hive--桶
2016-05-10 16:52
120 查看
桶:
set hive.enforce.bucketing = true; 使hive知道用表定义中声明的数量来创建桶

(这里数据之间的tab消失了,但并不是真的消失了)
(这也是一个MR任务,而且取样返回的是2/4的数据)
select * from bucketed_wyp tablesample(bucket 2 out of 4 on rand());
使用rand()之后,返回随机,但是使用了桶之后,扫描的是一部分,不使用桶,扫描的是所有的表。
set hive.enforce.bucketing = true; 使hive知道用表定义中声明的数量来创建桶
create table bucketed_wyp (id int, name string, age int, tel string) clustered by (id) sorted by (id asc) into 4 buckets; <!--插入是一个mp任务--> insert overwrite table bucketed_wyp select * from wyp; dfs -ls /user/hive/warehouse/bucketed_wyp;
(这里数据之间的tab消失了,但并不是真的消失了)
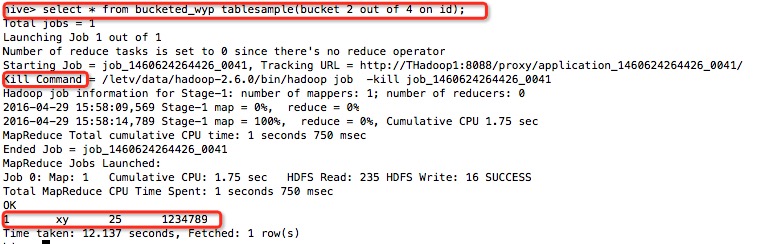
select * from bucketed_wyp tablesample(bucket 2 out of 4 on id);
(这也是一个MR任务,而且取样返回的是2/4的数据)
select * from bucketed_wyp tablesample(bucket 2 out of 4 on rand());
使用rand()之后,返回随机,但是使用了桶之后,扫描的是一部分,不使用桶,扫描的是所有的表。

相关文章推荐
- 分享Hive的一份胶片资料
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
- 将Hive的默认数据库Derby改为Postgresql
- kettle中对hive操作时需要知道的东西
- Hive安装配置
- Hive - truncate partition、drop partition 区别
- #Note# Analyzing Twitter Data with Apache Hadoo...
- 大数据实验室(大数据基础培训)——Hive的安装、配置及基础使用
- [翻译]Hive wiki GettingStarted
- hive命令积累
- 启动hive命令报错 “Metastore contains multiple versions”
- sparksql与hive整合
- hive on spark 编译
- sqoop 中文文档 User guide 一
- sqoop 中文文档 User guide 二 import
- sqoop 中文文档 User guide 二 import续
- sqoop 中文文档 User guide 三 export
- sqoop 中文文档 User guide 四 validation
- sqoop 中文文档 User guide 五 job,metastore,merge,codegen