ubuntu14.4(虚拟机)搭建hadoop 2.7.2
2016-04-18 09:24
344 查看

接下来这个是配置环境变量
vim~/.bashrc
要做接下来的修改:
文件最前头加上:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export
JAVA_LIBRARY_PATH=/path/to/hadoop-native-libs
文件末尾加上:
#HADOOP
VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
#HADOOP VARIABLES END
按ESC保存
后 按 SHIFT + Z +Z 退出编辑页面
然后source~/.bashrc
使环境变量生效
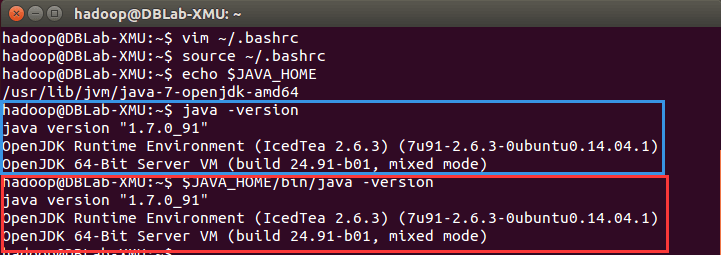
接着执行echo$JAVA_HOME#
检验变量
java -version
$JAVA_HOME/bin/java -version#
与直接执行 java -version 一样
然后是安装Hadoop( 在ubuntu的浏览器下载)
Hadoop
2 可以通过 http://mirror.bit.edu.cn/apache/hadoop/common/ 或者 http://mirrors.cnnic.cn/apache/hadoop/common/下载,一般选择下载最新的稳定版本,即下载
“stable” 下的 hadoop-2.x.y.tar.gz 这个格式的文件
这里我下载 hadoop-2.7.2
sudo
tar -zxf ~/Downloads/hadoop-2.7.2.tar.gz -C /usr/local
解压到/usr/local中 如果这句命令有问题,试试把命令中的Downloads 改成 下载
cd/usr/local/
sudo mv./hadoop-2.7.2/
./hadoop# 将文件夹名改为hadoop
sudo chown-R
hadoop ./hadoop# 修改文件权限
Hadoop
解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd/usr/local/hadoop
./bin/hadoop version
然后配置
打开文件夹
就是Computer中 usr/local/hadoop/etc/hadoop中
改core-site.xmlyarn-site.xmlmapred-site.xmlhdfs-site.xml
也可以用命令行进入
如 gedit ./etc/hadoop/core-site.xml
其中core-site.xml
:
把
<configuration>
</configuration>
之间加上
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other
temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
yarn-site.xml:
也是一样在里面加上内容为:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
关于mapred-site.xml:
要先在命令行
首先
cd/usr/local/hadoop/etc/hadoop/
然后
cp
mapred-site.xml.template mapred-site.xml
然后一样在文件
修改(加上)东西:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
关于 hdfs-site.xml :
先做以下工作:

然后一样 加上:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
关于 hadoop-env.sh
把export JAVA_HOME 改成
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
然后执行命令
./bin/hdfs
namenode -format
./sbin/start-dfs.sh
sbin/start-yarn.sh
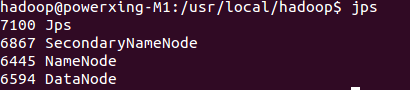
然后jps就可以看到
浏览器打开 http://localhost:50070/,会看到hdfs管理页面
浏览器打开http://localhost:8088,会看到hadoop进程管理页面
参考链接:
http://dblab.xmu.edu.cn/blog/install-hadoop/ http://www.cnblogs.com/kinglau/p/3794433.html http://www.cnblogs.com/kinglau/p/3796164.html

相关文章推荐
- Tomcat下取消POST大小的限制
- Tomcat 6.0 部署与发布
- Tomcat 部署详解
- tomcat配置文件server.xml详解
- OpenStack Mitaka新版特性
- Linux下修改MAC地址
- 软件开发网站推荐
- tomcat 日志输出
- 基于标记的AR的OpenCV实现(二)
- 常用linux命令积累
- 还在用GCD?来看看NSOperation吧
- OpenStack for Mitaka安装分享
- 基于标记的AR的opencv实现(一)
- 结合Apache和Tomcat实现集群和负载均衡
- Maven 集成Tomcat7插件
- DNS 反向解析出错 Error in named configuration: zone centos.vbird/IN: loaded serial 2011080401
- 数据驱动:安全狗saas化的创新优点
- 如何使用 OpenStack CLI - 每天5分钟玩转 OpenStack(22)
- 如何使用 OpenStack CLI - 每天5分钟玩转 OpenStack(22)
- IOS 查看lib库(.a)支持的处理器架构、合并真机库和模拟器库的命令