告别Web(二)
2016-05-08 17:17
176 查看
因为以后可能不会接触web了,我在这里不会做太多解释,不懂就去群562551358里问我把,我们可以互相交流讨论。
这个例子还是school.js, 主要自己无聊写的一个拼音检索的js插件,不过可以肯定的是没有lucene, solr很好的区分度和检索效率。
因为当时是做毕业设计,只是想着锻炼一下技能

我当时是这样做的:我那时候不知道有pin4j.jar
开始:
准备材料,网站上找到汉字拼音的数据库和高校数据库
拼音的如下:
Id hz py zm
1 啊 a a
2 阿 a a
4 埃 ai a
5 挨 ai a
高校的如下:
找不到了。。。
Id name place properties type
1 北京大学 北京 本科 综合
1 北京大学 北京 本科 综合
1 北京大学 北京 本科 综合
最后把两个数据库合成然后输出成json
{
place: “北京”
schools: [
{“id”:1,”name”:”北京大学”,”place”:”北京”,”properties”:”本科”,”type”:”综合”,”py”:”beijingdaxue”,”zm”:”bjdx”},
{“id”:2,”name”:”北京大学”,”place”:”北京”,”properties”:”本科”,”type”:”综合”,”py”:”beijingdaxue”,”zm”:”bjdx”},
]
}
其实我们不难想到:
拼音数据库中有6986个
高校数据库被我删了。。。,应该也有几千个。
Js加载一个容量大的文本是很耗时的,我那时也忘记把schools里不需要的字段propeties, type, place去掉了(减少加载成本),因为我们只需要拼音,拼音缩写和学校名字就可以了,最后再把生成的json压缩一次就更好了。
重新分析:
高校在数据库里是一行行的,但是这里你可以看到有个place,对!这样我们就可以根据place去划分整个高校数据库,你想,如果你不通过place划分,通过一行行去找的话效率是O(n),n是学校的个数,如果n是10000,m次查询,m=100,那个就光算上查询都要m*n次遍历,这样我们是不接受的,如果能通过一个place划分,那么我们找学校时就能通过place过滤掉大部分数据,而从小部分数据中快速查找。
如果用map去维护效果会更好。
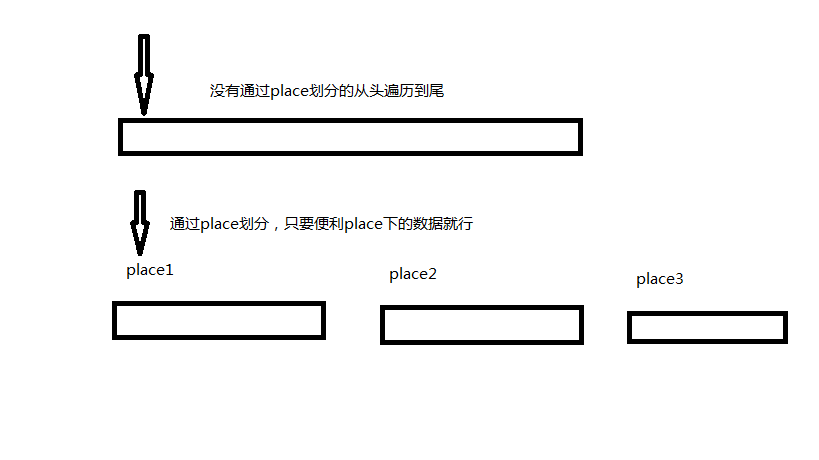
过程:
材料我们都有了而且处理好了。我那时拼音检索想法就是枚举分割点+剪枝
也是就是子集法:
以广州(guangzhou)为例:
1的二进制是00000001
2 00000010
3 00000011
所以可以把1当作我选择了在1号位置划分单词, 我用’|’表示划分
结果就是g | uangzhou
2的结果gu|angzhou
3的结果g|u|angzhou
依此类推,所以我们可以用二进制表示划分状态
现在我们看看效率
guangzhou:此时的n = 9
我们大约需要枚举1 ~ (2^9 - 1 )次^代表次方
刚好是2^9 = 512
其实O(2^n), 子集增长是指数型的,如果n<20 其实承载还行,如果n>20感觉运行起来就太吃力了2^20 = 1048576
所以剪去没有必要的搜索结果是很有用的。
guangzhou
经过分析:
u, 是不能做为头存在的,因为没有u开头的汉字。。。所以u只能和别人合并
所以只要 二进制状态 & 1 == true的过滤因为u不需要划分出来
所以gu时可以提前合并,不需要划分
可惜我当时就做了这里的过滤因为没时间搞了
后来我想到了
“a”,”ai”,”an”,”ang”,”ao”,”ba”,”bai”,”ban”,”bang”,”bao”,”bei”,”ben”,”beng”,”bi”,”bian”,”biao”,”bie”还有很多我就不写了
我们汉字组成也有一些固定格式
然后我们可以把它们做成字典树(trid)通过ac自动机进行匹配,就能过滤掉大部分没必要合并的。
最后就是一些js+css的东西了我就不说了,具体看代码school.js我要开始写java面试的东西了,可能不再弄前端了。
如果我写的不好的请帮忙指出,谢谢
这个例子还是school.js, 主要自己无聊写的一个拼音检索的js插件,不过可以肯定的是没有lucene, solr很好的区分度和检索效率。
因为当时是做毕业设计,只是想着锻炼一下技能
我当时是这样做的:我那时候不知道有pin4j.jar
开始:
准备材料,网站上找到汉字拼音的数据库和高校数据库
拼音的如下:
Id hz py zm
1 啊 a a
2 阿 a a
4 埃 ai a
5 挨 ai a
高校的如下:
找不到了。。。
Id name place properties type
1 北京大学 北京 本科 综合
1 北京大学 北京 本科 综合
1 北京大学 北京 本科 综合
最后把两个数据库合成然后输出成json
{
place: “北京”
schools: [
{“id”:1,”name”:”北京大学”,”place”:”北京”,”properties”:”本科”,”type”:”综合”,”py”:”beijingdaxue”,”zm”:”bjdx”},
{“id”:2,”name”:”北京大学”,”place”:”北京”,”properties”:”本科”,”type”:”综合”,”py”:”beijingdaxue”,”zm”:”bjdx”},
]
}
其实我们不难想到:
拼音数据库中有6986个
高校数据库被我删了。。。,应该也有几千个。
Js加载一个容量大的文本是很耗时的,我那时也忘记把schools里不需要的字段propeties, type, place去掉了(减少加载成本),因为我们只需要拼音,拼音缩写和学校名字就可以了,最后再把生成的json压缩一次就更好了。
重新分析:
高校在数据库里是一行行的,但是这里你可以看到有个place,对!这样我们就可以根据place去划分整个高校数据库,你想,如果你不通过place划分,通过一行行去找的话效率是O(n),n是学校的个数,如果n是10000,m次查询,m=100,那个就光算上查询都要m*n次遍历,这样我们是不接受的,如果能通过一个place划分,那么我们找学校时就能通过place过滤掉大部分数据,而从小部分数据中快速查找。
如果用map去维护效果会更好。
过程:
材料我们都有了而且处理好了。我那时拼音检索想法就是枚举分割点+剪枝
也是就是子集法:
以广州(guangzhou)为例:
1的二进制是00000001
2 00000010
3 00000011
所以可以把1当作我选择了在1号位置划分单词, 我用’|’表示划分
结果就是g | uangzhou
2的结果gu|angzhou
3的结果g|u|angzhou
依此类推,所以我们可以用二进制表示划分状态
现在我们看看效率
guangzhou:此时的n = 9
我们大约需要枚举1 ~ (2^9 - 1 )次^代表次方
刚好是2^9 = 512
其实O(2^n), 子集增长是指数型的,如果n<20 其实承载还行,如果n>20感觉运行起来就太吃力了2^20 = 1048576
所以剪去没有必要的搜索结果是很有用的。
guangzhou
经过分析:
u, 是不能做为头存在的,因为没有u开头的汉字。。。所以u只能和别人合并
所以只要 二进制状态 & 1 == true的过滤因为u不需要划分出来
所以gu时可以提前合并,不需要划分
可惜我当时就做了这里的过滤因为没时间搞了
后来我想到了
“a”,”ai”,”an”,”ang”,”ao”,”ba”,”bai”,”ban”,”bang”,”bao”,”bei”,”ben”,”beng”,”bi”,”bian”,”biao”,”bie”还有很多我就不写了
我们汉字组成也有一些固定格式
然后我们可以把它们做成字典树(trid)通过ac自动机进行匹配,就能过滤掉大部分没必要合并的。
最后就是一些js+css的东西了我就不说了,具体看代码school.js我要开始写java面试的东西了,可能不再弄前端了。
如果我写的不好的请帮忙指出,谢谢

相关文章推荐
- java-WEB中的监听器Lisener
- GUI - Web前端开发框架
- Extjs4.0 最新最全视频教程
- MyEclipse Web Project转Eclipse Dynamic Web Project
- axis备忘
- 创业如何选择WEB开发语言
- Erlang实现的一个Web服务器代码实例
- 防止网页脚本病毒执行的方法-from web
- 自学成才的秘密:115个 web Develop 资源
- 使用批处理修改web打印设置笔记 适用于IE
- Apache Web让JSP“动”起来
- web下载的ActiveX控件自动更新
- 推荐六款WEB上传组件性能测试与比较第1/10页
- 关于三种主流WEB架构的思考
- 使用 Iisext.vbs 列出 Web 服务扩展文件的方法
- 使用 Iisext.vbs 删除 Web 服务扩展文件的方法
- 使用 iisext.vbs 禁用 Web 服务扩展的方法
- 用vbs 实现从剪贴板中抓取一个 URL 然后在浏览器中打开该 Web 站点
- web标准知识——从p开始,循序渐进
- web标准知识――用途相似的标签