一个简单的爬虫实验
2016-05-14 08:49
806 查看
博主一直想研究爬虫,可惜并没有很好的机会,乘着双休日没事,学着写了一个非常简单的小爬虫。
本爬虫使用Jsoup,Jsoup主要是简化连接和选择取内容的代码,抓取的是知乎日报首页上的文章。
其实大家都知道,互联网上显示的内容都最终都是由HTML构成的,说以写爬虫最主要的工作就是分析网页代码的结构,知乎日报首页的结构如下:
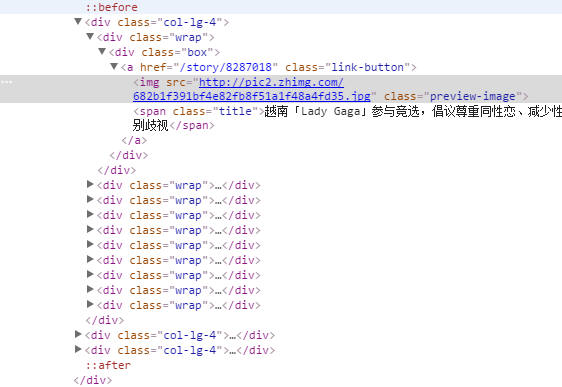
经分析得知,每一个col-lg-4类对应着每一列,共有三列,每个wrap或box或link-button类都可以代表一篇文章。我们要做的工作就是将文章里的标题取出来,然后在取出文章对应链接里面的内容。我们现在已经可以用wrap,box,link-button等获得文章的标题(越南「Lady Gaga」参与竞选,倡议尊重同性恋、减少性别歧视)和文章的链接(/story/8287018),下一步就是获取链接里的内容,打开链接,我们得到如下结构:
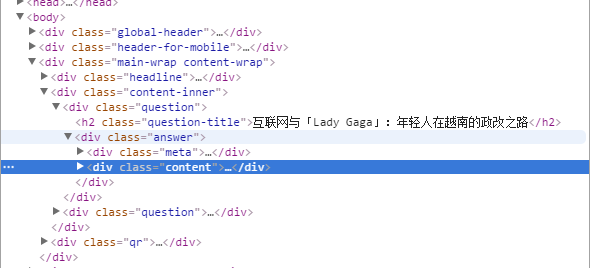
这里就要看大家想怎么抓取了,content类只包含内容,没有作者,标题。如果想把这些也抓取进来,可以选着question类。我选着的是content类。
代码如下
做完这个后,感觉爬虫的难点在于分析html的文档结构,按照什么逻辑去爬取,这两个问题理清楚了,爬虫代码还是很容易写的。
本文还有一个方面没有涉及到,就是动态生成的网页,动态生成的网页通过如上方法是不行的,一般是在一个异步请求返回的json串里,上网查了一下,一般有两种方案,一是模拟用户浏览器操作得到所需要的信息,还有一种是直接分析你需要的异步请求,找到规律,下次有时间在研究研究和大家分享。
本爬虫使用Jsoup,Jsoup主要是简化连接和选择取内容的代码,抓取的是知乎日报首页上的文章。
其实大家都知道,互联网上显示的内容都最终都是由HTML构成的,说以写爬虫最主要的工作就是分析网页代码的结构,知乎日报首页的结构如下:
经分析得知,每一个col-lg-4类对应着每一列,共有三列,每个wrap或box或link-button类都可以代表一篇文章。我们要做的工作就是将文章里的标题取出来,然后在取出文章对应链接里面的内容。我们现在已经可以用wrap,box,link-button等获得文章的标题(越南「Lady Gaga」参与竞选,倡议尊重同性恋、减少性别歧视)和文章的链接(/story/8287018),下一步就是获取链接里的内容,打开链接,我们得到如下结构:
这里就要看大家想怎么抓取了,content类只包含内容,没有作者,标题。如果想把这些也抓取进来,可以选着question类。我选着的是content类。
代码如下
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class ADemo {
public static void main(String[] args) throws IOException {
Connection.Response connection;
connection = Jsoup.connect("http://daily.zhihu.com/").execute();
Document doc = connection.parse();
//得到文章信息的html块
Elements elements = doc.select("a.link-button");
for(Element element:elements){
//获得文章的标题
System.out.print(element.text()+"|||||");
//获得文章内容的url,然后打开链接
String url = "http://daily.zhihu.com"+element.select("a").attr("href");
Connection.Response connection2;
connection2 = Jsoup.connect(url).execute();
//获得文章的内容
System.out.println(connection2.parse().select(".content").text());
}
}
}做完这个后,感觉爬虫的难点在于分析html的文档结构,按照什么逻辑去爬取,这两个问题理清楚了,爬虫代码还是很容易写的。
本文还有一个方面没有涉及到,就是动态生成的网页,动态生成的网页通过如上方法是不行的,一般是在一个异步请求返回的json串里,上网查了一下,一般有两种方案,一是模拟用户浏览器操作得到所需要的信息,还有一种是直接分析你需要的异步请求,找到规律,下次有时间在研究研究和大家分享。

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- Python3写爬虫(四)多线程实现数据爬取
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- Scrapy的架构介绍
- PropertyChangeListener简单理解
- 爬虫笔记
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序