spark的流处理跟storm不太一样,storm是流入一条计算一条,而spark的流处理是基于时间段的批处理。
JobGenerator只是负责生成任务,并不执行任务,而是由RDD来触发作业的提交
JobScheduler负责任务的调度
RecurringTimer定时触发任务生成事件
从JobGenerator开始作分析:
注意JobScheduler中也有一个eventLoop消息线程,这个消息线程主要是(JobHandler)通知JobScheduler任务的开始完成等事件:
JobGenerator中的消息线程:
我们关注processEvent方法:
这里有四个事件 ,我们根据跟踪generateJobs方法:
我们回到DStreamGraph的generateJobs方法:
这里使用flatMap是为了去掉None类型的JOB,扁平化返回值
继续追踪outputStream.generateJob(time)(注意这个outputStream就是ForEachDStream 的一个实例)这个方法:
我们继续看Dstream类的getOrCompute方法,追踪如何生成RDD:
从上面的代码中我们看到最终落在了compute(time) 这个关键的方法上面,由于这个方法是个抽象类,我们需要从子类中找实现,以WordCont 程序为例,我们最后一个Stream是ForEachDStream:
每个Dstream都是先计算ParentDstream也就是不断生成RDD链条的过程,最终我们到ReceiverInputDStream 这个类
上面的代码就是从开始生成的第一个RDD的过程,我们每次调用函数的过程都是将函数作用于RDD的过程,也就是生成了RDD,每个Dstream都持有自己的RDD最终我们对RDD调用行动算子的时候是对最后一个Dstream中的RDD进行操作!
我们回到事件处理哪里,思考任务生成事件是从哪里来的?任务是以不间断的生成的,那么必须要一个定时器不断地往eventLoop中post消息(JobGenerator的58行):
这里RecurringTimer 接收了一个 callback: (Long) => Unit类型的函数
这里RecurringTimer 中有一个线程不断地往队列中post任务消息:
重复的触发事件并且回调我们传入的函数:longTime => eventLoop.post(GenerateJobs(new Time(longTime))),及不断地往队列中post消息(RecurringTimer 的103行):
我们看看triggerActionForNextInterval 如何生成任务消息:
总结:JobGenerator接收RecurringTimer中发过来的各种事件,例如生成JOB的事件,然后由JobGenerator来分别处理各种任务事件,这种方式可以重复利用代码,不同的模块负责不同的功能,一方面是解耦,另一方是模块化
最后我们关注一点:任务怎么被提交到集群的?
我们回到JobGenerator的generateJobs方法(241行):
这里我们看到:JobGenerator生成好任务后交给了jobScheduler来处理
我们看看JobHandler怎么处理我们传入的任务:
我们追踪:job.run方法:
这里执行了一个func方法,那这个方法从哪里来的,又做了什么事?
前面我们分析过,DStream中生成的任务只是封装了一个函数并没有执行,再次回归Dstream中的:
及我们生成的JOB中的那个func() 就是:
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
这个函数,这里最终作用于RDD向DAG提交任务:
这里就不继续追踪下去了,到此任务怎么生成以及任务怎么被提交的已经全部分析完成。
最后附上一张JOB动态生成简图:
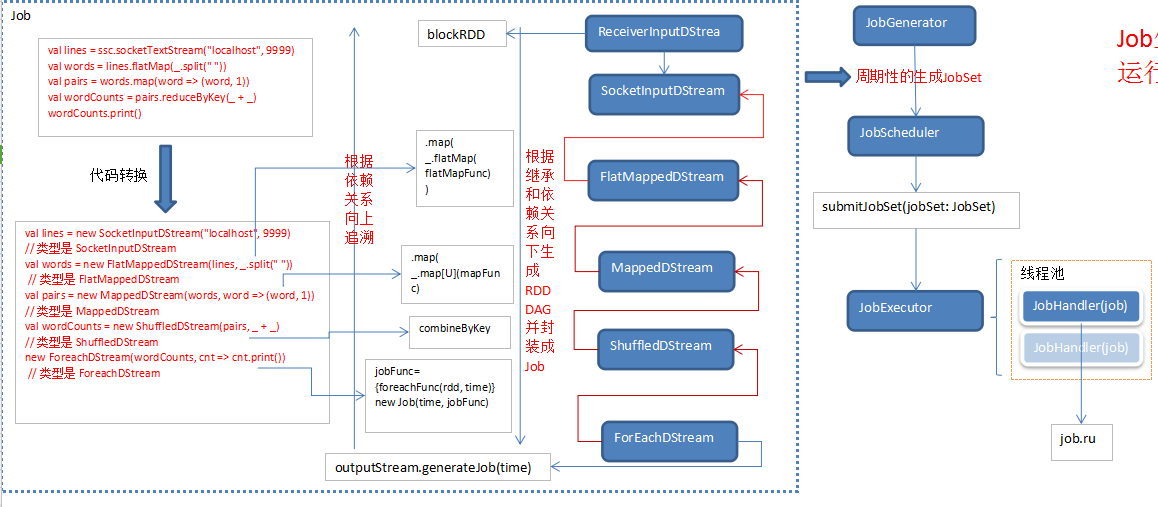
二、Spark Streaming JOB生成源码分析
一、Spark Streaming JOB生成深度思考
定时任务,其实也算是流处理的一种,都是时间加上定时器(也有可能是某个条件),一切处理都是流处理。从JobGenerator作为入口,JobGenerator是动态生成JOB的封装。主要是基于Dstream的依赖关系根据batchDuration生成JOB,及spark的流处理跟storm不太一样,storm是流入一条计算一条,而spark的流处理是基于时间段的批处理。
/**
* This class generates jobs from DStreams as well as drives checkpointing and cleaning
* up DStream metadata.
*/
private[streaming]
class JobGenerator(jobScheduler: JobScheduler) extends Logging {JobGenerator只是负责生成任务,并不执行任务,而是由RDD来触发作业的提交
二、Spark Streaming JOB生成源码分析
JobGenerator负责生成任务JobScheduler负责任务的调度
RecurringTimer定时触发任务生成事件
从JobGenerator开始作分析:
注意JobScheduler中也有一个eventLoop消息线程,这个消息线程主要是(JobHandler)通知JobScheduler任务的开始完成等事件:
private[scheduler] sealed trait JobSchedulerEvent private[scheduler] case class JobStarted(job: Job, startTime: Long) extends JobSchedulerEvent private[scheduler] case class JobCompleted(job: Job, completedTime: Long) extends JobSchedulerEvent private[scheduler] case class ErrorReported(msg: String, e: Throwable) extends JobSchedulerEvent
JobGenerator中的消息线程:
/** Start generation of jobs */
def start(): Unit = synchronized {
if (eventLoop != null) return // generator has already been started
// Call checkpointWriter here to initialize it before eventLoop uses it to avoid a deadlock.
// See SPARK-10125
checkpointWriter
//接收任务的各种事件(如任务生成,清除元信息、DoCheckpoint)
eventLoop = new EventLoop[JobGeneratorEvent]("JobGenerator") {
override protected def onReceive(event: JobGeneratorEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = {
jobScheduler.reportError("Error in job generator", e)
}
}
eventLoop.start()
if (ssc.isCheckpointPresent) {
restart()
} else {
startFirstTime()
}
}我们关注processEvent方法:
/** Processes all events */
private def processEvent(event: JobGeneratorEvent) {
logDebug("Got event " + event)
event match {
//根据时间点来生成任务
case GenerateJobs(time) => generateJobs(time)
case ClearMetadata(time) => clearMetadata(time)
case DoCheckpoint(time, clearCheckpointDataLater) =>
doCheckpoint(time, clearCheckpointDataLater)
case ClearCheckpointData(time) => clearCheckpointData(time)
}
}这里有四个事件 ,我们根据跟踪generateJobs方法:
/** Generate jobs and perform checkpoint for the given `time`. */
private def generateJobs(time: Time) {
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try {
//这里是分配blocks给当前时间点(receiverTracker记录了Blocks的元信息)
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
//DstremGraph生成JOB,DstremGraph记录了Dstream的DAG
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}我们回到DStreamGraph的generateJobs方法:
这里使用flatMap是为了去掉None类型的JOB,扁平化返回值
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized {
//这里的outputStreams 是我们每次调用foreachRDD会向DStreamGraph注册输出的outputStream
// private val outputStreams = new ArrayBuffer[DStream[_]]()
outputStreams.flatMap { outputStream =>
val jobOption = outputStream.generateJob(time)
jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
}
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}继续追踪outputStream.generateJob(time)(注意这个outputStream就是ForEachDStream 的一个实例)这个方法:
/**
* Generate a SparkStreaming job for the given time. This is an internal method that
* should not be called directly. This default implementation creates a job
* that materializes the corresponding RDD. Subclasses of DStream may override this
* to generate their own jobs.
*/
private[streaming] def generateJob(time: Time): Option[Job] = {
//这个方法根据Dstream生成了RDD
getOrCompute(time) match {
case Some(rdd) => {
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
//这里我们看到提交任务是基于RDD的,真正向DAG提交任务是被封装到一个函数中,因此不会马上运行
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
}
case None => None
}
}我们继续看Dstream类的getOrCompute方法,追踪如何生成RDD:
/**
* Get the RDD corresponding to the given time; either retrieve it from cache
* or compute-and-cache it.
*/
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
//注意Dstream是抽象类,所以每个Dstream的实现类都自己的generatedRDDs这个对象,
即我们在代码里边所做的Dstream的转换最终作用于最开始的那个RDD,每个Dstream都持有自己的RDD实例,最终计算的时候只需要最后
一个RDD即可
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
compute(time)
}
}
rddOption.foreach { case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
//每个Dstream的实现类都有自己的RDD!
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}从上面的代码中我们看到最终落在了compute(time) 这个关键的方法上面,由于这个方法是个抽象类,我们需要从子类中找实现,以WordCont 程序为例,我们最后一个Stream是ForEachDStream:
//ForEachDStream的46行
override def generateJob(time: Time): Option[Job] = {
//这里的Parent就是ShuffledDStream
parent.getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => createRDDWithLocalProperties(time, displayInnerRDDOps) {
foreachFunc(rdd, time)
}
Some(new Job(time, jobFunc))
case None => None
}
}每个Dstream都是先计算ParentDstream也就是不断生成RDD链条的过程,最终我们到ReceiverInputDStream 这个类
/**
* Generates RDDs with blocks received by the receiver of this stream. */
override def compute(validTime: Time): Option[RDD[T]] = {
val blockRDD = {
if (validTime < graph.startTime) {
// If this is called for any time before the start time of the context,
// then this returns an empty RDD. This may happen when recovering from a
// driver failure without any write ahead log to recover pre-failure data.
new BlockRDD[T](ssc.sc, Array.empty)
} else {
// Otherwise, ask the tracker for all the blocks that have been allocated to this stream
// for this batch
val receiverTracker = ssc.scheduler.receiverTracker
val blockInfos = receiverTracker.getBlocksOfBatch(validTime).getOrElse(id, Seq.empty)
// Register the input blocks information into InputInfoTracker
val inputInfo = StreamInputInfo(id, blockInfos.flatMap(_.numRecords).sum)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
// Create the BlockRDD
createBlockRDD(validTime, blockInfos)
}
}
Some(blockRDD)
}上面的代码就是从开始生成的第一个RDD的过程,我们每次调用函数的过程都是将函数作用于RDD的过程,也就是生成了RDD,每个Dstream都持有自己的RDD最终我们对RDD调用行动算子的时候是对最后一个Dstream中的RDD进行操作!
我们回到事件处理哪里,思考任务生成事件是从哪里来的?任务是以不间断的生成的,那么必须要一个定时器不断地往eventLoop中post消息(JobGenerator的58行):
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds, longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
这里RecurringTimer 接收了一个 callback: (Long) => Unit类型的函数
这里RecurringTimer 中有一个线程不断地往队列中post任务消息:
private[streaming]
class RecurringTimer(clock: Clock, period: Long, callback: (Long) => Unit, name: String)
extends Logging {
private val thread = new Thread("RecurringTimer - " + name) {
setDaemon(true)
override def run() { loop }
}重复的触发事件并且回调我们传入的函数:longTime => eventLoop.post(GenerateJobs(new Time(longTime))),及不断地往队列中post消息(RecurringTimer 的103行):
/**
* Repeatedly call the callback every interval.
*/
private def loop() {
try {
while (!stopped) {
triggerActionForNextInterval()
}
triggerActionForNextInterval()
} catch {
case e: InterruptedException =>
}
}
}我们看看triggerActionForNextInterval 如何生成任务消息:
private def triggerActionForNextInterval(): Unit = {
clock.waitTillTime(nextTime)
callback(nextTime)
prevTime = nextTime
nextTime += period
logDebug("Callback for " + name + " called at time " + prevTime)
}总结:JobGenerator接收RecurringTimer中发过来的各种事件,例如生成JOB的事件,然后由JobGenerator来分别处理各种任务事件,这种方式可以重复利用代码,不同的模块负责不同的功能,一方面是解耦,另一方是模块化
最后我们关注一点:任务怎么被提交到集群的?
我们回到JobGenerator的generateJobs方法(241行):
/** Generate jobs and perform checkpoint for the given `time`. */
SparkEnv.set(ssc.env)
Try {
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
//这里就是我们前面分析的任务怎么生成的
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
//任务生成后怎么处理?
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}这里我们看到:JobGenerator生成好任务后交给了jobScheduler来处理
def submitJobSet(jobSet: JobSet) {
if (jobSet.jobs.isEmpty) {
logInfo("No jobs added for time " + jobSet.time)
} else {
listenerBus.post(StreamingListenerBatchSubmitted(jobSet.toBatchInfo))
jobSets.put(jobSet.time, jobSet)
//我们看到foreach传入了一个处理JOB的函数:job => jobExecutor.execute(new JobHandler(job))
//注意这里使用了一个线程池来执行任务
jobSet.jobs.foreach(job => jobExecutor.execute(new JobHandler(job)))
logInfo("Added jobs for time " + jobSet.time)
}
}我们看看JobHandler怎么处理我们传入的任务:
private class JobHandler(job: Job) extends Runnable with Logging {
import JobScheduler._
def run() {
try {
val formattedTime = UIUtils.formatBatchTime(
job.time.milliseconds, ssc.graph.batchDuration.milliseconds, showYYYYMMSS = false)
val batchUrl = s"/streaming/batch/?id=${job.time.milliseconds}"
val batchLinkText = s"[output operation ${job.outputOpId}, batch time ${formattedTime}]"
ssc.sc.setJobDescription(
s"""Streaming job from <a href="$batchUrl">$batchLinkText</a>""")
ssc.sc.setLocalProperty(BATCH_TIME_PROPERTY_KEY, job.time.milliseconds.toString)
ssc.sc.setLocalProperty(OUTPUT_OP_ID_PROPERTY_KEY, job.outputOpId.toString)
var _eventLoop = eventLoop
if (_eventLoop != null) {
//这里把任务开始事件通知JobScheduler 任务开始了
_eventLoop.post(JobStarted(job, clock.getTimeMillis()))
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
//最终调用了job.run方法来处理任务,思考jbo.run做了哪些事?
job.run()
}
_eventLoop = eventLoop
if (_eventLoop != null) {
//这里把任务开始事件通知JobScheduler 任务完成了
_eventLoop.post(JobCompleted(job, clock.getTimeMillis()))
}
} else {
// JobScheduler has been stopped.
}
} finally {
ssc.sc.setLocalProperty(JobScheduler.BATCH_TIME_PROPERTY_KEY, null)
ssc.sc.setLocalProperty(JobScheduler.OUTPUT_OP_ID_PROPERTY_KEY, null)
}
}
}我们追踪:job.run方法:
def run() {
_result = Try(func())
}这里执行了一个func方法,那这个方法从哪里来的,又做了什么事?
前面我们分析过,DStream中生成的任务只是封装了一个函数并没有执行,再次回归Dstream中的:
/**
* Generate a SparkStreaming job for the given time. This is an internal method that
* should not be called directly. This default implementation creates a job
* that materializes the corresponding RDD. Subclasses of DStream may override this
* to generate their own jobs.
*/
private[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {
case Some(rdd) => {
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
}
case None => None
}
}及我们生成的JOB中的那个func() 就是:
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
这个函数,这里最终作用于RDD向DAG提交任务:
/**
* Run a job on all partitions in an RDD and return the results in an array.
*/
def runJob[T, U: ClassTag](rdd: RDD[T], func: Iterator[T] => U): Array[U] = {
runJob(rdd, func, 0 until rdd.partitions.length)
}这里就不继续追踪下去了,到此任务怎么生成以及任务怎么被提交的已经全部分析完成。
最后附上一张JOB动态生成简图:

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- eclipse 开发 spark Streaming wordCount
- Understanding Spark Caching
- ClassNotFoundException:scala.PreDef$
- Windows 下Spark 快速搭建Spark源码阅读环境
- Spark中将对象序列化存储到hdfs
- 使用java代码提交Spark的hive sql任务,run as java application
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- Spark机器学习(二) 局部向量 Local-- Data Types - MLlib
- Spark机器学习(三) Labeled point-- Data Types
- Spark初探
- Spark Streaming初探
- Spark本地开发环境搭建
- 搭建hadoop/spark集群环境
- Spark HA部署方案
- 直播|易观CTO郭炜:精益化数据分析——如何让你的企业具有BAT一样的分析能力