VMware Hadoop2.5.2分布式环境搭建
2016-04-22 23:18
856 查看
1. Centos安装
主流虚拟机软件有VirtualBox和Vmware workstation,后者为商用软件,主推后者,对于这两款软件的使用,在本文中就不赘述了,不会的同学可以参考https://github.com/judasn/Linux-Tutorial/blob/master/CentOS-Install.md(judasn整理了很多学习资料,在这向他学习致敬)2. 虚拟网络配置
使用VMware安装完centos之后我们需要先配置虚拟网络。编辑à虚拟网络编辑器

打开
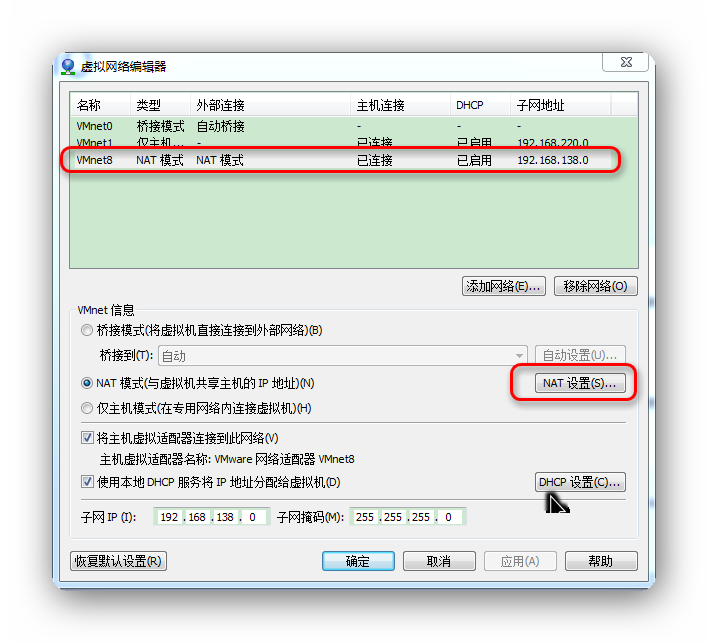
打开NAT设置如图:

把红框中的几个ip地址记录下来,后面会需要用到。需要注意的是数值可能和图中会不一致。
到这一步还需要确认关键步骤,也是最容易忽略的步骤:
第一:网络连接选择NAT模式
打开虚拟机à设置
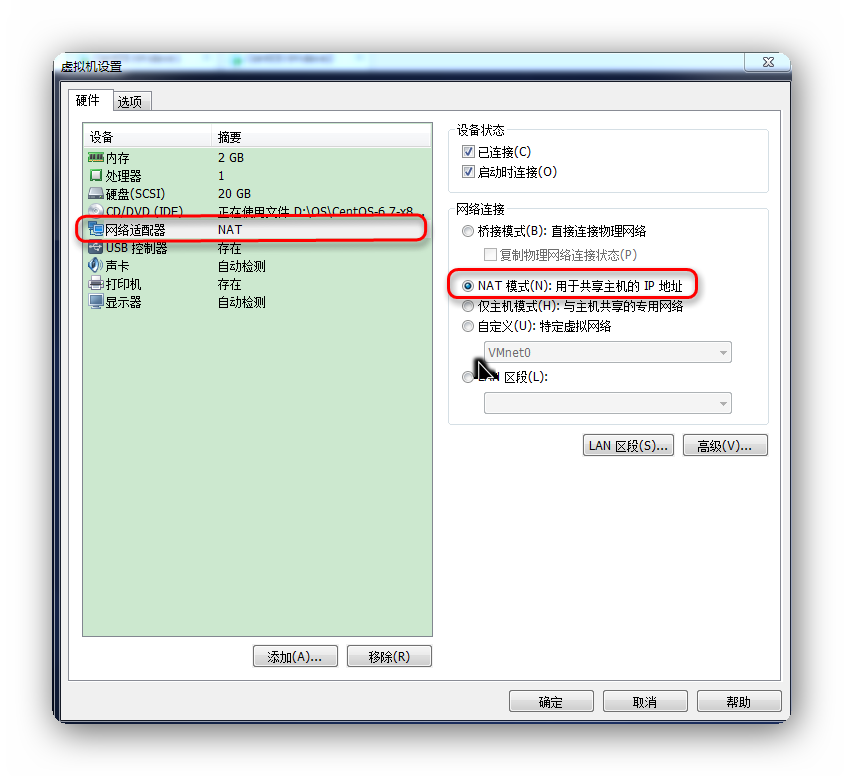
第二:启动Vmware相关服务
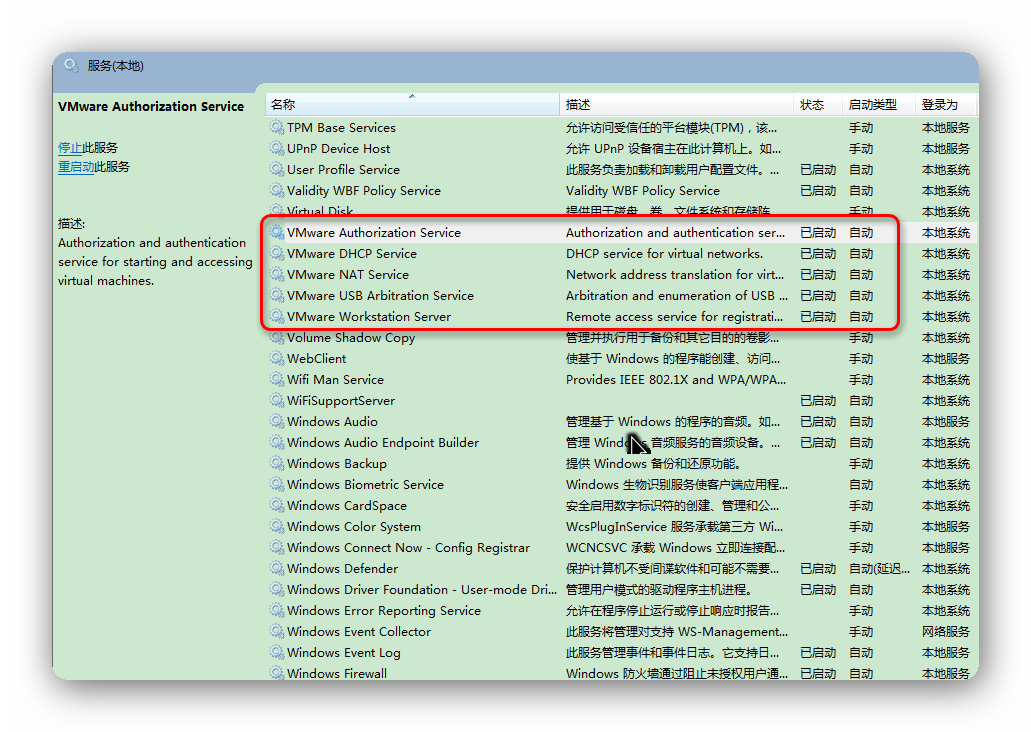
到现在为止,就可以启动虚拟机了。
3. 防火墙参数配置
使用root帐号登录虚拟机关闭SELINUX:vi /etc/selinux/config 设置SELINUX=disabled,保存退出
修改IP配置:vi /etc/sysconfig/network-scripts/ifcfg-eth0 修改为如下图:
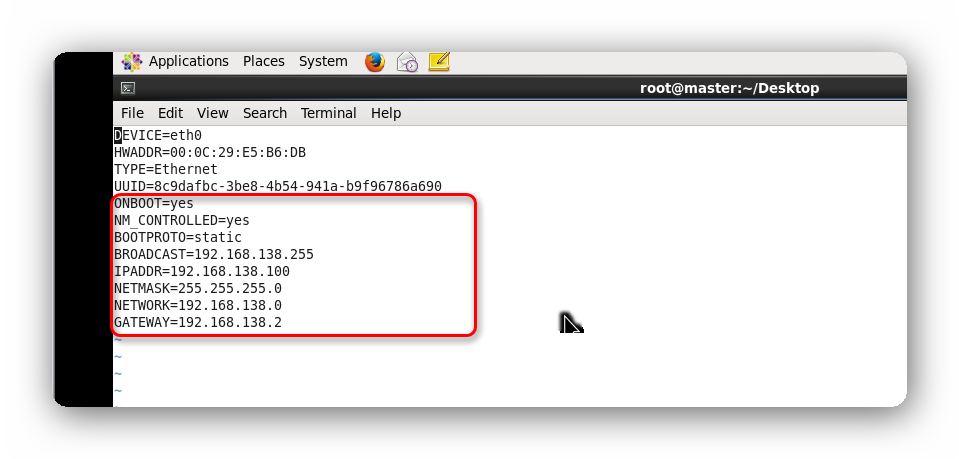
注意子网IP,子网掩码,网关IP为前面记录的几个值,HWADDR(本机MAC地址)、UUID值无需修改,
修改主机名称:vi /etc/sysconfig/network 如下图:修改HOSTNAME值为master

修改hosts映射:vi /etc/hosts,加入了slave1和slave2的映射项,将其内容改为如下图所示。

关闭防火墙:/sbin/service iptables stop;chkconfig --level 35 iptables off
重启网络策略:service network restart
到这一步我们就可以使用ssh工具连接到我们的虚拟机了,使用Putty、Xshell、SecureCRT等工具都行,在这我使用Xshell+Winscp
4. JDK安装
使用SSH工具连接上虚拟机之后,通过FTP上传下载好的jdk安装文件。下载地址:http://pan.baidu.com/s/1pLEJ9bl先卸载:
查看系统中是否安装了jdk:
# rpm -qa | grep jdk
# rpm -qa | grep gcj
可能会出现:
jdk-1.7.0_45-fcs.x86_64
如果存在执行命令进行卸载:
# yum -y remove jdk-1.7.0_45-fcs.x86_64
下载jdk-7u79-linux-x64.rpm
给所有用户添加可执行的权限
# chmod +x jdk-7u79--linux-x64-rpm.bin
进入文件存放目录
# chmod 777 jdk-7u79--linux-x64-rpm给所有用户添加可执行的权限
安装程序
#rpm -ivh jdk-7u79--linux-x64-rpm
出现安装协议等,按接受即可。
2.设置环境变量。
#vi /etc/profile
在最后面加入
#set java environment
JAVA_HOME=/usr/java/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
保存退出。
5. Hadoop安装配置
下载hadoop2.5.2版本,下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/# tar -vxf hadoop-2.5.2/ #将下载的hadoop-2.5.2.tar.gz解压
hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以独立的Java进程来运行,节点即NameNode也是DataNode。需要修改2个配置文件etc/hadoop/core-site.xml和etc/hadoop/hdfs-site.xml。
# vim hadoop-2.5.2/etc/hadoop/core-site.xml 添加如下内容:

配置说明:添加hdfs的指定URL路径,由于是伪分布模式,所以配置的是本机IP ,可为真实Ip、localhost。
# vim hadoop-2.5.2/etc/hadoop/ hdfs-site.xml 添加如下内容:
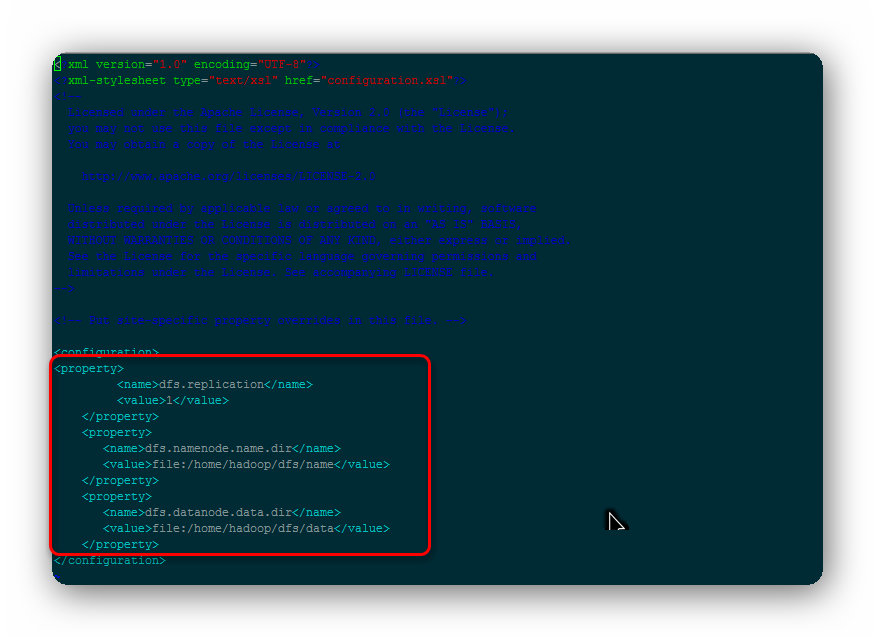
将mapred-site.xml.template重命名为mapred-site.xml,并添加如下内容:

为hadoop指定jdk:
# vim hadoop-2.5.2/etc/hadoop/hadoop-env.sh

将hadoop加入到环境变量中
# vim ~/.bashrc 添加如下内容:

到这为止,hadoop就已经配置好了。
6. 克隆虚拟机
使用VMware中克隆功能,复制出另外两台虚拟机,分别命名为slave1和slave2。因为克隆出的虚拟机网卡地址已经改变,所以要修改复制出的虚拟机的网卡地址。网卡地址查看:(注意要启动虚拟机查询)

# vim /etc/sysconfig/networking/devices/ifcfg-eth0 将其中HWADDR修改为上面新的网卡地址,同样将IPADDR改为192.168.224.201(slave1)或192.168.224.202(slave2)。
# vim /etc/sysconfig/network 修改主机名为slave1和slave2
# rm -f /etc/udev/rules.d/70-persistent-net.rules #这步非常关键
# reboot #重启虚拟机
现在就可以使用SSH工具连接三台虚拟机了
7. 配置SSH
设置免密登录,打开三台虚拟机,登录到master中,执行如下命令:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh slave1 "mkdir ~/.ssh"
scp ~/.ssh/id_dsa.pub slave1:~/.ssh/authorized_keys
ssh slave2 "mkdir ~/.ssh"
scp ~/.ssh/id_dsa.pub slave2:~/.ssh/authorized_keys
中间可能需要输入密码 ,执行完之后,分别执行如下命令
ssh master
ssh slave1
ssh slave2
不需要再输入密码就对了。
8. 启动Hadoop
首次执行需先执行HDFS格式化命令:bin/hadoop namenode –format(第二次启动就不需要了)在master虚拟机执行sbin/start-all.sh 就OK了。
成功启动后,可以通过命令jps看到启动了如下进程,master中存在NameNode、SecondaryNameNode进程,slave1和slave2中存在DataNode、NodeManager进程。
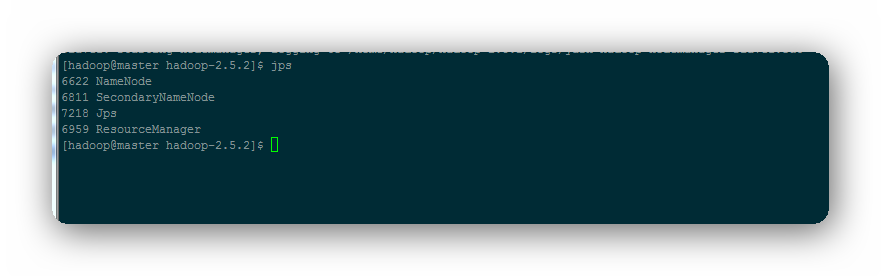


此时可以访问Web界面http://192.168.138.100:50070来查看Hadoop的信息。

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- 在 Linux 上安装 VMware 工具
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 把Chrome OS安装在VMWare下及Chrome OS的关键特性和一些截图
- 企业云 2.0:VMware 眼中的企业 IT 的未来
- 单机版搭建Hadoop环境图文教程详解
- Windows 8虚拟机不能全屏的解决方法
- VMware Workstation 5.5.3 Build 34685 汉化补丁
- hadoop常见错误以及处理方法详解
- Vmware虚拟机的安装及配置方法
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- nasm实现的用vmware运行自做的linux启动盘的引导代码
- Install ESX Server 3.5/3i onto ESX Server安装方法
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍