深入分析HaspMap源码
2016-04-24 21:43
519 查看
1.分析HaspMap的构造器
前面分析HashMap的put(K key,V value)源码的时候发现,其中有两个特殊的变量:size:该变量保存了该HashMap中所包含的key-value对的数量。
threshold:该变量包含了HashMap能容纳的key-value对的极限,它的值等于HashMap的容量乘以负载因子(load factor)。
在HashMap的addEntry方法中,当size++>=threshold时。HashMap会自动调用resize方法扩充HashMap的容量。但每扩充一次,HashMap的容量就增大一倍。
HashMap源码中存在一个就table的数组。这个数组的长度其实就是HashMap的容量。HashMap包含如下几个构造器:
HashMap() 初始容量为16。负载因子为0.75的HashMap。
HashMap(int initialCapacity) 构建一个初始容量为 initialCapacity,负载因子为0.75的HashMap
HashMap(int initialCapacity,float loadFactor) 构建指定初始容量和负载因子的HashMap
当创建一个HasMap时,系统会自动创建一个table数组来保存HashMap中的Entry。
观察构造器的源码:
//以指定初始化容量,负载因子创建HashMap
public HashMap(int initialCapacity, float loadFactor) {
//初始容量不能为负数
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//初始容量不能太大
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子必须大于0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//计算出大于initialCapacity的最小的2的n次方值
int capacity = 1;
while(capacity<initialCapacity)
capacity<<=1;
this.loadFacotor = loadFactor;
//设置容量极限等于容量乘以负载因子
threshold = (int)(capacity * loadFactor);
//初始化table数组
table = new Entry(capacity);
init();
}注意观察下面这两段代码:
int capacity = 1; while(capacity<initialCapacity) capacity<<=1;
找出大于initialCapacity的,最小的2的n次方值,并将其作为HashMap的实际容量。例如给定initialCapacity为10,那么HashMap的实际容量就是16。通常来说,HaspMap最后的实际容量通常比initialCapacity大一点,除非它刚好是2的n次方,所以我们在创建HaspMap需要指定容量时指定为2的n次方可以减少不必要的开销。
补充:
<<把数据向左移动。移除的删除,右边用0补齐 相当于乘以2的移动次幂
>>把数据向右移动。移除的删除 ,左边用最高位补齐 相当于除以2的移动次幂
2.HashMap根据key取出value
对于HashMap及其子类而言,它们采用Hash算法来决定集合中元素的存储位置。当系统开始初始化HashMap时,系统会创建一个长度为Capacity的Entry的数组。这个数组里可以存储元素的位置被称为”桶(bucket)”,每个bucket都有其特定的索引,系统可以根据其索引快速访问该bucket里存储的元素。一般情况下,bucket里存储的是单个Entry,但也有会生成Entry链的情况(即两个key的hash值相同但equals返回false)。当bucket里面存储的是单个Entry,此时HaspMap性能最好。当程序需要根据key取出value时,只需要计算出key的hash值,再根据该hash值找出key在table数组中的索引,然后取出该索引处的Entry,最后返回该Entry的value即可。下面我们来看HashMapget(K key)的源码:
public V get(Object key) {
//如果key是null。调用getForNullKey
if (key == null)
return getForNullKey();
//计算key的hash值
int hash = hash(key.hashCode());
//直接取出table数组中的指定索引处的值
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
//搜索下一个Entry
e = e.next) {
Object k;
//如果该Entry的key与被搜索key相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}从上面代码可以看出,当HashMap的每个bucket里只有一个Entry,HaspMap可以快速从bucket里取出Entry。在发生”Hash冲突”的情况下,单个bucket里存储的不是一个Entry,而是Entry链,此时系统只能通过遍历每个Entry,直到找到搜索的Entry为止。
总结一下:
HaspMap在底层把一个KEy-Value当成一个整体Entry对象来处理。
HaspMap底层通过一个Entry[]数组来保存所有的key-value对。
对于每一个要存储的key-value,系统通过Hash算法确定其存储位置。
当需要取出一个Entry时,也会根据Hash值来找到其在数组中存储位置
再谈负载因子loadFactor:
HaspMap有一个默认的负载因子值0.75。这是时间和空间成本上的一种折衷:
增大负载因子可以减少Hash表(就是那个Entry[]数组)所占用内存空间,但会增大查询数据的时间开销,而查询是最频繁的操作(HashMap的get()和put()都要查询)
减少负载因子可以会提高数据查询的性能,但会增加Hash表所占用的内存空间。
现在我们合理的调整负载因子的值了。如果程序比较关心内存的开销,适当增加负载因子。如果比较关心时间开销,则适当减小负载因子,其实大部分情况下保持负载因子默认的0.75即可。
多线程环境下,使用HashMap进行put操作引起的问题分析
在多线程的环境下,多个线程对HashMap数据进行put操作时会导致死循环。而造成这个原因的罪魁祸首就是因为HashMap的自动扩容机制。
我们来观察HashMap的put过程
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//当key为null,调用putForNullKey来处理
if (key == null)
return putForNullKey(value);
//根据key的hashCode计算hash值
int hash = hash(key);
//搜索制定hash值在对于table中的索引
int i = indexFor(hash, table.length);
//如果i处索引不为null。则通过循环不断遍历e元素的下一个元素
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//找到指定key与需要放入key相等(即两者hash值相同,equals返回true)
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//如果i索引处的entry为null。表明此次没有entry。直接插入在此次即可
modCount++;
//添加key,value到索引i处
addEntry(hash, key, value, i);
return null;
}现在我们可以看出:当程序试图将一个key-value对放入HashMap中时,首先根据key的hashCode()返回值决定该Entry的存储位置,如果两个key的hash值相同,那么它们的存储位置相同。如果这个两个key的equalus比较返回true。那么新添加的Entry的value会覆盖原来的Entry的value,key不会覆盖。如果这两个equals返回false,那么这两个Entry会形成一个Entry链,并且新添加的Entry位于Entry链的头部。
观察
addEntry(hash, key, value, i);源码:
void addEntry(int hash, K key, V value, int bucketIndex) {
//获取指定bucketIndex处的Entry
Entry<K,V> e = table[bucketIndex];
//将新创建的Entry放入bucketIndex索引处,并让新Entry指向原来的Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//如果Map中的key-value对的数量超过了极限
if(size++>=threshold){
//扩充table对象的长度到2倍
resize(2*table.length);
}
}现在我们看罪魁祸首的resize方法的源码:
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//复制旧数据到新数组中:
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}复制旧数据到新数组中源码:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
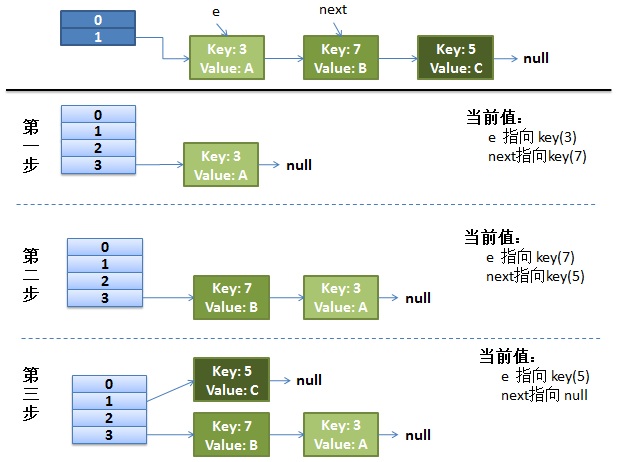
}画了个图做了个演示。
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的
<key,value>重新rehash的过程
多线程下的rehash:
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);而我们的线程二执行完成了。于是我们有下面的这个样子。
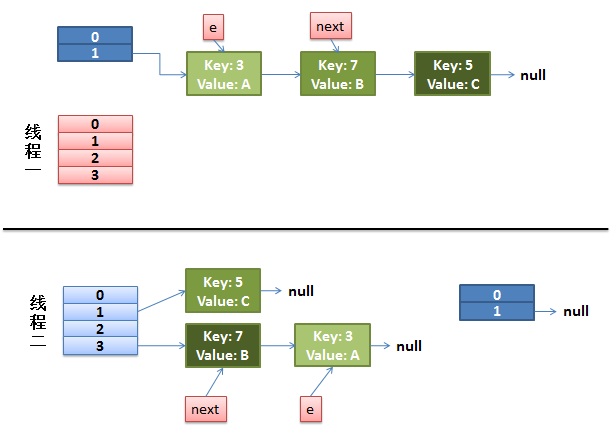
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
先是执行 newTalbe[i] = e;
然后是e = next,导致了e指向了key(7),
而下一次循环的next = e.next导致了next指向了key(3)
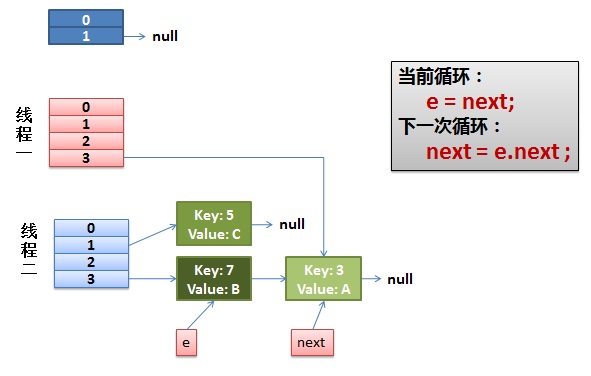
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
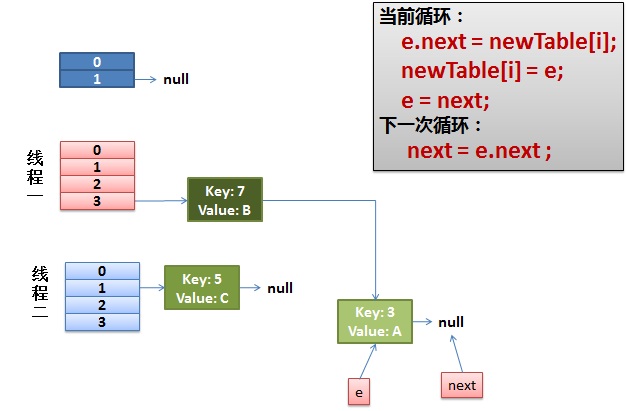
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
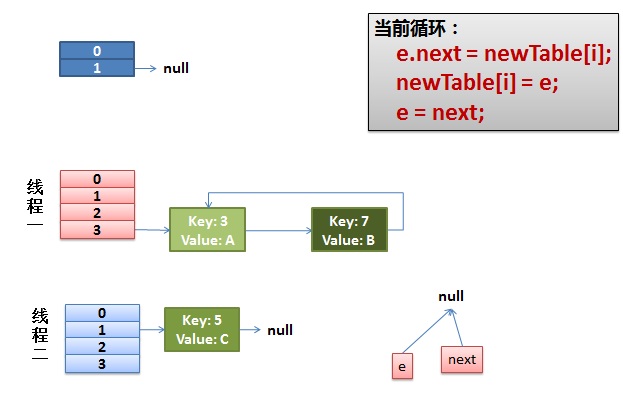
于是,悲剧出现了。next不为null。陷入while死循环。
参考:http://coolshell.cn/articles/9606.html

相关文章推荐
- 写自己的ASP.NET MVC框架(上)
- 细说ASP.NET Forms身份认证
- ASP.NET初始
- 【转载】IIS如何设置可以让.aspx后缀的文件直接下载
- Asp.net初识
- ASP.NET自定义模块
- Aspose.words合并文档、邮件合并功能
- AspectJ 出现错误::0 can't find referenced pointcut 的解决之道
- ASP.Net MVC开发基础学习笔记(1):走向MVC模式
- ASP.NET MVC 网站开发总结(二)——一个或多个文件的异步或同步上传
- ASP.NET MVC 网站开发总结(一)
- ASP.NET Core的配置(3): 将配置绑定为对象
- Asp.net 面向接口可扩展框架之核心容器
- ASP.NET自定义处理程序
- Repeat和AspNetPager控件
- Asp.net Mvc 使用EF6 code first 方式连接MySQL总结
- ASP.NET MVC之下拉框绑定四种方式(十)
- VS2013设置护眼背景颜色
- ASP漏洞+SQL注入的入侵方法
- ASP漏洞+SQL注入的入侵方法