HDFS源码分析(5):datanode数据块的读与写DataXceiver
2016-04-16 12:49
731 查看
前提
Hadoop版本:hadoop-0.20.2
概述
现在已经知道datanode是通过DataXceiver来处理客户端和其它datanode的请求,在分析DataXceiver时已经对除数据块的读与写之外的操作进行了说明,本文主要分析比较复杂而且非常重要的两个操作:读与写。对于用户而言,HDFS用得最多的两个操作就是写和读文件,而且在大部分情况下,是一次写入,多次读取,满足高吞吐量需求而非低延迟,除去客户端与namenode的协商,剩下的部分主要是客户端直接与datanode通信(数据流的头部在上篇文章中已介绍),发送或接收数据,而这些数据在datanode如何接收并写入磁盘、如何从磁盘读出并发送出去就是本文所要介绍的内容。
DataChecksum
无论是读数据还是写数据,都会涉及到checksum,我们先来看看DataChecksum的结构,该类位于org.apache.hadoop.util这个包下,有以下几个主要属性:type:checksum的类型,有CHECKSUM_NULL和CHECKSUM_CRC32两种
size:checksum的大小(字节),CHECKSUM_NULL的大小是0,CHECKSUM_CRC32的大小是4
summer:真正用来做checksum的对象,CHECKSUM_NULL使用的是ChecksumNull这个自定义的不干实事的类,CHECKSUM_CRC32使用的是java提供的CRC32
bytesPerChecksum:用来做checksum的数据片的大小(字节),即HDFS会把块文件(block)分成多个分片(chunk),对每个分片做checksum,那么读或写数据的最小单位是分片
inSum:已经做checksum的总字节数
DataChecksum的header有5个字节,其中type占1个字节,bytesPerChecksum占4个字节。
DataChecksum有如下几类方法:
newDataChecksum:创建一个新的DataChecksum
writeHeader:将checksum header写到输出流
getHeader:将checksum header存到一个byte数组中,并返回
writeValue:将checksum计算结果写到输出流或缓冲区中
getValue:返回checksum计算结果
reset:重置checksum
update:更新checksum
BlockMetadataHeader
一直在说一个块有数据文件和元数据文件,有了上边对checksum的分析,下面我们来揭开datanode上管理数据块元数据的BlockMetadataHeader的面纱,数据块无数据的最大部分是块的CRC,这部分与namenode与块相关的功能无关。有两个属性:
version:元数据版本(2个字节)
checksum:数据校验和(header占5个字节)
那么元数据文件的header总共有7个字节,元数据文件的结构大概如下所示:
1 | +---------------------------------------------------+ | 2 byte version | 1 byte checksum type | +---------------------------------------------------+ | 4 byte bytesPerChecksum | 4 byte checksum | +---------------------------------------------------+ | Sequence of checksums | +--------------------------+ |
readHeader:从文件或输入流读取header
writeHeader:将header写到输出流
getHeaderSize:得到header的大小,该版本是7
BlockSender
从BlockSender这个名字我们就能够知道它的作用是用于发送块文件,首先,我们来看看其重要的属性:block:读取的数据块
blockIn:本地磁盘的块文件
blockInPosition:是否使用transferTo()
checksumIn:本地磁盘的块元数据文件
checksum:checksum stream
offset:读取的数据在块中的起始位置
endOffset:结束位置
blockLength:块的长度
bytesPerChecksum:chunk大小
checksumSize:checksum大小
corruptChecksumOk:是否需要验证checksum是否损坏
chunkOffsetOK:是否需要发送chunk的开始位置
seqno:packet编号
transferToAllowed:是否允许transferTo
blockReadFully:如果整个块被读取,设置为true
verifyChecksum:在读数据时,是否检查checksum
下面,我们来看看其构造方法,其定义如下:
1 | BlockSender(Block block, long startOffset, long length, boolean corruptChecksumOk, boolean chunkOffsetOK, boolean verifyChecksum, DataNode datanode, String clientTraceFmt); |
block:要读取的块
startOffset:读取数据的开始位置
length:读取数据的长度
corruptChecksumOk:是否需要验证checksum是否损坏
chunkOffsetOK:是否需要发送chunk的开始位置
verifyChecksum:在读数据时,是否检查checksum
datanode:当前所在的datanode
clientTraceFmt:client trace log message的格式
初始化的过程如下:
读取元数据,加载checksum
计算bytesPerChecksum和checksumSize,
检查并调整开始位置和结束位置,使开始位置和结束位置与验证块的边界对齐
将checksum数据定位到正确的位置
将块数据文件输入流定位到正确的位置
首先,我们来看看sendBlock方法,其定义如下:
1 | long sendBlock(DataOutputStream out, OutputStream baseStream, BlockTransferThrottler throttler) throws IOException; |
out:是块数据要写出的流
baseStream:如果不为null,那么out是该流的包装器,即out封装了baseStream
throttler:用于控制流量
sendBlock的处理流程是这样的:
将数据的header(checksum header,如果需要发送块的开始位置还需要再加一offset)写到out
检查是或允许transferTo(verifyChecksum为false,baseStream是SocketOutputStream,blockIn是FileInputStream),这种方式使用FileChannel来传输数据,而不是先将数据读取到缓冲区
计算每个packet数据(checksum和数据)的大小
将所有packet写到out
将一整数(int)0写到out,标记块的结束
到此我们知道发送的块数据如下所示:
1 | +-----------------------------------------------------+ | 1 byte checksum type | 4 byte bytesPerChecksum | +-----------------------------------------------------+ | 8 byte offset if chunkOffsetOK=true | +-----------------------------------------------------+ | Sequence of data PACKETs | 4 byte 0 | +-----------------------------------------------------+ |
计算真实的chunk数numChunks和packet的大小packetLen
将packet header(packet大小packetLen、数据在block中的位置offset、packet编号seqno、是否是最后一个packet、真实数据的大小len)写到out
读取checksum数据到缓冲区,如果corruptChecksumOk为真,那么在出错时修复数据
如果不允许transferTo,读取真实数据到缓冲区,如果verifyChecksum为真,那么检查checksum,最后将checksum和真实数据写到out
如果允许transferTo,调用SocketOutputStream的transferToFully方法传输数据
做流量控制
由以上分析,我们可知packet的结构如下:
1 | +-----------------------------------------------------+ | 4 byte packet length (excluding packet header) | +-----------------------------------------------------+ | 8 byte offset in the block | 8 byte sequence number | +-----------------------------------------------------+ | 1 byte isLastPacketInBlock | +-----------------------------------------------------+ | 4 byte Length of actual data | +-----------------------------------------------------+ | x byte checksum data. x is defined below | +-----------------------------------------------------+ | actual data ...... | +-----------------------------------------------------+ |
1 | x = (length of data + BYTE_PER_CHECKSUM - 1)/BYTES_PER_CHECKSUM * CHECKSUM_SIZE |
BlockReceiver
BlockReceiver主要作用是接收块文件,首先,我们来看看其重要的属性:block:接收的块
in:接收数据的流
out:本地磁盘的块文件
checksum:计算checksum
checksumOut:本地磁盘的元数据文件
bytesPerChecksum:用来做checksum的数据片的大小
checksumSize:checksum的大小
buf:存接收的数据,一个完整的packet
bufRead:接收的合法的数据的大小
offsetInBlock:接收的数据在块中的位置
mirrorAddr:pipeline中下一个datanode的地址
mirrorOut:用于将数据发送到pipeline中下一个datanode
responder:用于应答的线程
isRecovery:是否是恢复操作(覆盖或追加)
inAddr:数据发送方的地址
myAddr:本地的地址
下面,我们来看看其构造方法,其定义如下:
1 | BlockReceiver(Block block, DataInputStream in, String inAddr,
String myAddr, boolean isRecovery, String clientName,
DatanodeInfo srcDataNode, DataNode datanode) throws IOException { |
block:接收的块
in:接收数据的流
inAddr:数据发送方的地址
myAddr:本地的地址
isRecovery:是否是恢复操作,即原来文件已经存在
clientName:客户端名字
srcDataNode:发送数据的datanode
datanode:本datanode
初始化的过程如下:
读取checksum信息
打开本地的块文件和元数据文件,并检查块是否正确
如果是恢复操作,将块从blockScanner中删除
BlockReceiver这个类比较复杂,有一千行左右代码,我们以客户端写文件为例来说明其处理过程,如下图所示:
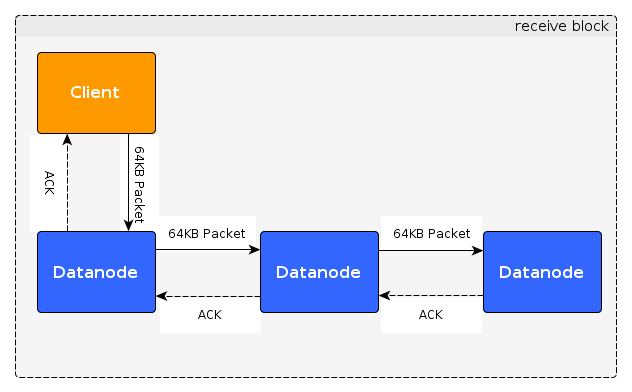
从上图可以看出数据被分成64KB的packet从客户端沿着pipeline逐一发送到所有的datanode,到达最后一个datanode后,应答信息ACK从最后一个datanode沿着pipeline送回客户端,客户端收到ACK就能够知道数据是否发送成功。对于每个datanode,其职责是接收数据包并将数据包发送到其下游datanode,收到ACK后,对ACK进行加工后发送给上游的datanode或client。如果是拷贝块数据操作,是不需要发送应答包的,过程比上图要简单,只需要把数据从一个datanode发送到另一个datanode。
那么,可以将下面的内容分成接收数据和发送应答包两部分,首先,我们来看看接收数据的入口receiveBlock方法:
1 | void receiveBlock( DataOutputStream mirrOut, // output to next datanode DataInputStream mirrIn, // input from next datanode DataOutputStream replyOut, // output to previous datanode String mirrAddr, BlockTransferThrottler throttlerArg, int numTargets) throws IOException; |
mirrOut:到下游datanode的输出流,用以发送数据包
mirrIn:来自下游datanode的输入流,用以接收应答包
replyOut:到上流datanode的输出流,用以发送应答包
mirrAddr:下游datanode的地址
throttlerArg:节流器,用于控制流量
numTargets:下游datanode的数量,用于确认应答包是否正确
处理的过程如下面的流程图所示:

在这个过程中,需要注意的是setBlockPosition这个方法,如果块文件之前已经finalize了,并且isRecovery为false或者offsetInBlock超过块的大小,那么会抛异常。前边已经讲到每个块文件会被分割成多个chunk,然后对每个chunk做checksum,在这里,如果offsetInBlock不与chunk的边界对齐,那么需要先读出offsetInBlock所位于chunk在offsetInBlock之前数据的checksum,再更新接收到的数据,这样才能确保checksum的正确性。
下面就来看看发送应答包是怎么回事,相关的类有PacketResponder、Packet和PipelineAck,PipelineAck是接口org.apache.hadoop.hdfs.protocol.DataTransferProtocol的内部静态类。先来看看简单的Packet,纯粹就是一个数据结构,有两个属性:
seqno:packet的编号
lastPacketInBlock:是否是最后一个包
PipelineAck封装了应答的内容,我们来看看其属性:
seqno:packet的编号
replies:一个数组,下游datanode及其自己的答应,数组中每个元素的取值是上一篇文章中操作的状态
HEART_BEAT:心跳应答对象,seqno为-1,replies中只有一个值OP_STATUS_SUCCESS
一个ACK的内容如下所示:
1 | +-----------------------------------------------------+ | 8 byte seqno | Sequence of 2 byte replies | +-----------------------------------------------------+ |
好了,只剩下一个PacketResponder了,先看其属性:
ackQueue:等待应答的packet队列
running:PacketResponder是否在运行
block:数据块
mirrorIn:来自下游datanode的输入流,用以接收应答包
replyOut:到上流datanode的输出流,用以发送应答包
numTargets:下游datanode的数量,用于确认应答包是否正确
receiver:PacketResponder的所有者
PacketResponder的处理有两种不同的方式:numTargets=0,说明这是pipeline的最后一个datanode;有下游datanode。
先来看看最后一个datanode是如何处理每个packet的:
如果ackQueue中没有元素,先等待一段时间,如果距上次发送心跳的时间间距超过某阈值,发送心跳给上游的datanode,重复以上操作直到ackQueue不为空
如果当前packet是最后一个,finalize数据块,并通知datanode接收完数据块
发送ACK给上游的datanode
如果不是最后一个datanode又是如何处理的:
接收下游datanode的ACK
如果是心跳ACK,直接发送给上游datanode,接着处理下个packet
如果非心跳ACK,先检查接收到的ACK的packet编号和当前队列中第一个元素的packet编号是否一致
如果当前packet是最后一个,finalize数据块,并通知datanode接收完数据块
构造ACK消息,replies的第一个元素是自己的状态,值为OP_STATUS_SUCCESS,如果没有收到下游datanode的ACK,其它元素的值为OP_STATUS_ERROR,否则其它元素的值为接收到的原值
将ACK消息发送给上游datanode
如果ACK有错,中止PacketResponder的运行

相关文章推荐
- Hadoop DataNode的读和写流程 选择datanode方法 机架感知
- 116. Populating Next Right Pointers in Each Node
- nodejs npm常用命令
- Node系列-快速开始Koa2
- nodejs笔记
- Node.js express路由简单分析
- Node.js学习 - Multiprocess
- Node.js学习 - RESTFul API
- Node.js学习 - Express
- Node.js学习 - Web Server
- Node.js学习 - GET/POST
- Node.js学习 - File Operation
- Node.js学习 - Route
- Node.js学习 - Function
- Node.js学习 - Modules
- Node.js学习 - Stream
- Node.js学习 - Buffer
- Node.js学习 - Event Loop
- Node.js学习 - CallBack Function
- Node 学习笔记之事件发射器