hive命令的3种调用方式
2016-04-21 11:11
309 查看
hive命令的3种调用方式
方式1:hive –f /root/shell/hive-script.sql(适合多语句)
hive-script.sql类似于script一样,直接写查询命令就行
例如:
[root@cloud4 shell]# vi hive_script3.sql
select * from t1;
select count(*) from t1;
不进入交互模式,执行一个hive script
这里可以和静音模式-S联合使用,通过第三方程序调用,第三方程序通过hive的标准输出获取结果集。
$HIVE_HOME/bin/hive -S -f
/home/my/hive-script.sql (不会显示mapreduct的操作过程)
方式2:hive -e 'sql语句'(适合短语句)
直接执行sql语句
例如:
[root@cloud4 shell]# hive -e 'select * from t1'
静音模式:
[root@cloud4 shell]# hive -S -e 'select * from t1' (用法与第一种方式的静音模式一样,不会显示mapreduce的操作过程)
此处还有一亮点,用于导出数据到linux本地目录下
例如:
[root@cloud4 shell]# hive -e 'select * from t1' > test.txt
有点类似pig导出分析结果一样,都挺方便的
方式3:hive (直接使用hive交互式模式)
都挺方便的
介绍一种有意思的用法:
1.sql的语法
#hive 启动
hive>quit; 退出hive
hive> show databases; 查看数据库
hive> create database test; 创建数据库
hive> use default; 使用哪个数据库
hive>create table t1 (key
string); 创建表
对于创建表我们可以选择读取文件字段按照什么字符进行分割
例如:
hive>create table
t1(id ) '/wlan'
partitioned by (log_date string) 表示通过log_date进行分区
row format delimited fields terminated by '\t' 表示代表用‘\t’进行分割来读取字段
stored as textfile/sequencefile/rcfile/; 表示文件的存储的格式
存储格式的参考地址:/article/1355118.html
textfile 默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
实例:
[plain] view plaincopy
> create table test1(str STRING)
> STORED AS TEXTFILE;
OK
Time taken: 0.786 seconds
#写脚本生成一个随机字符串文件,导入文件:
> LOAD DATA LOCAL INPATH '/home/work/data/test.txt' INTO TABLE test1;
Copying data from file:/home/work/data/test.txt
Copying file: file:/home/work/data/test.txt
Loading data to table default.test1
OK
Time taken: 0.243 seconds
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
示例:
[plain] view plaincopy
> create table test2(str STRING)
> STORED AS SEQUENCEFILE;
OK
Time taken: 5.526 seconds
hive> SET hive.exec.compress.output=true;
hive> SET io.seqfile.compression.type=BLOCK;
hive> INSERT OVERWRITE TABLE test2 SELECT * FROM test1;
rcfile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。RCFILE文件示例:
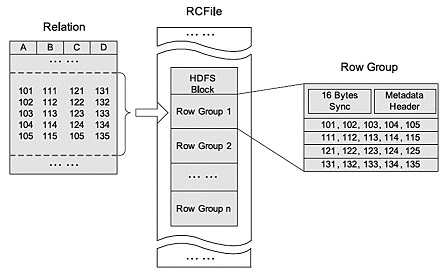
实例:
[plain] view plaincopy
> create table test3(str STRING)
> STORED AS RCFILE;
OK
Time taken: 0.184 seconds
> INSERT OVERWRITE TABLE test3 SELECT * FROM test1;
总结:
相比textfile和SequenceFile,rcfile由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,rcfile相比其余两种格式具有较明显的优势。
hive>show tables; 查看该数据库中的所有表
hive>show tables ‘*t*’; //支持模糊查询
hive>show
partitions t1; //查看表有哪些分区
hive>drop table t1 ; 删除表
hive不支持修改表中数据,但是可以修改表结构,而不影响数据
有local的速度明显比没有local慢:
hive>load data inpath '/root/inner_table.dat'
into table t1; 移动hdfs中数据到t1表中
hive>load data local inpath '/root/inner_table.dat' into table t1; 上传本地数据到hdfs中
hive> !ls; 查询当前linux文件夹下的文件
hive> dfs -ls /; 查询当前hdfs文件系统下
'/'目录下的文件
方式1:hive –f /root/shell/hive-script.sql(适合多语句)
hive-script.sql类似于script一样,直接写查询命令就行
例如:
[root@cloud4 shell]# vi hive_script3.sql
select * from t1;
select count(*) from t1;
不进入交互模式,执行一个hive script
这里可以和静音模式-S联合使用,通过第三方程序调用,第三方程序通过hive的标准输出获取结果集。
$HIVE_HOME/bin/hive -S -f
/home/my/hive-script.sql (不会显示mapreduct的操作过程)
方式2:hive -e 'sql语句'(适合短语句)
直接执行sql语句
例如:
[root@cloud4 shell]# hive -e 'select * from t1'
静音模式:
[root@cloud4 shell]# hive -S -e 'select * from t1' (用法与第一种方式的静音模式一样,不会显示mapreduce的操作过程)
此处还有一亮点,用于导出数据到linux本地目录下
例如:
[root@cloud4 shell]# hive -e 'select * from t1' > test.txt
有点类似pig导出分析结果一样,都挺方便的
方式3:hive (直接使用hive交互式模式)
都挺方便的
介绍一种有意思的用法:
1.sql的语法
#hive 启动
hive>quit; 退出hive
hive> show databases; 查看数据库
hive> create database test; 创建数据库
hive> use default; 使用哪个数据库
hive>create table t1 (key
string); 创建表
对于创建表我们可以选择读取文件字段按照什么字符进行分割
例如:
hive>create table
t1(id ) '/wlan'
partitioned by (log_date string) 表示通过log_date进行分区
row format delimited fields terminated by '\t' 表示代表用‘\t’进行分割来读取字段
stored as textfile/sequencefile/rcfile/; 表示文件的存储的格式
存储格式的参考地址:/article/1355118.html
textfile 默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
实例:
[plain] view plaincopy
> create table test1(str STRING)
> STORED AS TEXTFILE;
OK
Time taken: 0.786 seconds
#写脚本生成一个随机字符串文件,导入文件:
> LOAD DATA LOCAL INPATH '/home/work/data/test.txt' INTO TABLE test1;
Copying data from file:/home/work/data/test.txt
Copying file: file:/home/work/data/test.txt
Loading data to table default.test1
OK
Time taken: 0.243 seconds
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
示例:
[plain] view plaincopy
> create table test2(str STRING)
> STORED AS SEQUENCEFILE;
OK
Time taken: 5.526 seconds
hive> SET hive.exec.compress.output=true;
hive> SET io.seqfile.compression.type=BLOCK;
hive> INSERT OVERWRITE TABLE test2 SELECT * FROM test1;
rcfile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。RCFILE文件示例:
实例:
[plain] view plaincopy
> create table test3(str STRING)
> STORED AS RCFILE;
OK
Time taken: 0.184 seconds
> INSERT OVERWRITE TABLE test3 SELECT * FROM test1;
总结:
相比textfile和SequenceFile,rcfile由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,rcfile相比其余两种格式具有较明显的优势。
hive>show tables; 查看该数据库中的所有表
hive>show tables ‘*t*’; //支持模糊查询
hive>show
partitions t1; //查看表有哪些分区
hive>drop table t1 ; 删除表
hive不支持修改表中数据,但是可以修改表结构,而不影响数据
有local的速度明显比没有local慢:
hive>load data inpath '/root/inner_table.dat'
into table t1; 移动hdfs中数据到t1表中
hive>load data local inpath '/root/inner_table.dat' into table t1; 上传本地数据到hdfs中
hive> !ls; 查询当前linux文件夹下的文件
hive> dfs -ls /; 查询当前hdfs文件系统下
'/'目录下的文件

相关文章推荐
- 机器学习实战之Apriori
- 告别编译运行 ---- Android Studio 2.0 Preview发布Instant Run功能
- Javascript中document.execCommand()的用法
- GPS编码格式及C语言解码
- client缓存机制
- 服务应用监控健康检测
- fopen、file_get_contents方式set head
- 淡忘~浅思 » DOM笔记(十二):又谈原型对象
- HTTP中Get与Post的区别
- 如何判断用户是否关闭浏览器
- 短线与长线
- GridView只显示一行,可以横着滑动
- C # int值大小 0003
- 如何使用robots.txt及其详解
- 开发笔记-27个iOS开发中的小技巧
- php 项目bug 快速定位
- 【leetcode】268. Missing Number
- java.security.cert.CertPathValidatorException: timestamp check failed
- 7.内存和IO
- ARM