manecher算法详解
2016-04-16 17:32
246 查看
manecher算法详解
首先用一个非常巧妙的方式,将所有可能的奇数/偶数长度的回文子串都转换成了奇数长度:在每个字符的两边都插入一个特殊的符号。比如
abba 变成 #a#b#b#a#, aba变成 #a#b#a#。 为了进一步减少编码的复杂度,可以在字符串的开始加入另一个特殊字符,这样就不用特殊处理越界问题,比如$#a#b#a#(注意,下面的代码是用C语言写就,由于C语言规范还要求字符串末尾有一个'\0'所以正好OK,但其他语言可能会导致越界)。
下面以字符串12212321为例,经过上一步,变成了 S[] = "$#1#2#2#1#2#3#2#1#";
然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向左/右扩张的长度(包括S[i],也就是把该回文串“对折”以后的长度),比如S和P的对应关系:
S # 1 # 2 # 2 # 1 # 2 # 3 # 2 # 1 #
P 1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1
(p.s. 可以看出,P[i]-1正好是原字符串中回文串的总长度)
那么怎么计算P[i]呢?该算法增加两个辅助变量(其实一个就够了,两个更清晰)id和mx,其中 id 为已知的 {右边界最大} 的回文子串的中心,mx则为id+P[id],也就是这个子串的右边界。
然后可以得到一个非常神奇的结论,这个算法的关键点就在这里了:如果mx > i,那么P[i] >= MIN(P[2 * id - i], mx - i)。就是这个串卡了我非常久。实际上如果把它写得复杂一点,理解起来会简单很多:
//记j = 2 * id - i,也就是说 j 是 i 关于 id 的对称点(j = id + (id - i))
if (mx - i > P[j])
P[i] = P[j];
else /* P[j] >= mx - i */
P[i] = mx - i; // P[i] >= mx - i,取最小值,之后再匹配更新。
当然光看代码还是不够清晰,还是借助图来理解比较容易。
当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i
和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。
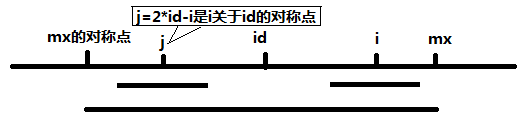
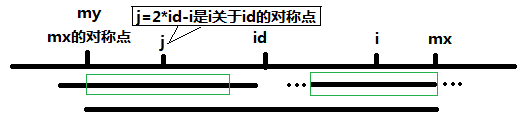
当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说
P[i] >= mx - i。至于mx之后的部分是否对称,就只能老老实实去匹配了。
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了。
于是代码如下:
//输入,并处理得到字符串s
int p[1000], mx = 0, id = 0;
memset(p, 0, sizeof(p));
for (i = 1; s[i] != '\0'; i++) {
p[i] = mx > i ? min(p[2*id-i], mx-i) : 1;
while (s[i + p[i]] == s[i - p[i]]) p[i]++;
if (i + p[i] > mx) {
mx = i + p[i];
id = i;
}
}
//找出p[i]中最大的
首先用一个非常巧妙的方式,将所有可能的奇数/偶数长度的回文子串都转换成了奇数长度:在每个字符的两边都插入一个特殊的符号。比如
abba 变成 #a#b#b#a#, aba变成 #a#b#a#。 为了进一步减少编码的复杂度,可以在字符串的开始加入另一个特殊字符,这样就不用特殊处理越界问题,比如$#a#b#a#(注意,下面的代码是用C语言写就,由于C语言规范还要求字符串末尾有一个'\0'所以正好OK,但其他语言可能会导致越界)。
下面以字符串12212321为例,经过上一步,变成了 S[] = "$#1#2#2#1#2#3#2#1#";
然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向左/右扩张的长度(包括S[i],也就是把该回文串“对折”以后的长度),比如S和P的对应关系:
S # 1 # 2 # 2 # 1 # 2 # 3 # 2 # 1 #
P 1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1
(p.s. 可以看出,P[i]-1正好是原字符串中回文串的总长度)
那么怎么计算P[i]呢?该算法增加两个辅助变量(其实一个就够了,两个更清晰)id和mx,其中 id 为已知的 {右边界最大} 的回文子串的中心,mx则为id+P[id],也就是这个子串的右边界。
然后可以得到一个非常神奇的结论,这个算法的关键点就在这里了:如果mx > i,那么P[i] >= MIN(P[2 * id - i], mx - i)。就是这个串卡了我非常久。实际上如果把它写得复杂一点,理解起来会简单很多:
//记j = 2 * id - i,也就是说 j 是 i 关于 id 的对称点(j = id + (id - i))
if (mx - i > P[j])
P[i] = P[j];
else /* P[j] >= mx - i */
P[i] = mx - i; // P[i] >= mx - i,取最小值,之后再匹配更新。
当然光看代码还是不够清晰,还是借助图来理解比较容易。
当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i
和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。
当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说
P[i] >= mx - i。至于mx之后的部分是否对称,就只能老老实实去匹配了。
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了。
于是代码如下:
//输入,并处理得到字符串s
int p[1000], mx = 0, id = 0;
memset(p, 0, sizeof(p));
for (i = 1; s[i] != '\0'; i++) {
p[i] = mx > i ? min(p[2*id-i], mx-i) : 1;
while (s[i + p[i]] == s[i - p[i]]) p[i]++;
if (i + p[i] > mx) {
mx = i + p[i];
id = i;
}
}
//找出p[i]中最大的

相关文章推荐
- 如何组织构建多文件 C 语言程序(二)
- 如何写好 C main 函数
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- Lua和C语言的交互详解
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 关于C语言中参数的传值问题
- 简要对比C语言中三个用于退出进程的函数
- 深入C++中API的问题详解
- 基于C语言string函数的详解
- C语言中fchdir()函数和rewinddir()函数的使用详解
- C语言内存对齐实例详解
- C语言编程中统计输入的行数以及单词个数的方法