【机器学习】贝叶斯线性回归模型
2016-04-21 20:18
344 查看
假设当前数据为X,回归参数为W,结果为B,那么根据贝叶斯公式,可以得到后验概率:

,我们的目标是让后验概率最大化。其中pD概率是从已知数据中获取的量,视为常量;pw函数是w分布的先验信息。
令:
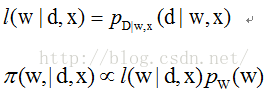
求l函数最大化的过程称为w的极大似然估计(ML),求pie函数最小化的过程称为最大后验估计(MAP)。ML没有利用w的先验信息,因此结果不如MAP好。MAP和ML计算得到的W 的结果可能不是唯一的。
我在之前的博客中推导过线性回归模型,求解该模型最终归于解决最小二乘问题。接下来的推导可以看到之前博客的简单线性模型是贝叶斯回归模型的特例。
假设样本是随机独立同分布(iid)的,误差(d-wx)服从高斯分布N(0,theta),同样假设判别向量w服从高斯分布N(0,thetaw),这里我们增加了两个强假设。带入到pie函数中有:
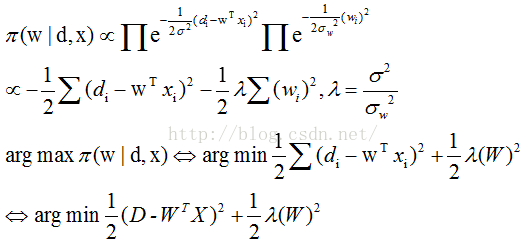
如果没有w的先验知识,那么这时候上述问题退化为最小二乘问题。有了w的先验知识,那么最小化模型就包含一个w平方项,这个平方项会利用w的先验信息,对结果进行约束,称为正则化项,这个问题是正则最小二乘问题。对w求导,令结果为零,得到最小化情况下的w值:
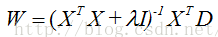
不过大量的资料显示,正则化导致了偏置-方差困境,MAP方法相比ML方法,离真实的判别参数w是一定有偏差的,想办法缩小w计算结果偏差会导致w计算结果方差变大,同时缩小偏置和方差的方法是尽可能增大样本容量。
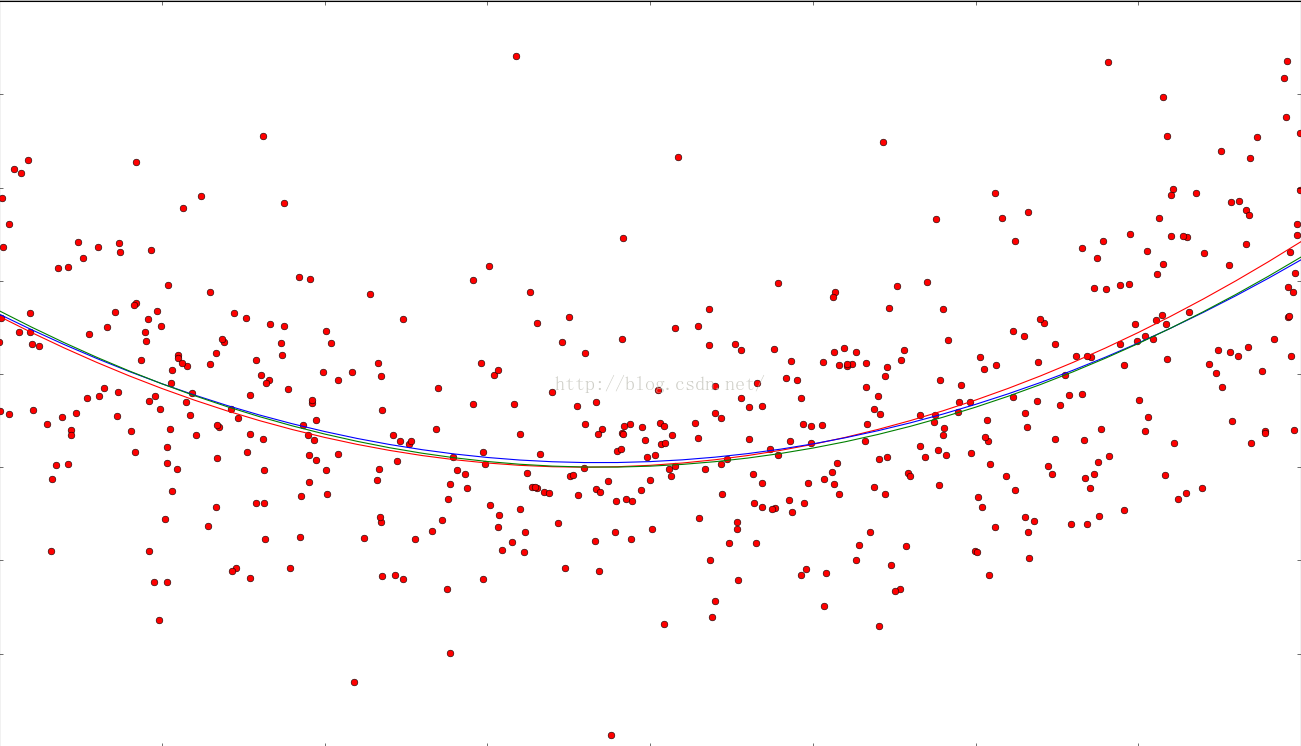
红色线是标准答案,红点是噪声数据,蓝线是线性回归结果,绿线是正则化回归结果。
https://github.com/artzers/MachineLearning.git LineaRegression 实现
,我们的目标是让后验概率最大化。其中pD概率是从已知数据中获取的量,视为常量;pw函数是w分布的先验信息。
令:
求l函数最大化的过程称为w的极大似然估计(ML),求pie函数最小化的过程称为最大后验估计(MAP)。ML没有利用w的先验信息,因此结果不如MAP好。MAP和ML计算得到的W 的结果可能不是唯一的。
我在之前的博客中推导过线性回归模型,求解该模型最终归于解决最小二乘问题。接下来的推导可以看到之前博客的简单线性模型是贝叶斯回归模型的特例。
假设样本是随机独立同分布(iid)的,误差(d-wx)服从高斯分布N(0,theta),同样假设判别向量w服从高斯分布N(0,thetaw),这里我们增加了两个强假设。带入到pie函数中有:
如果没有w的先验知识,那么这时候上述问题退化为最小二乘问题。有了w的先验知识,那么最小化模型就包含一个w平方项,这个平方项会利用w的先验信息,对结果进行约束,称为正则化项,这个问题是正则最小二乘问题。对w求导,令结果为零,得到最小化情况下的w值:
不过大量的资料显示,正则化导致了偏置-方差困境,MAP方法相比ML方法,离真实的判别参数w是一定有偏差的,想办法缩小w计算结果偏差会导致w计算结果方差变大,同时缩小偏置和方差的方法是尽可能增大样本容量。
红色线是标准答案,红点是噪声数据,蓝线是线性回归结果,绿线是正则化回归结果。
https://github.com/artzers/MachineLearning.git LineaRegression 实现

相关文章推荐
- CF 629 A组合 B暴力 Cdp D线段树优化DP
- 异或详解
- Restricted Boltzmann Machines for Collaborative Filtering(转载)
- VS 常用快捷键
- 移动端类原生开发
- POJ-2152 Fire (树形DP)
- python基础之01数据类型-变量-运算浅解
- 周总结
- 线性表
- Oracle的存储过程返回结果集
- 自定义控件实现圆形头像
- QT运行时加载UI文件产生的Designer警告
- SpringAOP拦截Controller,Service实现日志管理(自定义注解的方式)
- 车牌识别
- 抽取、转换和装载介绍(九)小结
- office安装错误,报1603
- ES6+React+Webpack初步构建项目流程
- JavaScript 浏览器对象
- C++基础知识
- python调用cmd命令的几种方式和区别