大数据入门笔记(四)
2016-05-09 00:00
141 查看
摘要: 这是我之前学习大数据hadoop的一些笔记,今天偶尔拿出来看看,顺便上传到博客中.本篇主要是hdfs的工作机制的学习
NameNode负责管理整个文件系统的元数据
DataNode 负责管理用户的文件数据块
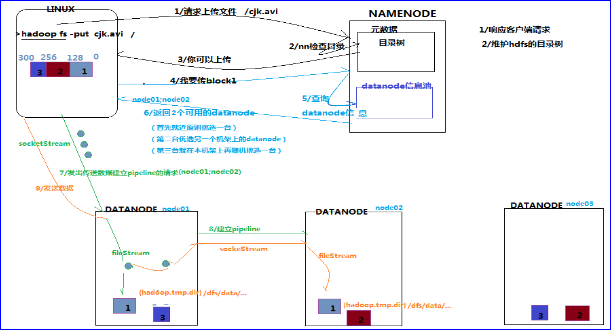
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
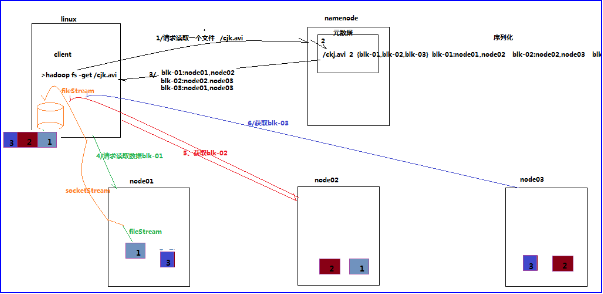
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
负责客户端请求的响应
元数据的管理(查询,修改)
---- hdfs元数据是怎么存储的?
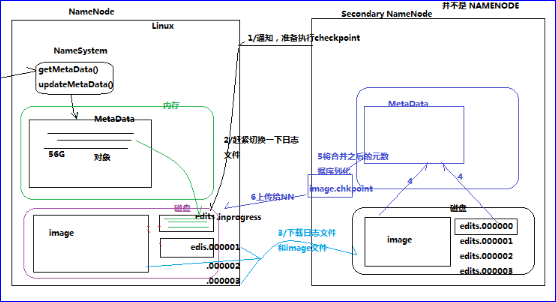
A、内存中有一份完整的元数据
B、磁盘有一个“准完整”的元数据镜像
C、当客户端对hdfs中的文件进行新增或者修改操作,响应的记录首先被记入edits这种log日志中,当客户端操作成功后,相应的元数据会更新到内存中
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
D、checkpoint操作的触发条件配置参数:
E、namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
F、可以通过hdfs的一个工具来查看edits中的信息
bin/hdfs oev -i edits -o edits.xml
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
上传一个文件,观察文件的block具体的物理存放情况
在每一台datanode机器上的这个目录:
/home/hadoop/app/hadoop-2.4.1/tmp/dfs/data/current/BP-193442119-192.168.2.120-1432457733977/current/finalized
hdfs的工作机制
HDFS集群分为两大角色:NameNode、DataNodeNameNode负责管理整个文件系统的元数据
DataNode 负责管理用户的文件数据块
HDFS写数据流程
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
HDFS读数据流程
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
namenode工作机制
namenode职责:负责客户端请求的响应
元数据的管理(查询,修改)
---- hdfs元数据是怎么存储的?
A、内存中有一份完整的元数据
B、磁盘有一个“准完整”的元数据镜像
C、当客户端对hdfs中的文件进行新增或者修改操作,响应的记录首先被记入edits这种log日志中,当客户端操作成功后,相应的元数据会更新到内存中
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
D、checkpoint操作的触发条件配置参数:
| dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary#以上两个参数做checkpoint操作时,secondary namenode的本地工作目录dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} dfs.namenode.checkpoint.max-retries=3 #最大重试次数dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录 |
F、可以通过hdfs的一个工具来查看edits中的信息
bin/hdfs oev -i edits -o edits.xml
datanode的工作机制
Datanode工作职责:存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
上传一个文件,观察文件的block具体的物理存放情况
在每一台datanode机器上的这个目录:
/home/hadoop/app/hadoop-2.4.1/tmp/dfs/data/current/BP-193442119-192.168.2.120-1432457733977/current/finalized

相关文章推荐
- Hadoop 2.x伪分布式环境搭建详细步骤
- hdu3446 daizhenyang's chess 【一般图匹配】
- 利用Gensim训练关于英文维基百科的Word2Vec模型(Training Word2Vec Model on English Wikipedia by Gensim)
- IBM Watson物联网平台的两个MQTT工具
- Andorid总结 - AIDL
- shiro中的filterChainDefinitions
- 442 - Matrix Chain Multiplication
- HDU 3420 Bus Fair(贪心)
- 下一代大数据系统和4S标准
- 大数据流式处理的利与弊
- Laxcus大数据管理系统2.0(14)- 后记
- 浅谈开源大数据平台的演变
- 【LeetCode】Factorial Trailing Zeroes 解题报告
- haartraining生成.xml文件过程
- haartraining前将统一图片尺寸方法
- 514 - Rails
- 一文读懂机器学习,大数据/自然语言处理/算法全有了
- Failed to push selection: Invalid argument
- ceph和hdfs
- Failed to load the JNI shared library jvm.dl