如何构建第一个Spark项目代码
2016-04-28 16:52
288 查看
如何构建第一个Spark项目代码
环境准备
本地环境
操作系统Window7/Mac
IDE
IntelliJ IDEA Community Edition 14.1.6
下载地址
JDK 1.8.0_65
下载地址
Scala 2.11.7
下载地址
其它环境
Spark:1.4.1下载地址
Hadoop Yarn:Hadoop 2.5.0-cdh5.3.2
IDE项目创建
新建一个项目
New Project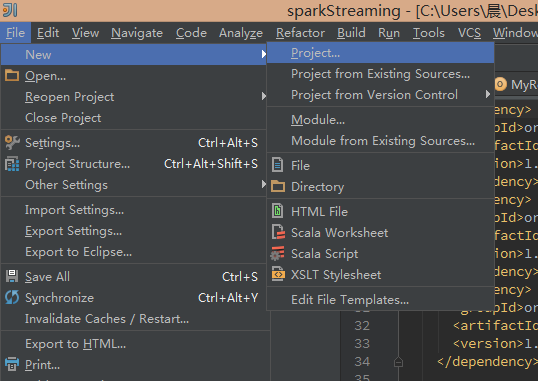
使用Maven模型创建一个Scala项目
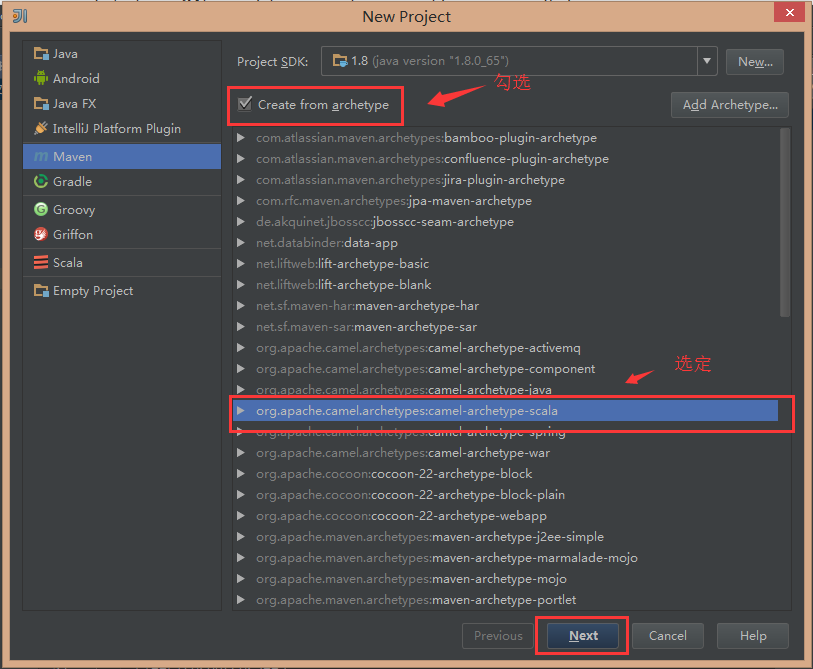
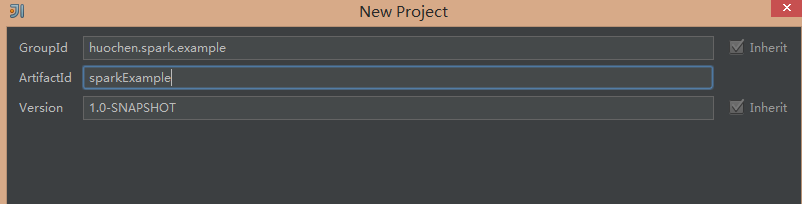
填写自己的GroupId、ArtifactId,Version不需要修改,Maven会根据GroupId生成相应的目录结构,GroupId的取值一般为a.b.c 结构,ArtifactId为项目名称。之后点击next,填写完项目名称和目录,点击finish就可以让maven帮你创建Scala项目
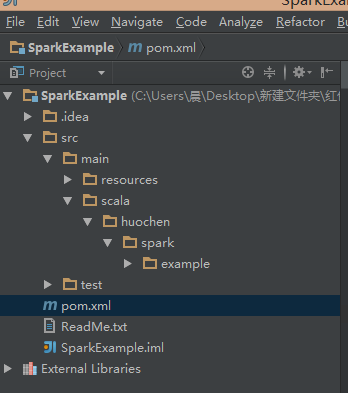
项目创建完成后,目录结构如下
4.为项目添加JDK以及Scala SDK
点击File->Project Structure,在SDKS和Global Libraries中为项目配置环境。
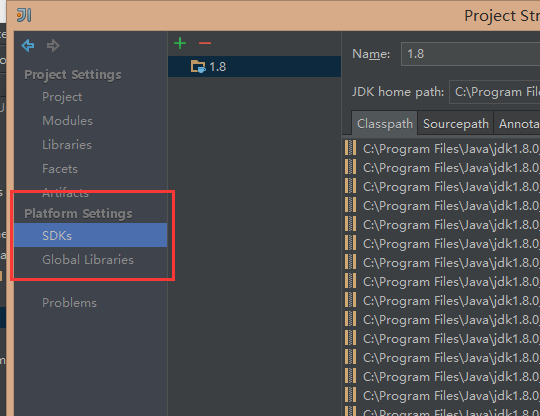
至此整个项目结构、项目环境都搭建好了
编写主函数
主函数的编写在 projectName/src/main/scala/…/下完成,如果按照上述步骤完成代码搭建,将在目录最后发现MyRouteBuild MyRouteMain
这两个文件为模块文件,删除
MyRouteBuild,重命名
MyRouteMain为
DirectKafkaWordCount。这里,我使用Spark Streaming官方提供的一个代码为实例代码,代码如下
package org.apache.spark.examples.streaming
import kafka.serializer.StringDecoder
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.SparkConf
object DirectKafkaWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("...")
System.exit(1)
}
//StreamingExamples.setStreamingLogLevels()
val Array(brokers, topics) = args
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
// Get the lines, split them into words, count the words and print
val lines = messages.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}将代码最上面的
package org.apache.spark.examples.streaming,替换为
DirectKafkaWordCount里的
package部分即可。并覆盖
DirectKafkaWordCount文件。
至此Spark处理代码已经编写完成。
修改pom.xml
,为项目打包做准备
pom.xml中编写了整个项目的依赖关系,这个项目中我们需要导入一些
Spark Streaming相关的包。
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.4.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.4.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.4.1</version> </dependency> <!-- scala --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.10.4</version> </dependency>
除此之外,如果需要把相关依赖打包到最终
JAR包中,需要在
pom.xml的bulid标签中写入以下配置:
<plugins> <!-- Plugin to create a single jar that includes all dependencies --> <plugin> <artifactId>maven-assembly-plugin</artifactId> <version>2.4</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.0.2</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins>
pom.xml文件修改完成后,即可开始maven打包,操作如图:
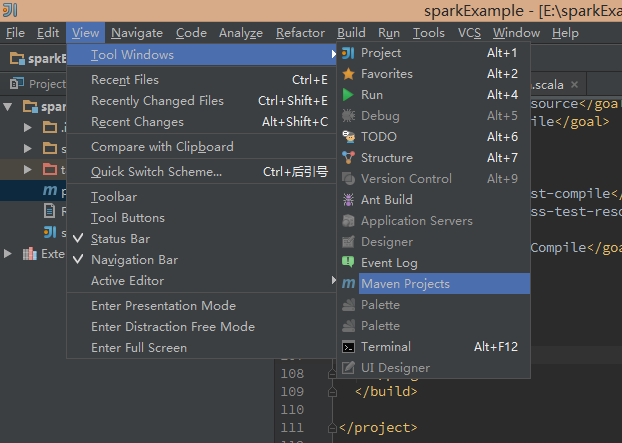
点击右侧弹出窗口的Execute Maven Goal,在
command line中输入
clean package
Spark作业提交
在项目projectname/target目录下即可找到两个
jar包,其中一个仅包含Scala代码,另一个包含所有依赖的包。
将
jar包导到Spark服务器,运行Spark作业,运行操作如下
../bin/spark-submit –master yarn-client –jars ../lib/kafka_2.10-0.8.2.1.jar –class huochen.spark.example.DirectKafkaWordCount sparkExample-1.0-SNAPSHOT-jar-with-dependencies.jar kafka-broker topic
利用
spark-submit把任务提交到Yarn集群,即可看到运行结果。
Q&A
带有依赖的jar包有80+M,似乎加上了许多没用的依赖包,这是正常情况还是由于pom.xml配置错误导致的?
Reference
Spark Streaming + Kafka Integration Guidehttp://spark.apache.org/docs/1.4.1/streaming-kafka-integration.html
Running Spark on YARN
http://spark.apache.org/docs/1.4.1/running-on-yarn.html

相关文章推荐
- eclipse链接hadoop2.5.1时报错Error:Call From roo/10.30.12.xxx to hostname1:9000 failed on connection excep
- vb中几种循环
- C++与Lua5.3.2的相互调用
- [原创] 如何用Eclispe调试java -jar xxx.jar 方式执行的jar包
- Java链表的简单实现
- Eclipse 的单步调试
- Java分布式通信之RMI
- c++第四次作业
- Spring学习笔记--导航
- 「C语言」int main还是void main?
- 2016年4月28日VB 求给定一个正整数的二进制数
- java.lang.ClassCastException: java.lang.Character cannot be cast to java.lang.String|<s:property val
- java 实现Excel数据导入数据库时,中文乱码问题
- SpringMVC+jade实现高性能模板引擎(简单配置)
- c++第四次作业
- PHP+IIS心得
- java中命令模式
- [LeetCode]题解(python):140-Word Break II
- 将十进制数转换成二进制数
- 深入浅出学Spring Data JPA