ElasticSearch之初识
2016-05-11 10:37
246 查看
是什么?
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。
安装&Run
在安装es之前,需要jdk的支持,最好是jdk1.7以上的版本,es从2.0以后的版本都需要比较新的jdk版本的支持。如果你是在windows上面运行的话,运行时可能会碰到这个问题: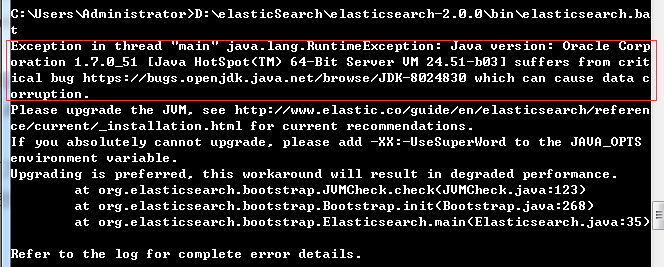
官方推荐使用OracleJDK的版本,如果是其他版本的jdk,运行.bat时要在其后加上 -XX:-UseSuperWord的命令。
es的官方下载地址
es的github下载地址
各平台需要下载不同的安装包,我这里演示的是windows下的安装&Run的过程。linux下运行很简单,解压安装包后直接运行安装后的目录下的/bin/elasticsearch即可,这里提醒一下,es2.0以上的版本,root用户无法启动es的服务的,需要你新建一个拥有执行该脚本命令的权限的用户。windows下则运行elasticsearch.bat文件,如绝对路径:D:\elasticSearch\elasticsearch-2.0.0\bin\elasticsearch.bat -XX:-UseSuperWord。如下图
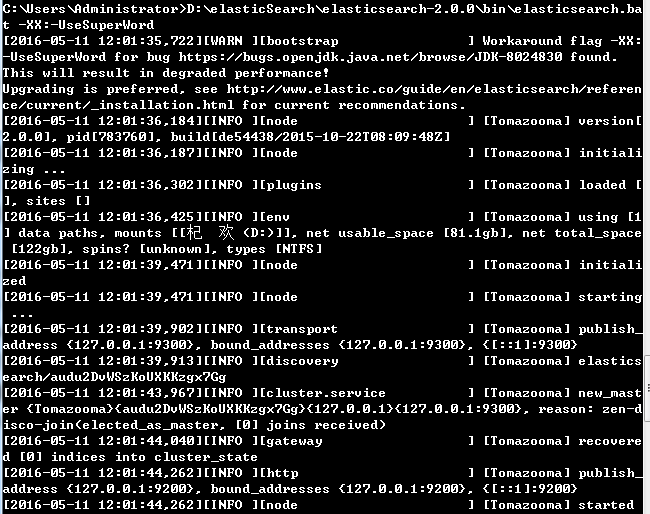
启动完成后,我们可以通过浏览器直接访问我们的es集群了。http://localhost:9200
es的一些概念的东西
IndexIndex(索引)类似于关系型数据库里的“数据库”——它是我们存储和索引关联数据的地方。( 这个名字必须是全部小写,不能以下划线开头,不能包含逗号。)
Document
存储在es中的主要实体叫Document(文档)。 用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。
Type
在关系型数据库中,我们经常将相同类的对象存储在一个表里,因为它们有着相同的结构。 同理,在es中,我们使用相同类型(type)的文档表示相同的“事物”,因为他们的数据结构也是相同的。每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所有类型下的文档被存储在同一个索引下,但是类型的映射(mapping)会告诉Elasticsearch不同的文档如何被索引。
Field:类似关系数据库的某一列,这是ES数据存储的最小单位。
Cluster和Node:ES可以以单点或者集群方式运行,以一个整体对外提供search服务的所有节点组成cluster,组成这个cluster的各个节点叫做node。
shard:通常叫分片,这是ES提供分布式搜索的基础,其含义为将一个完整的index分成若干部分存储在相同或不同的节点上,这些组成index的部分就叫做shard。
Replication:和replication通常指的都是一回事,即index的冗余备份,可以用于防止数据丢失,或者用来做负载分担。

相关文章推荐
- 微信搜一搜迈出新的一步,好戏来了
- 巧用mysql提示符prompt清晰管理数据库的方法
- AJAX 支持搜索引擎问题分析
- 搜索引擎对关键词作弊判断方法揭密
- 使用php记录用户通过搜索引擎进网站的关键词
- 两大步骤教您开启MySQL 数据库远程登陆帐号的方法
- android将搜索引擎设置为中国雅虎无法搜索问题解决方法
- Asp.Net、asp实现的搜索引擎网址收录检查程序
- phpmyadmin 4+ 访问慢的解决方法
- linux系统下实现mysql热备份详细步骤(mysql主从复制)
- 如何让搜索引擎抓取AJAX内容解决方案
- PHP判断来访是搜索引擎蜘蛛还是普通用户的代码小结
- php实现判断访问来路是否为搜索引擎机器人的方法
- CentOS 5.5下安装MySQL 5.5全过程分享
- MySQL复制的概述、安装、故障、技巧、工具(火丁分享)
- MySQL中删除重复数据的简单方法
- php获取从百度、谷歌等搜索引擎进入网站关键词的方法
- 解析PHP对现有搜索引擎的调用
- C#判断访问来源是否为搜索引擎链接的方法
- WordPress特定文章对搜索引擎隐藏或只允许搜索引擎查看