机器学习中怎样的特征才是好特征
2016-04-28 12:56
190 查看
讲座视频:What Makes a Good Feature? - Machine Learning Recipes #3
https://www.youtube.com/watch?v=N9fDIAflCMY
分类器只有在你使用好的feature时,才能有好的性能。提供或找出好的feature是使用机器学习时的最重要工作之一。
假设要对狗的类别进行分类,区分是greyhound还是labrador。

我们考虑两个特征,身高(inches)和眼睛颜色。
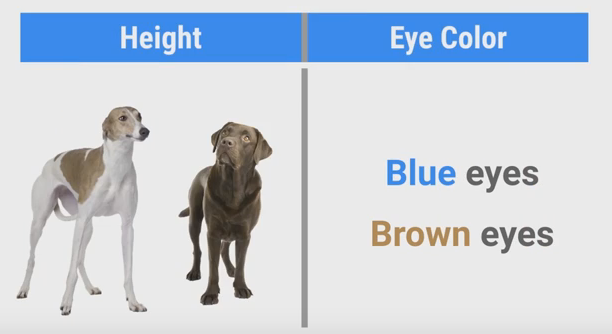
我们这里假设这两种狗眼睛只有blue和brown两种颜色。
我们先分析特征身高。
通常情况下,greyhound要比labrador高,但现实世界会比较复杂,两种狗的身高都在一个范围内变化。
我们用python写些代码来生成随机的身高数据,其中,greyhound平均身高为28,labrador平均身高为24。我们画出直方图。红色是greyhound,蓝色是labrador。

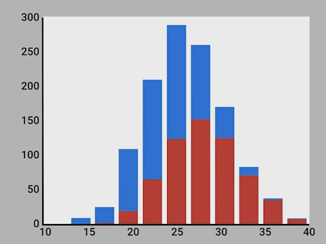
我们来分析这张直方图。先看左边,比如,身高为20 inches时,如果要估计这种身高的狗,我们应该认为它是labrador,因为这种身高情况下,80%可能性是labrador,而只有20%可能性是greyhound。再看右边,比如,身高为35 inches时,这时95%的可能性是greyhound,所以,我们应该估计这种情况下的狗为greyhound。
但是,我们也注意到中间部分,比如25 inches处,在这些地方,两种狗的可能性相差不大,所以身高为这些值时,很难区分。
所以,身高是一个useful的feature,但不perfect。
如果要找出你应该用什么样的特征,那你可以做一个模拟的思考实验,假设你自己就是分类器,你现在试图区分一条狗是greyhound,还是labrador,你希望知道其他一些什么东西?你可能会问:它们头发的稀疏程度怎么样?它们跑的速度怎么样?它们多重?
事实上,应该用多少特征,更多一种art,而不是一种science。但从经验上来说,你自己需要多少特征来分类,那么分类器可能也需要多少。
现在再来看另一个特征,眼睛的颜色。我们假设两种狗都只有2种颜色:Blue和Brown,且狗的颜色和它品种无关。
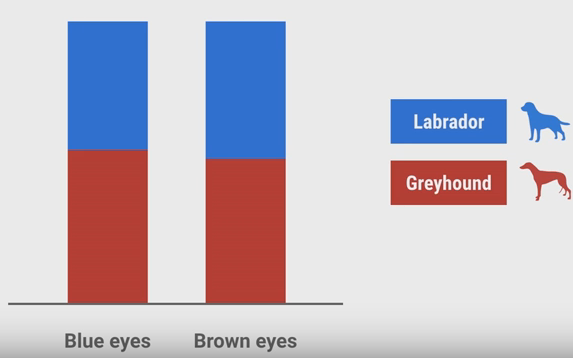
它的直方图统计结果可能像上图一样。这张图没有告诉我们任何东西,因为两种颜色下,两种狗的可能性都差不多,所以,狗的颜色也是没有用的特征。如果在使用分类器时,加入了这样没用的特征,那么,会影响分类器的分类准确性。这样的特征可能会看起来有用,但仅仅是因为数据本身的偶然性。特别是当你的训练数据非常少的情况下,更可能使你错误地认为这样的特征有用。
而且,我们应该使用相互independent的特征。因为相互independent的特征能给你不用角度的信息。例如,你在数据中已经有了以inches表示的身高,如果再加入以cm表示的身高就没有意义,因为提供不了更多的信息。你应该尽量去掉类似的冗余的特征,因为很多分类器很敏感,遇见这样高度相关的特征时,它会错误地认为这个特征更加重要,这显然不是我们所希望的。
此外,我们应该使用容易理解的特征。比如,我们现在要预测从一个城市寄一个纸质mail,要多少天才能到另一个城市。显然,两个城市越远,花的天数越多。
这里,城市之间的英里数miles就是一个非常好的特征。还有一种很差的选择是使用两个城市的坐标:

从人理解的角度来说,知道miles很容易估计出天数,而仅仅知道坐标就不太容易估计。而如果使用坐标这样难理解的特征,你会比使用容易理解的特征需要使用多得多的数据来训练分类器。
总结一下,理想的特征应该是:
1) Informative,有信息的;
2) Independent,与其他特征相独立的;
3) Simple,简单容易理解的。
https://www.youtube.com/watch?v=N9fDIAflCMY
分类器只有在你使用好的feature时,才能有好的性能。提供或找出好的feature是使用机器学习时的最重要工作之一。
假设要对狗的类别进行分类,区分是greyhound还是labrador。
我们考虑两个特征,身高(inches)和眼睛颜色。
我们这里假设这两种狗眼睛只有blue和brown两种颜色。
我们先分析特征身高。
通常情况下,greyhound要比labrador高,但现实世界会比较复杂,两种狗的身高都在一个范围内变化。
我们用python写些代码来生成随机的身高数据,其中,greyhound平均身高为28,labrador平均身高为24。我们画出直方图。红色是greyhound,蓝色是labrador。
我们来分析这张直方图。先看左边,比如,身高为20 inches时,如果要估计这种身高的狗,我们应该认为它是labrador,因为这种身高情况下,80%可能性是labrador,而只有20%可能性是greyhound。再看右边,比如,身高为35 inches时,这时95%的可能性是greyhound,所以,我们应该估计这种情况下的狗为greyhound。
但是,我们也注意到中间部分,比如25 inches处,在这些地方,两种狗的可能性相差不大,所以身高为这些值时,很难区分。
所以,身高是一个useful的feature,但不perfect。
如果要找出你应该用什么样的特征,那你可以做一个模拟的思考实验,假设你自己就是分类器,你现在试图区分一条狗是greyhound,还是labrador,你希望知道其他一些什么东西?你可能会问:它们头发的稀疏程度怎么样?它们跑的速度怎么样?它们多重?
事实上,应该用多少特征,更多一种art,而不是一种science。但从经验上来说,你自己需要多少特征来分类,那么分类器可能也需要多少。
现在再来看另一个特征,眼睛的颜色。我们假设两种狗都只有2种颜色:Blue和Brown,且狗的颜色和它品种无关。
它的直方图统计结果可能像上图一样。这张图没有告诉我们任何东西,因为两种颜色下,两种狗的可能性都差不多,所以,狗的颜色也是没有用的特征。如果在使用分类器时,加入了这样没用的特征,那么,会影响分类器的分类准确性。这样的特征可能会看起来有用,但仅仅是因为数据本身的偶然性。特别是当你的训练数据非常少的情况下,更可能使你错误地认为这样的特征有用。
而且,我们应该使用相互independent的特征。因为相互independent的特征能给你不用角度的信息。例如,你在数据中已经有了以inches表示的身高,如果再加入以cm表示的身高就没有意义,因为提供不了更多的信息。你应该尽量去掉类似的冗余的特征,因为很多分类器很敏感,遇见这样高度相关的特征时,它会错误地认为这个特征更加重要,这显然不是我们所希望的。
此外,我们应该使用容易理解的特征。比如,我们现在要预测从一个城市寄一个纸质mail,要多少天才能到另一个城市。显然,两个城市越远,花的天数越多。
这里,城市之间的英里数miles就是一个非常好的特征。还有一种很差的选择是使用两个城市的坐标:
从人理解的角度来说,知道miles很容易估计出天数,而仅仅知道坐标就不太容易估计。而如果使用坐标这样难理解的特征,你会比使用容易理解的特征需要使用多得多的数据来训练分类器。
总结一下,理想的特征应该是:
1) Informative,有信息的;
2) Independent,与其他特征相独立的;
3) Simple,简单容易理解的。

相关文章推荐
- 智能防火墙的技术特征
- ES6中非常实用的新特性介绍
- AngularJS 2.0新特性有哪些
- JavaScript中关联原型链属性特性
- Java面向对象的三大特征
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- 反向传播(Backpropagation)算法的数学原理
- 关于SVM的那点破事
- 也谈 机器学习到底有没有用 ?
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程所有目录
- 如何用70行代码实现深度神经网络算法
- 量子计算机编程原理简介 和 机器学习
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 已经证实提高机器学习模型准确率的八大方法
- 初识机器学习算法有哪些?
- 机器学习相关的库和工具