codeforces 667C C. Reberland Linguistics(dp)
2016-05-02 14:41
323 查看
题目链接:
C. Reberland Linguistics
time limit per test
1 second
memory limit per test
256 megabytes
input
standard input
output
standard output
First-rate specialists graduate from Berland State Institute of Peace and Friendship. You are one of the most talented students in this university. The education is not easy because you need to have fundamental knowledge in different areas, which sometimes are not related to each other.
For example, you should know linguistics very well. You learn a structure of Reberland language as foreign language. In this language words are constructed according to the following rules. First you need to choose the "root" of the word — some string which has more than 4 letters. Then several strings with the length 2 or 3 symbols are appended to this word. The only restriction — it is not allowed to append the same string twice in a row. All these strings are considered to be suffixes of the word (this time we use word "suffix" to describe a morpheme but not the few last characters of the string as you may used to).
Here is one exercise that you have found in your task list. You are given the word s. Find all distinct strings with the length 2 or 3, which can be suffixes of this word according to the word constructing rules in Reberland language.
Two strings are considered distinct if they have different length or there is a position in which corresponding characters do not match.
Let's look at the example: the word abacabaca is given. This word can be obtained in the following ways:
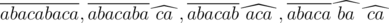
, where the root of the word is overlined, and suffixes are marked by "corners". Thus, the set of possible suffixes for this word is {aca, ba, ca}.
Input
The only line contains a string s (5 ≤ |s| ≤ 104) consisting of lowercase English letters.
Output
On the first line print integer k — a number of distinct possible suffixes. On the next k lines print suffixes.
Print suffixes in lexicographical (alphabetical) order.
Examples
input
output
input
output
Note
The first test was analysed in the problem statement.
In the second example the length of the string equals 5. The length of the root equals 5, so no string can be used as a suffix.
题意:
给一个字符串,去掉一个长度至少为5的前缀,剩下的切成长度为2或者3的串,且相邻的串不相同,问,最后可以切成多少个串且分别是什么;
思路:
dp[i][2]==1表示i,i+1形成的串可以满足要求,dp[i][3]==1同理;再就是转移了;
考虑i位置,长度为2;
(1)如果<i,i+1>与<i+2,i+3>相同,那么只有dp[i+2][3]==1时dp[i][2]=1;
如果<i,i+1>与<i+2,i+3>不同,那么只要dp[i+2][2]==1或者dp[i+2][3]==1时dp[i][2]=1;
(2)如果<i,i+1,i+2>与<i+3,i+4,i+5>相同,只有dp[i+3][2]==1时dp[i][3]=1;
如果不同,那么只要dp[i+3][2]==1或者dp[i+3][3]==1时dp[i][3]=1;
AC代码:
C. Reberland Linguistics
time limit per test
1 second
memory limit per test
256 megabytes
input
standard input
output
standard output
First-rate specialists graduate from Berland State Institute of Peace and Friendship. You are one of the most talented students in this university. The education is not easy because you need to have fundamental knowledge in different areas, which sometimes are not related to each other.
For example, you should know linguistics very well. You learn a structure of Reberland language as foreign language. In this language words are constructed according to the following rules. First you need to choose the "root" of the word — some string which has more than 4 letters. Then several strings with the length 2 or 3 symbols are appended to this word. The only restriction — it is not allowed to append the same string twice in a row. All these strings are considered to be suffixes of the word (this time we use word "suffix" to describe a morpheme but not the few last characters of the string as you may used to).
Here is one exercise that you have found in your task list. You are given the word s. Find all distinct strings with the length 2 or 3, which can be suffixes of this word according to the word constructing rules in Reberland language.
Two strings are considered distinct if they have different length or there is a position in which corresponding characters do not match.
Let's look at the example: the word abacabaca is given. This word can be obtained in the following ways:
, where the root of the word is overlined, and suffixes are marked by "corners". Thus, the set of possible suffixes for this word is {aca, ba, ca}.
Input
The only line contains a string s (5 ≤ |s| ≤ 104) consisting of lowercase English letters.
Output
On the first line print integer k — a number of distinct possible suffixes. On the next k lines print suffixes.
Print suffixes in lexicographical (alphabetical) order.
Examples
input
abacabaca
output
3 aca ba ca
input
abaca
output
0
Note
The first test was analysed in the problem statement.
In the second example the length of the string equals 5. The length of the root equals 5, so no string can be used as a suffix.
题意:
给一个字符串,去掉一个长度至少为5的前缀,剩下的切成长度为2或者3的串,且相邻的串不相同,问,最后可以切成多少个串且分别是什么;
思路:
dp[i][2]==1表示i,i+1形成的串可以满足要求,dp[i][3]==1同理;再就是转移了;
考虑i位置,长度为2;
(1)如果<i,i+1>与<i+2,i+3>相同,那么只有dp[i+2][3]==1时dp[i][2]=1;
如果<i,i+1>与<i+2,i+3>不同,那么只要dp[i+2][2]==1或者dp[i+2][3]==1时dp[i][2]=1;
(2)如果<i,i+1,i+2>与<i+3,i+4,i+5>相同,只有dp[i+3][2]==1时dp[i][3]=1;
如果不同,那么只要dp[i+3][2]==1或者dp[i+3][3]==1时dp[i][3]=1;
AC代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N=1e4+10;
const LL mod=1e9+7;
const double PI=acos(-1.0);
char str
;
int dp
[4];
map<string,int>mp;
vector<string>ve;
int main()
{
scanf("%s",str);
int n=strlen(str);
string x,y="";
int ans=0;
for(int i=n-2;i>4;i--)
{
if(n-i==2)
{
x=y+str[i]+str[i+1];
mp[x]=1;
ve.push_back(x);
dp[i][2]=1;
}
else if(n-i==3)
{
x=y+str[i]+str[i+1]+str[i+2];
mp[x]=1;
ve.push_back(x);
dp[i][3]=1;
}
else if(n-i==4)
{
if(str[i]!=str[i+2]||str[i+1]!=str[i+3])
{
x=y+str[i]+str[i+1];
if(!mp[x])
{
mp[x]=1;
ve.push_back(x);
}
dp[i][2]=1;
}
else
{
x=y+str[i]+str[i+1];
dp[i][2]=0;
}
}
else
{
if(str[i]==str[i+2]&&str[i+1]==str[i+3])
{
if(dp[i+2][3]){
dp[i][2]=1;
x=y+str[i]+str[i+1];
if(!mp[x])
{
mp[x]=1;
ve.push_back(x);
}
}
}
else
{
if(dp[i+2][2]||dp[i+2][3])
{
dp[i][2]=1;
x=y+str[i]+str[i+1];
if(!mp[x])
{
mp[x]=1;
ve.push_back(x);
}
}
}
if(str[i]==str[i+3]&&str[i+1]==str[i+4]&&str[i+2]==str[i+5])
{
if(dp[i+3][2])
{
dp[i][3]=1;
x=y+str[i]+str[i+1]+str[i+2];
if(!mp[x])
{
mp[x]=1;
ve.push_back(x);
}
}
}
else
{
if(dp[i+3][3]||dp[i+3][2])
{
dp[i][3]=1;
x=y+str[i]+str[i+1]+str[i+2];
if(!mp[x])
{
mp[x]=1;
ve.push_back(x);
}
}
}
}
}
ans=ve.size();
sort(ve.begin(),ve.end());
printf("%d\n",ans);
for(int i=0;i<ans;i++)
{
cout<<ve[i]<<"\n";
}
}

相关文章推荐
- UVa 1594 Ducci Sequence
- leetcode-62. Unique Paths
- POJ 1141 Brackets Sequence 括号匹配 区间DP
- java concurrent 之 SynchronousQueue
- [费用流 线段树] BZOJ 3267 KC采花 && 3272 Zgg吃东西 && 3638 Cf172 k-Maximum Subsequence Sum
- POJ3080 Blue Jeans
- Android群英传笔记——第十二章:Android5.X 新特性详解,Material Design UI的新体验
- C# Queue源码剖析
- Leetcode #347. Top K Frequent Elements 前K高频数 解题报告
- 使用Retrofit时出现 java.lang.IllegalArgumentException: URL query string "t={type}&p={page}&size={count}" must not have replace block. For dynamic query parameters use @Query.异常原因
- CodeForces 666A Reberland Linguistics(DP)
- CodeForces 666A Reberland Linguistics(DP)
- HNOI2016 序列(sequence)<莫队>
- 1382 - The Queue
- NSNotification在UITextField的应用
- UItableview 添加 uisearchController
- [leetcode] 347. Top K Frequent Elements 解题报告
- Storyboard实现界面跳转
- Unique Paths II
- 纯java代码设置简单UI界面