Heritirix1.14.4使用自定义规则抽取URL、爬取URL
2016-04-18 00:00
253 查看
摘要: Heritrix1.14.4中自定义规则抽取URL、爬取URL(配置自定义规则)
网络上关于Heritrix的安装及使用有很多教材,这里不加赘诉。本文主要介绍自定义抽取、爬取规则的基本使用及其配置。
首先,我们自定义一个包myExtractor,下面存放我们自定义抽取url的规则即什么样格式的url是我们需要抓取的,将其抽取出来放到队列中等待进行抓取。
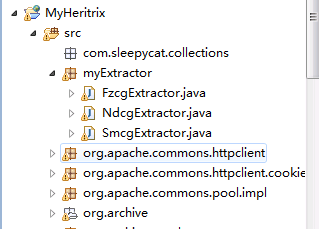
接下来在org.archive.crawler.postprocessor包下新建一个class,作用就是下载我们抽取的url
的网页的时候一些文件格式的过滤及url的控制
最后我们需要在配置文件里配置一下,才能在Heritrix的Web操作界面选择我们自定义的这些规则。
在/MyHeritrix/conf/modules/Processor.options中加入myExtractor.FzcgExtractor|FzcgExtractor、org.archive.crawler.postprocessor.FrontierSchedulerForFzcg|FrontierSchedulerForFzcg,完成。
网络上关于Heritrix的安装及使用有很多教材,这里不加赘诉。本文主要介绍自定义抽取、爬取规则的基本使用及其配置。
首先,我们自定义一个包myExtractor,下面存放我们自定义抽取url的规则即什么样格式的url是我们需要抓取的,将其抽取出来放到队列中等待进行抓取。
接下来在org.archive.crawler.postprocessor包下新建一个class,作用就是下载我们抽取的url
的网页的时候一些文件格式的过滤及url的控制
protected void schedule(CandidateURI caUri){
String uri = caUri.toString();
//过滤掉一下这些格式,即一下格式的文件不要下载到本地
if(uri.endsWith(".js")||uri.endsWith(".jpg")||uri.endsWith("css")||uri.endsWith(".gif")
||uri.endsWith(".GIF")||uri.endsWith(".JS")
||uri.endsWith(".swf")||uri.endsWith(".doc")||uri.endsWith(".png")||uri.endsWith(".JPG")){
return;
}
//只抓取包含"fzzfcg.gov.cn"的URI,控制抓取范围在下
if(uri.contains("fzzfcg.gov.cn")){
//在控制台输出当前处理的URI
System.out.println(uri);
getController().getFrontier().schedule(caUri);
}最后我们需要在配置文件里配置一下,才能在Heritrix的Web操作界面选择我们自定义的这些规则。
在/MyHeritrix/conf/modules/Processor.options中加入myExtractor.FzcgExtractor|FzcgExtractor、org.archive.crawler.postprocessor.FrontierSchedulerForFzcg|FrontierSchedulerForFzcg,完成。

相关文章推荐
- Heritrix 1.14.4的配置和初次使用
- heritrix在eclipse中的配置
- Heritrix的安装与配置
- Heritrix源码分析(一)——包介绍
- Heritrix使用UTF-8编码格式存储文件
- Heritrix eclipse安装、配置
- 基于Heritrix的特定主题的网络爬虫配置与实现
- Heritrix eclipse创建java可运行程序的步骤
- 在Eclipse下运行Heritrix3.2.0(环境windows10 64位)
- heritrix 在myeclipse中的配置
- Heritrix 的优化
- heritrix 在Prefetcher中取消robots.txt的限制
- 在Eclipse中配置Heritrix
- heritrix安装配置和抓取
- Heritrix在Eclipse下的配置方法
- 后台运行Heritrix常见错误
- Heritrix增量抓取的三种方式
- 如何在后台运行Heritrix
- Heritrix的order.xml详细介绍
- Heritrix只爬取html、htm等特定页面