80秒验证13亿个身份证号码,包含省市县验证
2016-04-23 17:21
295 查看
我写了一个验证身份证号码的程序,它是以一定内存空间(大概100M)换取cpu消耗,然后它的运算量就降低了,前十四位的验证就相当于转换类型再查表一样,所以它的验证号码速度比一般的方式快。如果还不明白就说明你写框架写多了,或者你不了解java基础。测试结果只代表算法效率,测一个号码是因为正确号码运算次数基本相同,如果你们用自己的电脑测,13亿次循环应该不到1分钟。这种设计思路,也可以套用其他格式信息验证上去。
先说一下具体思路:首先,身份证号的前6位是全国行政区划代码(就是省市县连起来的代码),我就把国家统计局的2004-2013年的全部代码拿过来,用程序分析,除掉五六位为00的,总共3000+,为了以尽量少的方式存放在代码里,我就用程序分析出每个不间断的序列,首尾成对地存放在数组里面,如110111,110118 表示110111到1101117,然后用布尔数组存储到对应下标,有这个代码,对应下标为true。然后年月日也是这个原理,先用循环生成所有的日期的可能性然后把值减去19000101(就是上一个百年虫日期),用样存放到布尔数组里面。最后验证校验码以及前17位是否为数字,18位是否为数字或者X。
再说一下身份证校验码,第18位的校验方法:
(1)十七位数字本体码加权求和
公式 S = Sum(Ai * Wi), i = 0, ... , 16 ,先对前17位数字的权求和
Ai:表示第i位置上的身份证号码数字值
Wi:表示第i位置上的加权因子
Wi: 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2
(2)计算模 Y = mod(S, 11)
(3)通过模得到对应的校验码
Y: 0 1 2 3 4 5 6 7 8 9 10
校验码: 1 0 X 9 8 7 6 5 4 3 2
这个用循环就能做到了。
另外,用switch-case语句比if-esle快,这大概都知道吧。
然后说一下数据查询效率,方式有:数组位图(array),BitSet,二分法,HashSet
查询时间:array≈bitSet <二分法 <HashSet
空间消耗:bitSet>array >二分法 >HashSet
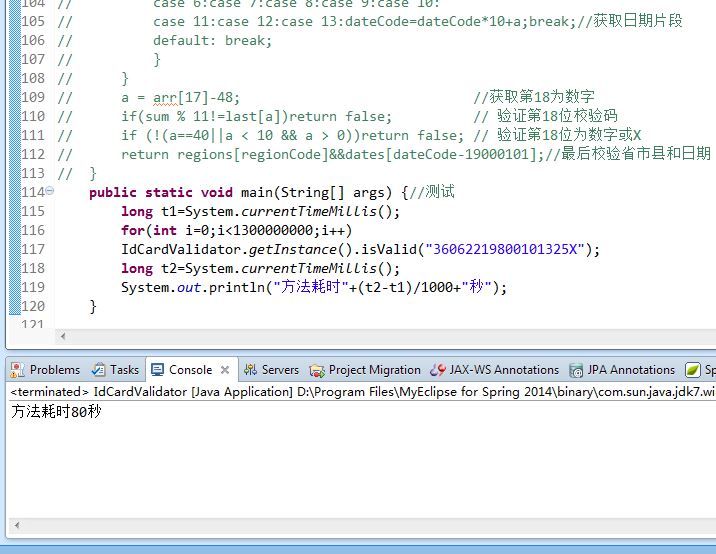
所以我用array存储数据做查询,然后运行效率大概就是 在i3本子上面100秒查完全国人民的身份证号码。
今天把循环去掉,换成最基本的运算式子,结果为80秒执行完13亿次验证,但是越高效的代码越不人性化。
请不要讨论连接公安网数据库问题,因为这个程序起的作用是高速过滤器,验证通过再查询数据库,不通过就滤掉了。更不要说查询一次数据库比几十次整点运算快,它们是两个层面的,如果硬要比的话,对于一个身份证号码来说,查询数据库肯定比cpu运行几十次整点运算慢的多,而且差几个数量级
先说一下具体思路:首先,身份证号的前6位是全国行政区划代码(就是省市县连起来的代码),我就把国家统计局的2004-2013年的全部代码拿过来,用程序分析,除掉五六位为00的,总共3000+,为了以尽量少的方式存放在代码里,我就用程序分析出每个不间断的序列,首尾成对地存放在数组里面,如110111,110118 表示110111到1101117,然后用布尔数组存储到对应下标,有这个代码,对应下标为true。然后年月日也是这个原理,先用循环生成所有的日期的可能性然后把值减去19000101(就是上一个百年虫日期),用样存放到布尔数组里面。最后验证校验码以及前17位是否为数字,18位是否为数字或者X。
再说一下身份证校验码,第18位的校验方法:
(1)十七位数字本体码加权求和
公式 S = Sum(Ai * Wi), i = 0, ... , 16 ,先对前17位数字的权求和
Ai:表示第i位置上的身份证号码数字值
Wi:表示第i位置上的加权因子
Wi: 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2
(2)计算模 Y = mod(S, 11)
(3)通过模得到对应的校验码
Y: 0 1 2 3 4 5 6 7 8 9 10
校验码: 1 0 X 9 8 7 6 5 4 3 2
这个用循环就能做到了。
另外,用switch-case语句比if-esle快,这大概都知道吧。
然后说一下数据查询效率,方式有:数组位图(array),BitSet,二分法,HashSet
查询时间:array≈bitSet <二分法 <HashSet
空间消耗:bitSet>array >二分法 >HashSet
所以我用array存储数据做查询,然后运行效率大概就是 在i3本子上面100秒查完全国人民的身份证号码。
今天把循环去掉,换成最基本的运算式子,结果为80秒执行完13亿次验证,但是越高效的代码越不人性化。
请不要讨论连接公安网数据库问题,因为这个程序起的作用是高速过滤器,验证通过再查询数据库,不通过就滤掉了。更不要说查询一次数据库比几十次整点运算快,它们是两个层面的,如果硬要比的话,对于一个身份证号码来说,查询数据库肯定比cpu运行几十次整点运算慢的多,而且差几个数量级
1. [代码]IdCardValidator.java
?2. [图片] IdCardValid.JPG

相关文章推荐
- 【转】Struts1和Struts2的区别比较
- motto10
- 最长公共子序列问题
- MySQL 数据库 练习题
- 编程之美精确表达浮点数
- 工厂模式
- MySQL 数据库 常用函数
- 使用TexturePackerGUI配合NGUI打包图集
- 中外饮食类英语单词大全
- 背包问题-堆栈-找出其中一组解(总体积为T,n件物品体积分别是w1,w2,...,w2n,找出若干件恰好装满背包)
- Android Services 创建一个Bound服务
- 团队开发——个人工作总结05
- 全局侧滑
- 欢迎使用CSDN-markdown编辑器
- Eclipse下Genymotion模拟器的安装
- 有赞搜索引擎实践(算法篇)
- ArcGIS Desktop 高(新)版本数据库迁移到较低(旧)版本数据库操作方法
- Less函数说明
- 343. Integer Break 【M】
- 【BZOJ1194】[HNOI2006]潘多拉的盒子【BFS】【SCC】【拓扑排序】【DAG最长路】【自动机】