算法基础 - 最长回文子串
2016-05-06 04:11
399 查看
回文串
今天来说下最长回文串,首先回文串是:abccba或者
acbca这种正反读起来都是一样的字符串,有奇偶之分,在于有没有中间单独的这个字符。
传统解法
传统解法就是从头遍历整个字符串,把每个字符当做是奇数个数回文串的中心节点,或偶数个回文串的左中心节点。然后向左向右遍历,得到最长回文长度,记下来,然后遍历下一个字符。这个解法的时间复杂度是O(n^2) 空间复杂度是O(1)。
这里有个问题就是,假如我的字符串是:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab
难道要计算这么多次?
这里有个简化操作,就是中心是相同的时候,一直走,把所有相同的字符算作是中心,下次遍历的时候,直接略过这个中间就好了。
传统代码1
class Solution{
public:
string longestPalindrome(string s){
int i = 0;
int max = 1;
int temp = 0;
int temp1 = 1;
string result = s.substr(0,1);
for (i = 0; i < s.length(); i++) {
while (s[i-temp/2] == s[i+1+temp/2]) {
temp += 2;
}
while (s[i-temp1/2] == s[i+2+temp1/2]) {
temp1 += 2;
}
temp = temp>temp1?temp:temp1;
if (temp > max) {
max = temp;
result = s.substr(i-temp/2+1, max);
}
temp = 0;
temp1 = 1;
}
return result;
}
};简化操作传统代码2
class Solution {
public:
string longestPalindrome(string s1) {
if(s1.size() < 2)
return s1;
int k = 0, j = 0, i = 0, longest = 1, st = 0;
while(k < s1.size() - longest/2){
j = k;
while(s1[k] == s1[k+1])
++k;//这里简化了一些相同操作
i = k;
while(k < s1.size() && j >0 && s1[k+1] == s1[j-1]){
++k;
--j;
}
if(k-j+1 > longest){
longest = k-j+1;
st = j;
}
k = i + 1;
}
return s1.substr(st,longest);
}
};好, 到这里我们已经基本简化了一些了,但是还不够,因为以上代码还都是O(n^2)的解决办法。
Manacher’s 算法
引用一下维基百科的内容:To find in linear time a longest palindrome in a string, an algorithm may take advantage of the following characteristics or observations about a palindrome and a sub-palindrome:
The left side of a palindrome is a mirror image of its right side.
(Case 1) A third palindrome whose center is within the right side of a first palindrome will have exactly the same length as that of a second palindrome anchored at the mirror center on the left side, if the second palindrome is within the bounds of the first palindrome by at least one character.
(Case 2) If the second palindrome meets or extends beyond the left bound of the first palindrome, then the third palindrome is guaranteed to have at least the length from its own center to the right outermost character of the first palindrome. This length is the same from the center of the second palindrome to the left outermost character of the first palindrome.
To find the length of the third palindrome under Case 2, the next character after the right outermost character of the first palindrome would then be compared with its mirror character about the center of the third palindrome, until there is no match or no more characters to compare.
(Case 3) Neither the first nor second palindrome provides information to help determine the palindromic length of a fourth palindrome whose center is outside the right side of the first palindrome.
It is therefore desirable to have a palindrome as a reference (i.e., the role of the first palindrome) that possesses characters furtherest to the right in a string when determining from left to right the palindromic length of a substring in the string (and consequently, the third palindrome in Case 2 and the fourth palindrome in Case 3 could replace the first palindrome to become the new reference).
Regarding the time complexity of palindromic length determination for each character in a string: there is no character comparison for Case 1, while for Cases 2 and 3 only the characters in the string beyond the right outermost character of the reference palindrome are candidates for comparison (and consequently Case 3 always results in a new reference palindrome while Case 2 does so only if the third palindrome is actually longer than its guaranteed minimum length).
For even-length palindromes, the center is at the boundary of the two characters in the middle.
通过以上内容,详细的没弄明白,但是有一点要明白的是:这个解法是接近O(n)的。
hihocoder上有一些解释 方便的可以自己看一下。
大致是说,对于当前的回文串的比较位置,可以从之前的回文串中找到一些信息,类似于KMP的next数组,如果当前遇到的
max > i那么就可以从
max处开始比较。
算法基本要点:首先用一个非常巧妙的方式,将所有可能的奇数/偶数长度的回文子串都转换成了奇数长度:在每个字符的两边都插入一个特殊的符号。比如 abba 变成 #a#b#b#a#, aba变成 #a#b#a#。 为了进一步减少编码的复杂度,可以在字符串的开始加入另一个特殊字符,这样就不用特殊处理越界问题,比如$#a#b#a#。
然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向左/右扩张的长度
S # 1 # 2 # 2 # 1 # 2 # 3 # 2 # 1 # P 1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1
这里的
S数组是从1开始的,也就是
#.然后下面对应的
P[i]大小。可以看到
P[i]-1就是
S[i]位置的回文串长度。
下面计算P[i],该算法增加两个辅助变量id和mx,其中id表示最大回文子串中心的位置,mx则为id+P[id],也就是最大回文子串的边界。
这个算法的关键点就在这里了:如果
mx > i,那么
P[i] >= MIN(P[2 * id - i], mx - i)。
if(mx > i){
p[i] = max(p[2*id - i] , (mx - i));
}else{
p[i] = 1;
}可以看到当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i 和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。
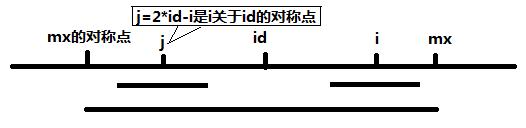
当 P[j] > mx - i 的时候,以S[j]为中心的回文子串不完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] >= mx - i。至于mx之后的部分是否对称,就只能一个一个匹配了。
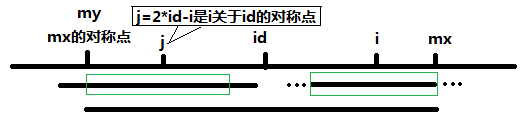
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了
为什么是O(N)
这里可以看到,每次比较的开端是mx,而mx是在一直增长的,所以最终mx增长到终点的时候,比较就结束了。
代码实现O(N)
#include<iostream>
#include<cstring>
#include<vector>
#include<string>
using namespace std;
string solve(string str){
string resStr;
int len = (int)str.length();
vector<char> S(2*len+2);
vector<int> P(2*len+2, 0);
S[0] = '$';
S[1] = '#';
for(int i = 0; i < len; i++){
S[(i+1)*2] = str[i];
S[(i+1)*2+1] = '#';
}
int id = 0, maxVal = 0;
int res = 0, loc = 0;;
for(int i = 1; i < S.size(); i++){
if(maxVal > i){
P[i] = min(P[id*2-i], maxVal -i);
}else{
P[i] = 1;
}
while(S[i-P[i]] == S[i+P[i]]){
P[i]++;
}
if(i + P[i] > maxVal){
id = i;
maxVal = id + P[id];
}
if(P[i] > res){
res = P[i];
loc = i;
}
}
//如果想要长度而已
//return res-1;
int start = loc-res+2;
int end = loc+res-2;
for(int i = start; i <= end; i++){
if(S[i] == '#') continue;
else resStr += S[i];
}
return resStr;
}
int main(){
int N;
cin>>N;
string s;
while(N--){
cin>>s;
cout<<solve(s)<<endl;
}
}以上图片部分内容参考:
http://www.cnblogs.com/biyeymyhjob/archive/2012/10/04/2711527.html

相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法
- 基于C++实现的各种内部排序算法汇总
- C++线性时间的排序算法分析
- C++实现汉诺塔算法经典实例
- PHP实现克鲁斯卡尔算法实例解析