XML系列:(4)XML解析-JAXP的DOM解析方式读取XML
2016-05-13 20:33
471 查看
DOM、SAX和StAX只是解析方式,没有API。JAXP是SUN提供的一套XML解析API。
JAXP(Java API for XMLProcessing,意为XML处理的Java API)JAXP很好的支持DOM和SAX解析。JAXP开发包是JAVASE的一部分,它由java.xml、org.w3c.dom、org.xml.sax包及其子包组成
products.mxl
JAXP(Java API for XMLProcessing,意为XML处理的Java API)JAXP很好的支持DOM和SAX解析。JAXP开发包是JAVASE的一部分,它由java.xml、org.w3c.dom、org.xml.sax包及其子包组成
products.mxl
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE products[ <!ELEMENT products (product+)> <!ELEMENT product (name,price)> <!ELEMENT name (#PCDATA)> <!ELEMENT price (#PCDATA)> <!ATTLIST product id ID #REQUIRED> ]> <products> <product id="p001"> <name>往事并不如烟</name> <price>49.9元</price> </product> <product id="p002"> <name>围城</name> <price>59.9元</price> </product> </products>
1、以DOM解析方式读取XML
1.1、根据Id读取一个元素(Element)
package com.rk.xml.d_jaxp_dom;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
/**
* 根据Id读取一个元素(Element)
* 通过Document.getElementById(String elementId)方法获取一个元素(Element)
* @author RK
*
*/
public class Demo01
{
public static void main(String[] args) throws Exception
{
//1、新拿到解析器工厂
//2、通过解析器工厂拿到解析器对象
//3、通过解析器对象解析XML文档,并返回Document对象
//4、通过Document对象去获取节点Node
//1、新拿到解析器工厂
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
//2、通过解析器工厂拿到解析器对象
DocumentBuilder builder = builderFactory.newDocumentBuilder();
//3、通过解析器对象解析XML文档,并返回Document对象
Document doc = builder.parse("./src/products.xml");
//4、通过Document对象去获取节点Node
Element elem = doc.getElementById("p001");//必须使用DTD声明ID属性
System.out.println(elem);//[product: null]
System.out.println(elem.getNodeType());//1 元素(Element)类型的节点用1表示
System.out.println(elem.getNodeName());//product
System.out.println(elem.getNodeValue());//null
System.out.println(elem.getTextContent());//往事并不如烟49.9元
}
}1.2、读取一系列节点(NodeList)
package com.rk.xml.d_jaxp_dom;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
/**
* 读取一系列节点(NodeList)
* 通过Document.getElementsByTagName(String tagname)获取一系列节点。
* @author RK
*
*/
public class Demo02
{
public static void main(String[] args) throws Exception
{
//1、新拿到解析器工厂
//2、通过解析器工厂拿到解析器对象
//3、通过解析器对象解析XML文档,并返回Document对象
//4、通过Document对象去获取节点Node
//1、新拿到解析器工厂
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
//2、通过解析器工厂拿到解析器对象
DocumentBuilder builder = builderFactory.newDocumentBuilder();
//3、通过解析器对象解析XML文档,并返回Document对象
Document doc = builder.parse("./src/products.xml");
//4、通过Document对象去获取节点Node
NodeList list = doc.getElementsByTagName("product");
System.out.println("找到"+list.getLength()+"个");//找到多少个节点
for(int i=0;i<list.getLength();i++)
{
Node node = list.item(i);
System.out.println(node);//将各个节点进行打印
}
}
}1.3、读取一个属性(Attribute)
package com.rk.xml.d_jaxp_dom;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.NamedNodeMap;
/**
* 读取一个属性(Attribute)
* @author RK
*
*/
public class Demo03
{
public static void main(String[] args) throws Exception
{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document doc = builder.parse("./src/products.xml");
NodeList list = doc.getElementsByTagName("product");
Node node = list.item(0);
NamedNodeMap map = node.getAttributes();//获取到所有属性类型的节点
Node attrNode = map.getNamedItem("id");//获取到属性为“id”的节点
System.out.println(attrNode.getNodeType());//2 属性(Attribute)类型的节点用2表示
System.out.println(attrNode.getNodeName());//id
System.out.println(attrNode.getNodeValue());//p001
System.out.println(attrNode.getTextContent());//p001
}
}1.4、读取一个元素的文本(Text)
package com.rk.xml.d_jaxp_dom;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
/**
* 读取一个元素的文本(Text)
* @author RK
*
*/
public class Demo04
{
public static void main(String[] args) throws Exception
{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document doc = builder.parse("./src/products.xml");
NodeList list = doc.getElementsByTagName("name");
Node node = list.item(0);
System.out.println(node.getTextContent());//往事并不如烟
}
}1.5、遍历Document对象树
package com.rk.xml.d_jaxp_dom;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.NamedNodeMap;
/**
* 遍历所有节点
* @author RK
*
*/
public class Demo05
{
public static void main(String[] args) throws Exception
{
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = builderFactory.newDocumentBuilder();
Document doc = builder.parse("./src/products.xml");
StringBuilder sb = new StringBuilder();
NodeList childNodes = doc.getChildNodes();
for(int i=0;i<childNodes.getLength();i++)
{
Node node = childNodes.item(i);
System.out.println(node.getNodeType() + "===" + node.getNodeName()+ "===" + node.getNodeValue());
}
/*
输出结果:
10===products===null DOCUMENT_TYPE_NODE = 10
1===products===null ELEMENT_NODE = 1
*/
traverseDocument(doc.getLastChild(),sb);
System.out.println(sb.toString());
/*
输出结果:
<products >
<product id="p001" >
<name >往事并不如烟</name>
<price >49.9元</price>
</product>
<product id="p002" >
<name >围城</name>
<price >59.9元</price>
</product>
</products>
*/
}
private static void traverseDocument(Node node, StringBuilder sb)
{
//1、当前元素开始
sb.append("<" + node.getNodeName() + " ");
//2、获取属性
if(node.hasAttributes())
{
NamedNodeMap nodeMap = node.getAttributes();
for(int i=0;i<nodeMap.getLength();i++)
{
Node attrNode = nodeMap.item(i);
sb.append(attrNode.getNodeName() + "=\"" + attrNode.getNodeValue() + "\" ");
}
}
sb.append(">");
//3、获取子节点
NodeList childNodes = node.getChildNodes();
for(int i=0;i<childNodes.getLength();i++)
{
Node subNode = childNodes.item(i);
short type = subNode.getNodeType();
if(type == 1)//当前节点是Element节点
{
traverseDocument(subNode, sb);
}
else if(type == 3)//当前节点是Text节点
{
sb.append(subNode.getTextContent());
}
else
{
//其它情况,不做处理
}
}
//4、当前元素结束
sb.append("</" + node.getNodeName() + ">");
}
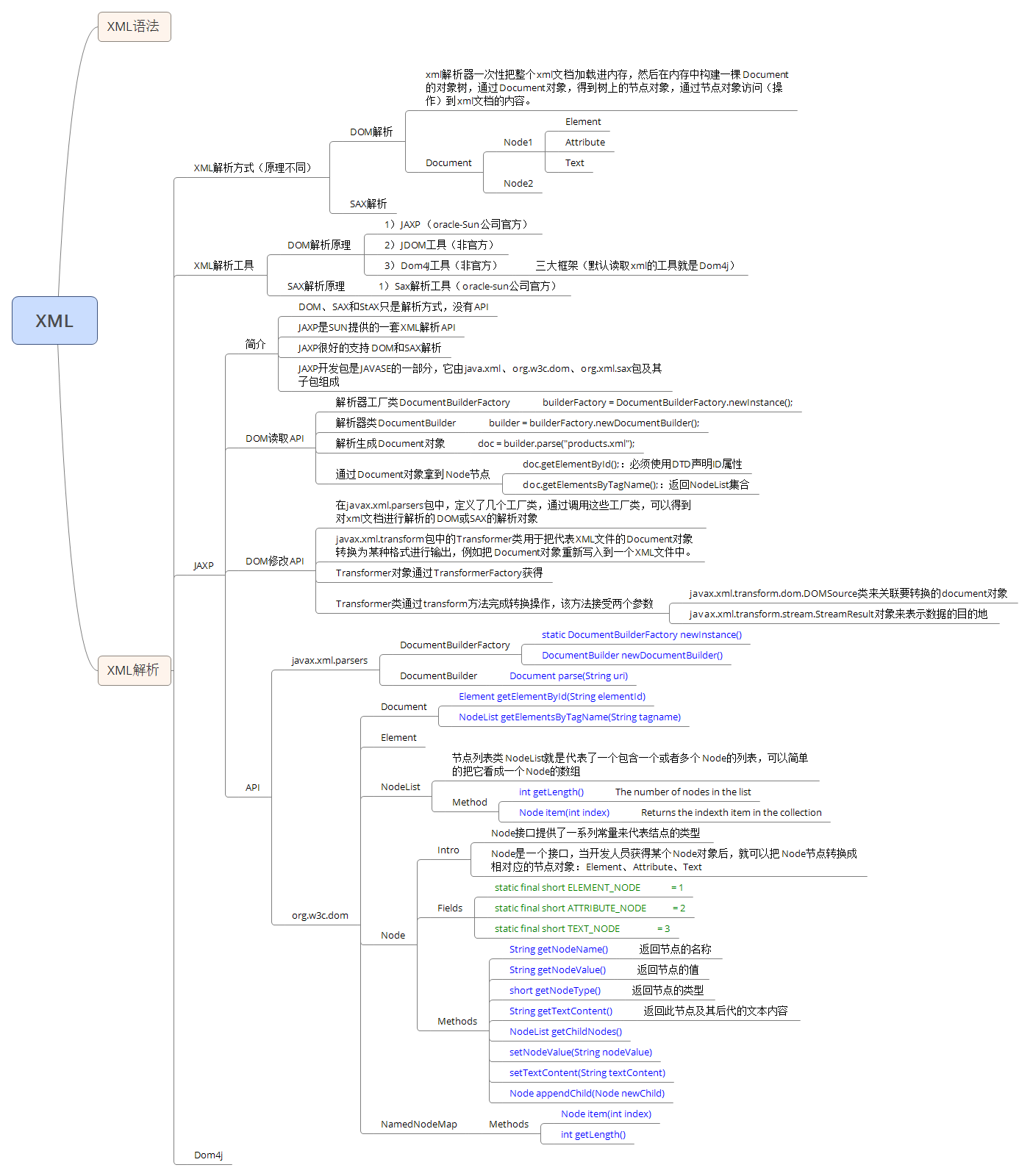
}2、思维导图

相关文章推荐
- XML 与 JSON 优劣对比
- As3.0 xml + Loader应用代码
- Mootools 1.2教程(2) DOM选择器
- DOM 事件流详解
- 网马生成器 MS Internet Explorer XML Parsing Buffer Overflow Exploit (vista) 0day
- ext读取两种结构的xml的代码
- Dom在ajax技术中的作用说明
- 实例解析Ruby程序中调用REXML来解析XML格式数据的用法
- Ruby中XML格式数据处理库REXML的使用方法指南
- C#针对xml基本操作及保存配置文件应用实例
- Ruby使用REXML库来解析xml格式数据的方法
- Ruby程序中创建和解析XML文件的方法
- Ruby的XML格式数据解析库Nokogiri的使用进阶
- asp下查询xml的实现代码
- sqlserver FOR XML PATH 语句的应用
- 使用sp_xml_preparedocument处理XML文档的方法
- EBS xml publisher中文乱码问题及解决办法
- C#中的Linq to Xml详解
- C#操作XML文件实例汇总