ELK安装使用
2016-05-01 00:00
232 查看
摘要: ELK安装使用
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
1、安装 Logstash 依赖包 JDK
jdk必须为1.7及其以上,安装过程省略。
2、安装 Logstash
下载并安装 Logstash ,安装 logstash 只需将它解压的对应目录即可,例如:/usr/local 下:
安装完成后运行如下命令:
测试:
我们可以看到,我们输入什么内容logstash按照某种格式输出,其中-e参数参数允许Logstash直接通过命令行接受设置。这点尤其快速的帮助我们反复的测试配置是否正确而不用写配置文件。使用CTRL-C命令可以退出之前运行的Logstash。
使用-e参数在命令行中指定配置是很常用的方式,不过如果需要配置更多设置则需要很长的内容。这种情况,我们首先创建一个简单的配置文件,并且指定logstash使用这个配置文件。 例如:在 logstash 安装目录下创建一个“基本配置”测试文件logstash-test.conf, 文件内容如下:
Logstash 使用 input 和 output 定义收集日志时的输入和输出的相关配置,本例中input 定义了一个叫 "stdin" 的 input , output 定义一个叫 "stdout" 的 output 。无论我们输入什么字符, Logstash 都会按照某种格式来返回我们输入的字符,其中 output 被定义为 "stdout" 并使用了 codec 参数来指定 logstash 输出格式。
使用logstash的-f参数来读取配置文件,执行如下开始进行测试:
3、安装 Elasticsearch
下载Elasticsearch:
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
1、安装 Logstash 依赖包 JDK
jdk必须为1.7及其以上,安装过程省略。
2、安装 Logstash
下载并安装 Logstash ,安装 logstash 只需将它解压的对应目录即可,例如:/usr/local 下:
# 下载 > wget https://download.elastic.co/logstash/logstash/logstash-2.3.2.tar.gz # 解压 > tar -zxf logstash-1.5.2.tar.gz -C /usr/local/
安装完成后运行如下命令:
> /usr/local/logstash-1.5.2/bin/logstash -e 'input { stdin { } } output { stdout {} }'
# 运行结果
Logstash startup completed测试:
> Hello World! # 输出 2015-07-15T03:28:56.938Z noc.vfast.com Hello World!
我们可以看到,我们输入什么内容logstash按照某种格式输出,其中-e参数参数允许Logstash直接通过命令行接受设置。这点尤其快速的帮助我们反复的测试配置是否正确而不用写配置文件。使用CTRL-C命令可以退出之前运行的Logstash。
使用-e参数在命令行中指定配置是很常用的方式,不过如果需要配置更多设置则需要很长的内容。这种情况,我们首先创建一个简单的配置文件,并且指定logstash使用这个配置文件。 例如:在 logstash 安装目录下创建一个“基本配置”测试文件logstash-test.conf, 文件内容如下:
# cat logstash-simple.conf input { stdin { } }
output {
stdout { codec=> rubydebug }
}Logstash 使用 input 和 output 定义收集日志时的输入和输出的相关配置,本例中input 定义了一个叫 "stdin" 的 input , output 定义一个叫 "stdout" 的 output 。无论我们输入什么字符, Logstash 都会按照某种格式来返回我们输入的字符,其中 output 被定义为 "stdout" 并使用了 codec 参数来指定 logstash 输出格式。
使用logstash的-f参数来读取配置文件,执行如下开始进行测试:
# 输入 > echo "`date` hello World" # 运行结果 Thu Jul 16 04:06:48 CST 2015 hello World
# 输入 > /usr/local/logstash-2.3.2/bin/logstash agent -f logstash-simple.conf # 运行结果 Logstash startup completed
# 输入
> Tue Jul 14 18:07:07 EDT 2015 hello World #该行是执行echo “`date`hello World” 后输出的结果,直接粘贴到该位置
# 输出
{ "message" => "Tue Jul 14 18:07:07 EDT 2015 helloWorld", "@version" => "1", "@timestamp" => "2015-07-14T22:07:28.284Z", "host" => "noc.vfast.com" }3、安装 Elasticsearch
下载Elasticsearch:
> wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.2/elasticsearch-2.3.2.tar.gz[/code] 解压:> tar -zxf elasticsearch-2.3.2.tar.gz -C /usr/local/
启动 Elasticsearch> /usr/local/elasticsearch-2.3.2/bin/elasticsearch
如果使用远程连接的 Linux 的方式并想后台运行 elasticsearch 执行如下命令:> nohup /usr/local/elasticsearch-1.6.0/bin/elasticsearch >nohup &
确认 elasticsearch 的 9200 端口已监听,说明 elasticsearch 已成功运行netstat -anp |grep :9200tcp 0 0 :::9200 :::* LISTEN 3362/java
接下来我们在 logstash 安装目录下创建一个用于测试 logstash 使用 elasticsearch 作为 logstash 的后端的测试文件 logstash-es-simple.conf,该文件中定义了stdout和elasticsearch作为output,这样的“多重输出”即保证输出结果显示到屏幕上,同时也输出到elastisearch中。cat logstash-es-simple.confinput { stdin { } } output { elasticsearch {host => "localhost" } stdout { codec=> rubydebug } }
执行如下命令> /usr/local/logstash-1.5.2/bin/logstash agent -f logstash-es-simple.conf Logstash startup completed # 输入 hello logstash # 输出 { "message" => "hello logstash", "@version" => "1", "@timestamp" => "2015-07-15T18:12:00.450Z", "host" => "noc.vfast.com"}
我们可以使用 curl 命令发送请求来查看 ES 是否接收到了数据:> curl 'http://localhost:9200/_search?pretty' # 返回结果 { "took": 58, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits": { "total" : 1, "max_score" : 1.0, "hits" : [ { "_index" : "logstash-2015.07.15", "_type" : "logs", "_id" : "AU6TWiixxDXYhySMyTkP", "_score" : 1.0, "_source":{"message":"hellologstash","@version":"1","@timestamp":"2015-07-15T20:13:55.199Z","host":"noc.vfast.com"} } ] } }
至此,你已经成功利用 Elasticsearch 和 Logstash 来收集日志数据了。
4、安装 Elasticsearch 插件
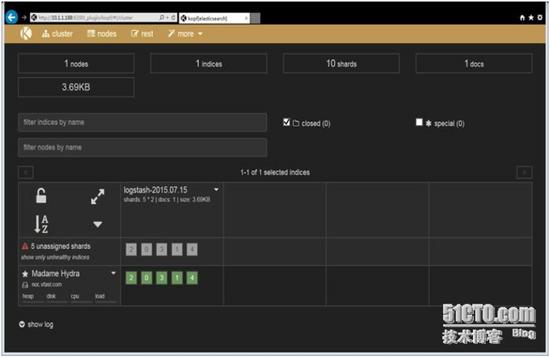
Elasticsearch-kopf 插件可以查询 Elasticsearch 中的数据,安装 elasticsearch-kopf ,只要在你安装 Elasticsearch 的目录中执行以下命令即可:# cd /usr/local/elasticsearch-1.6.0/# ./plugin -install lmenezes/elasticsearch-kopf
安装完成后在 plugins 目录下可以看到 kopf# ls plugins/kopf
在浏览器访问 http://10.1.1.188:9200/_plugin/kopf 浏览保存在 Elasticsearch 中的数据,如下所示:
5、安装 Kibana
下载 kibana 后,解压到对应的目录就完成 kibana 的安装# tar -zxf kibana-4.1.1-linux-x64.tar.gz -C /usr/local/
启动 kibana# /usr/local/kibana-4.1.1-linux-x64/bin/kibana
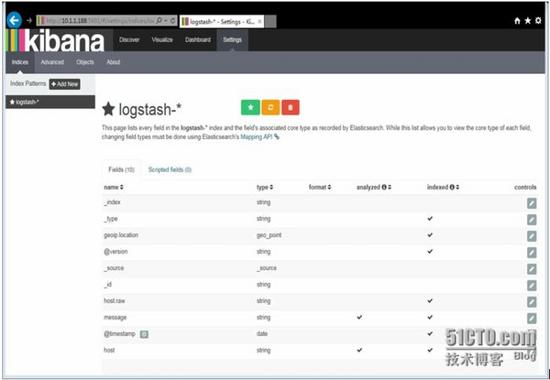
使用 http://kibanaServerIP : 5601 访问 Kibana ,登录后,首先,配置一个索引,默认, Kibana 的数据被指向 Elasticsearch ,使用默认的 logstash-* 的索引名称,并且是基于时间的,点击“ Create ”即可。
看到如下界面说明索引创建完成。
点击“ Discover ”,可以搜索和浏览 Elasticsearch 中的数据,默认搜索的是最近 15 分钟的数据。可以自定义选择时间。
到此,说明你的 ELK 平台安装部署完成。
6、配置 logstash 作为 Indexer
将 logstash 配置为索引器,并将 logstash 的日志数据存储到 Elasticsearch ,本范例主要是索引本地系统日志。# cat /usr/local/logstash-1.5.2/logstash-indexer.confinput { file { type =>"syslog" path => ["/var/log/messages", "/var/log/syslog" ] } syslog { type =>"syslog" port =>"5544" } } output { stdout { codec=> rubydebug } elasticsearch {host => "localhost" } }# /usr/local/logstash-1.5.2/bin/logstash -flogstash-indexer.conf
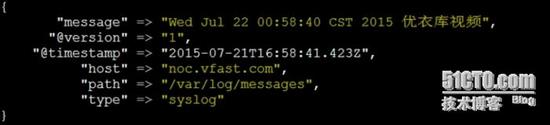
使用 echo 命令模拟写入日志,命令执行后看到如下图的信息# echo "`date` 优衣库视频" >>/var/log/messages
刷新 kibana ,发现最新的测试数据显示到浏览器中,如下图所示:
到此, ELK 平台部署和基本的测试已完成。




相关文章推荐
- hibernate 关于联合主键
- Bestcoder #82 Div2 ztr loves lucky numbers(next_permutation)
- Commission
- Selenium 测百度
- Centos7 修改运行级别
- Unity3d之Animation(动画系统)
- 该不该详细打日志
- 又开始折腾装 Linux 虚拟机了
- centos下postgresql安装使用
- Linux test 命令
- 课外书
- 浅谈提高团队成员的工作积极性
- 数据库学习总结-1
- 方法的使用与内存操作
- 数组
- 在 Python 3.4 上安装 OpenCV
- 情不知所起,一“网”而深
- 对象数组、集合、链表(java基础知识十五)
- Ubuntu14.04 Opencv2.4.9交叉编译
- sql编程小结