第九章·词典
2016-04-12 02:52
281 查看
第九章·词典
散列:原理
散列是一种赖以高效组织数据并实现相关算法的重要思想。这种思想背后的原理却很直观、简单。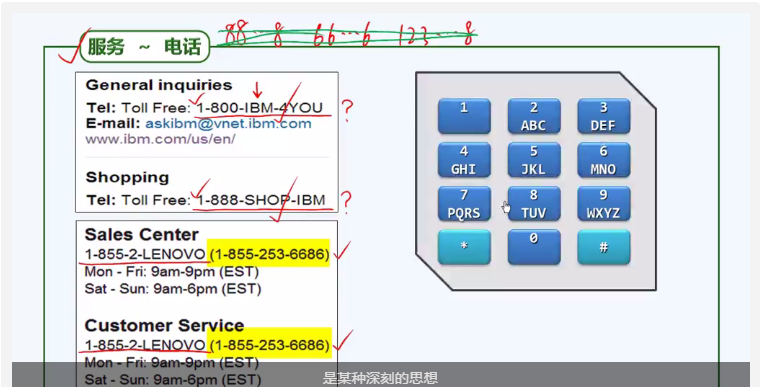
上图是IBM公司和联想公司的服务电话号码,可以看到这种号码是由数字和字母共同组成的。字母的含义一般是公司名相关,而这些字母通过键盘输入后,仍然是数字。
循值访问
对于访问数据的方式,大致有如下分类| 访问方式 | 含义 | 举例 |
|---|---|---|
| call-by-rank | 循秩访问 | vector向量 |
| call-by-position | 循位置访问 | list列表 |
| call-by-key | 循关键码访问 | BST平衡二叉树等 |
| call-by-value | 循值访问 | Hashing散列 |
散列的实现原理
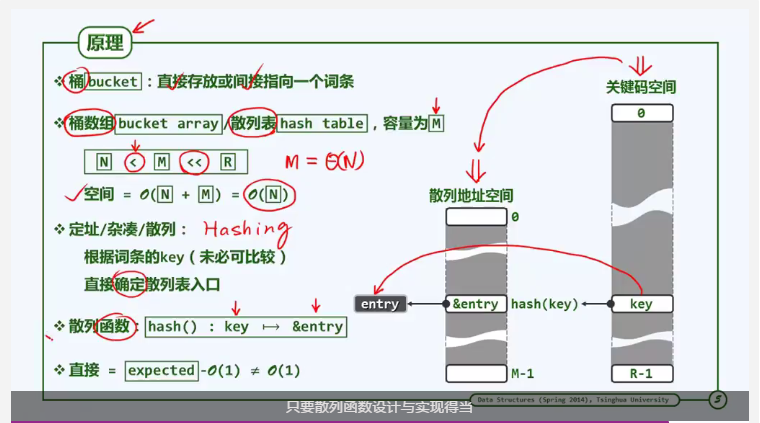
1. 以电话号码为例,关键码空间为存储所有电话号码的数组,比如从000000-999999。显然如果直接采用循位置访问的方式,所占用空间将非常巨大并且实际利用率很低。
2. 为了节省空间,散列采用一种“哈希表(散列表)”的方式存储关键码数据,称为散列地址空间。
3. 从关键码空间找到哈希表对应地址的过程称为“寻址”,这种方式用一个“哈希函数”来实现。如图中所示,由关键码空间的key通过hash(key)找到哈希表中的&entry,再由此找到对应的词条entry。
4. 只要哈希函数设计得当,可以使得转换过程的时间复杂度控制在常数范围。
5. 哈希表的空间M应该远小于可能空间R,同时稍大于实际空间N。
哈希函数的设计
以电话号码为例,将电话号码对哈希表的长度取余,得到的余数即为哈希表的对应位置。
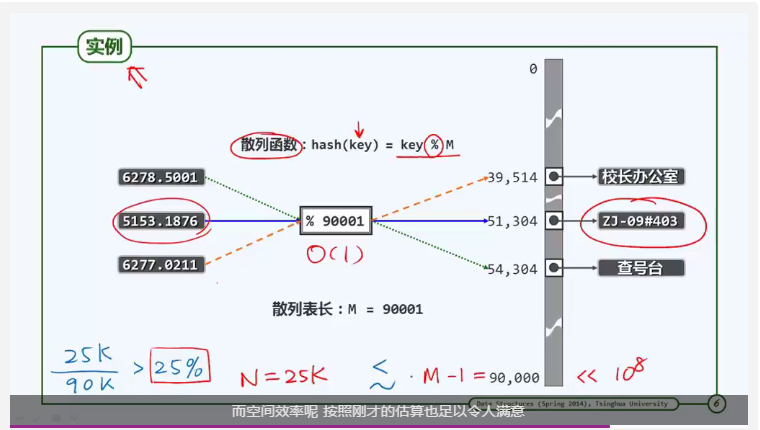
可以看到,此哈希函数的时间复杂度为O(1)
散列表的空间效率取决于实际空间N与哈希表空间M的比值,这一比值称为Load factor(装填因子),简记为λ。
解决冲突
由于哈希表是将一个相对较大的空间映射为一个较小的空间,那么必然存在不同的关键码在哈希表中占用同一个位置的情况。如何解决这种冲突呢?
精心设计散列表和散列函数,以尽可能降低冲突的概率
制定可行的预案,排解产生的冲突
散列:散列函数
散列函数设计标准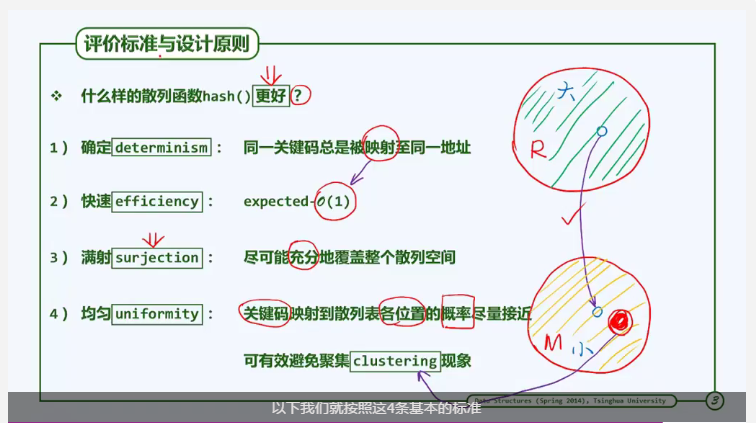
除余法:在除余法中,散列表长(也就是模)应该怎么选?
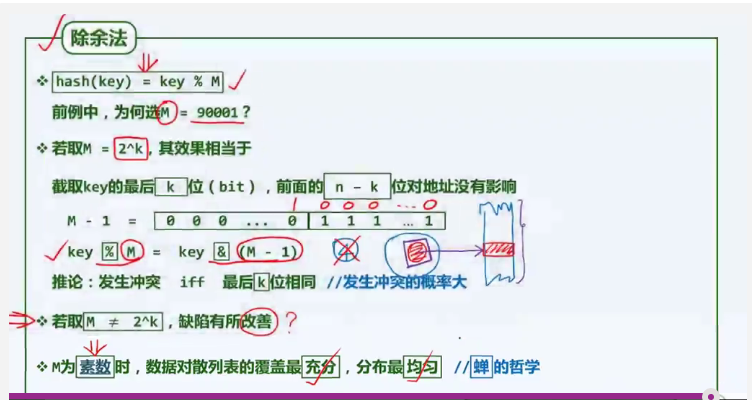
1. 如果将模取做2^k,这样对于数字计算是最高效的(与运算即可),但是这种方式的均匀性非常差。存在一个特定集合的数据经过除余后映射到散列表中的某一个特定单元。
2. 一种较为良好的策略是将模设定为素数。此时,数据对散列表的覆盖能够达到最充分,在散列表中的分布也将达到最均匀。
3. 在访问散列表数据时,一般是按照一个固定的“步长”S来访问的,比如电话号码的步长为1.整个散列表长度为M。要达到均匀性的目的,就是要按照S的间隔访问散列表的元素,能够遍历整个散列表空间。按照数论的知识,可以得到当且仅当(S,M)的最大公因子为1.因此M只能为素数。
1977年,著名古生物学家史蒂芬·杰·古尔德(StephenJayGould)提出了一个新假说,认为周期蝉这样做是为了避开自己的天敌。他指出,很多蝉的天敌也有自己的生命周期,假如周期蝉的生命周期不是质数,那么就会有很多机会和天敌的周期重叠。比如12年蝉就会和周期为2、3、4、6年的天敌重叠,被吃的可能性就要大很多。
——蝉:生命周期为素数的进化论优势
MAD法

由mad法的计算公式可知,b可以视为偏移量。这样可以解决不动点的缺陷。a相当于步长,亦即相邻元素的间隔。从而解决第二个缺陷。
散列的一个优势在于,其散列函数是可以灵活定制的。有些场合并不需要很强的均匀性,比如几何计算,将高维空间的点压缩到低维空间时,仍然保持点之间的邻近位置。这种方式称为Locality-Sensitive Hashing。密码学也采用了特定的散列规则,比如消息摘要算法。
平方取中法

注:取居中的数位的目的是使得原关键码每一个数位都对散列地址构成接近的影响。
折叠法
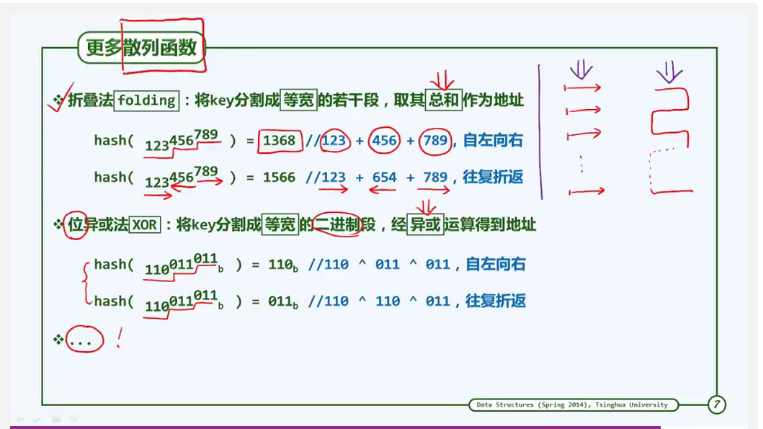
伪随机数
伪随机数的生成原理与散列原理非常相似,都是讲一个范围内的数随机、均匀、确定转换为另一个范围的数。因此散列函数可以参考伪随机数的生成原理来设计。
但注意:不同平台,或者同一平台不同版本的伪随机数算法可能是不同的。因此如果直接套用伪随机数算法,将使得散列算法的移植性很差。
多项式法
原始关键码未必都是整数,也可以是字符串等其他结构。因此需要先对其进行转换,变成散列码HashCode。字符串型关键码的转换方式为多项式法:
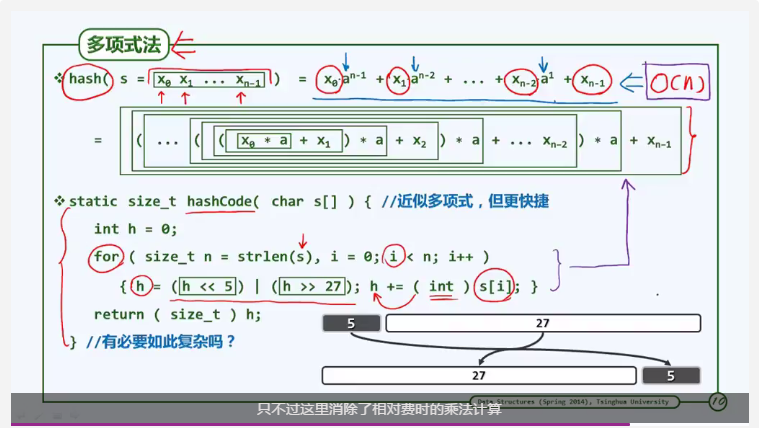
注:将字符先转换为对应的整数,将这些数分别视作为一个n次多项式的n个系数,计算出这个多项式的具体数值,并将其作为散列地址。
字符串折叠转换法
除了多项式法之外,也有一种类似前面折叠法的转换方法。即简单讲字符代表的整数相加得到散列地址。这种方法的缺点是将得到大量相同的散列地址。比如:
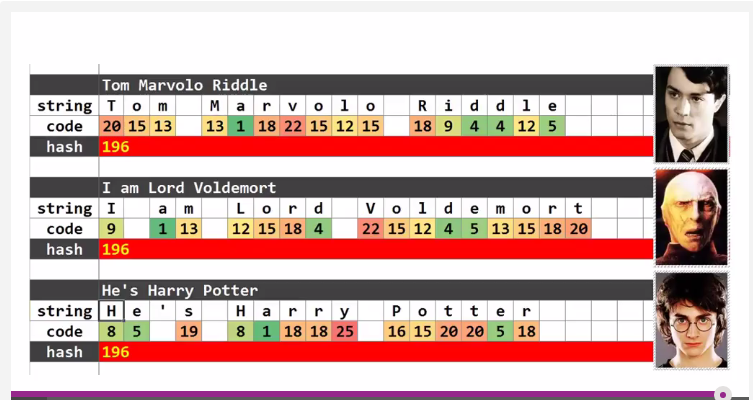
由此可以看出:Harry Potter和VoldeMort是同一个人(HashCode转换函数必须很复杂!)
散列:解决冲突
多槽位法
解决冲突的方式:在每一个散列空间的bucket(桶)中,设置多个“槽位”。如果在同一个桶中存在冲突,可以放置在不同的槽位中。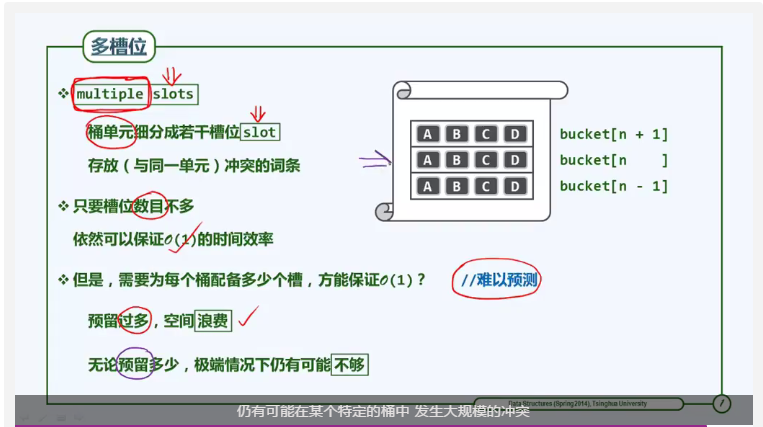
但是这种方法的缺陷是:无法预知一个桶需要设置多少个槽位。如果设置过多,则空间利用率将大幅降低。如果设置过少,则可能仍然存在冲突。
独立链法
使用列表:每个桶存放一个指针,冲突的词条组织成列表。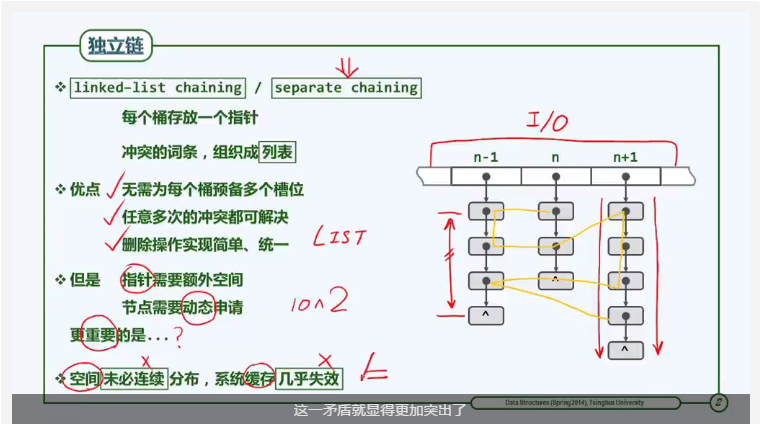
缺陷:由于不同的节点插入、删除顺序随机。因此对于任何一个列表而言,其节点空间可能不是连续分布,因此无法通过有效地缓存加速查找过程。当散列表的规模很大,以至于要借助IO时,这一缺陷就更加突出了。
Question:这节中说道,独立链是动态生成的。也就是说有多少个实际关键码,就会生成多少个节点。那么,何不在刚开始就把所有实际关键码进行存储呢?
Answer:这是因为散列表的设计,是为了平衡时间和空间。如果将实际关键码进行顺序存储,那么每次查找的时间复杂度为O(n),所需的空间最少。如果把关键码作为数组索引直接查找,那么时间复杂度仅为O(1),但是需要可能超出有效空间几个数量级。
哈希表是一个在时间和空间上做出权衡的经典例子。如果没有内存限制,那么可以直接将键作为数组的索引。那么所有的查找时间复杂度为O(1);如果没有时间限制,那么我们可以使用无序数组并进行顺序查找,这样只需要很少的内存。哈希表使用了适度的时间和空间来在这两个极端之间找到了平衡。只需要调整哈希函数算法即可在时间和空间上做出取舍。
——浅谈算法和数据结构: 十一 哈希表
开放定址
封闭定址:在散列表中每一个桶对应的列表中,其能够存放的元素只能是在这个桶中发生冲突的词条。开放定址:放弃使用列表。所有的散列以及冲突排解都在一个独立、连续的封闭空间内,每一个冲突词条都可能存在任何一个桶中。词条优先存放在其本来应该放置的桶中(即发生冲突的桶),如果本应该放置的桶已经存放了词条,则按照一定的次序查找下一个空桶进行存放(若已到达表尾,则回到表首继续查找直到不存在空桶为止)。这种查找链称为该词条的“试探链”或者“查找链”。
相应的,通过查找链查找冲突词条时,有两种结果:成功匹配;或者遇到空桶,查找失败。
应用开放定址策略的散列称为“闭散列”。
开放定址法Flash演示
.
线性试探
线性试探是开放定址一种简单地实现方式。
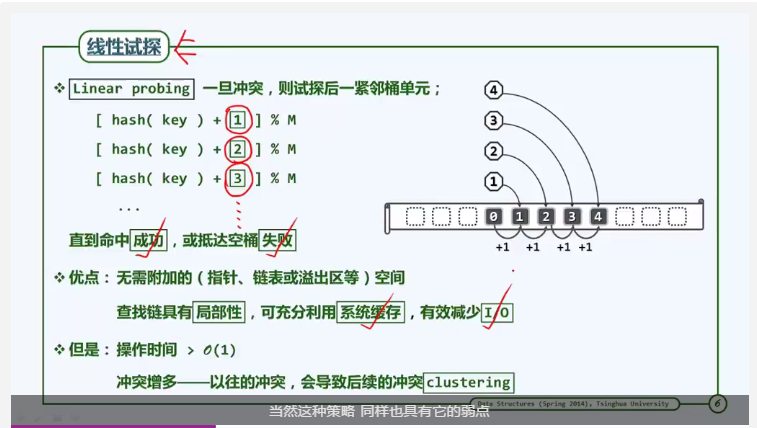
懒惰删除
之前说到,通过查找链查找时,如果遇到空桶,则查找失败。那么删除词条的方式不应该是将桶置空,而是应该使用一个删除标记。

平方试探
为了解决线性试探可能导致冲突过于密集的情况,采用将间距扩大的方法,可以有效避免。平方试探即是将关键码的偏移量进行平方处理。
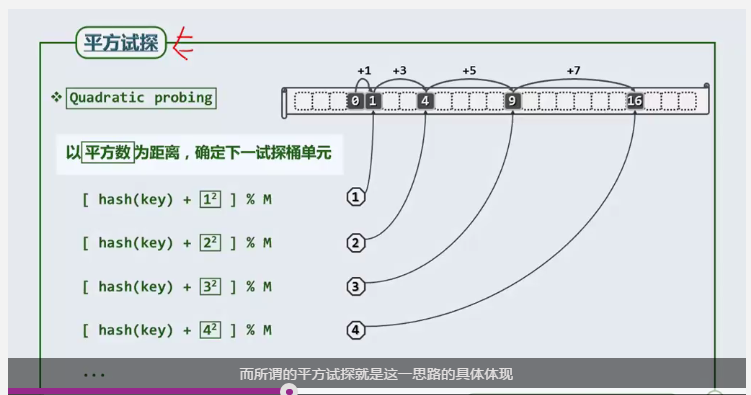
平方试探的缺点是:可能存在空桶,可是试探链找不到。如下图所示
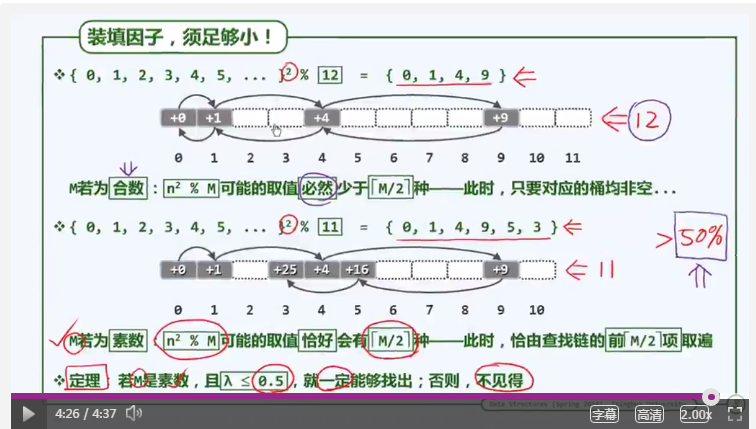
这条定理的证明过程如下,没看懂,就不解释了:(

根据这条定理可以得出查找链在M/2取上整的各项互异。然而,有没有可以使得前M项都互异的方法呢?答案是有的。
双向平方试探
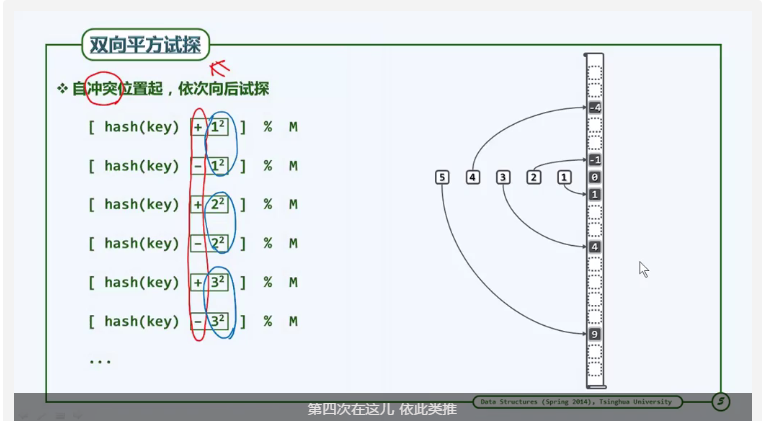
双向平方试探也有一个缺点:正向子查找链和逆向子查找链可能存在除了起点0之外的共同元素。那么,他们的查找项之和无法全部覆盖表长。怎么解决呢?表长不仅设为素数,还设为特殊的素数:4K+3。使得查找链全部覆盖表长且互异。

证明此结论需要用到双平方定理(费马提出):
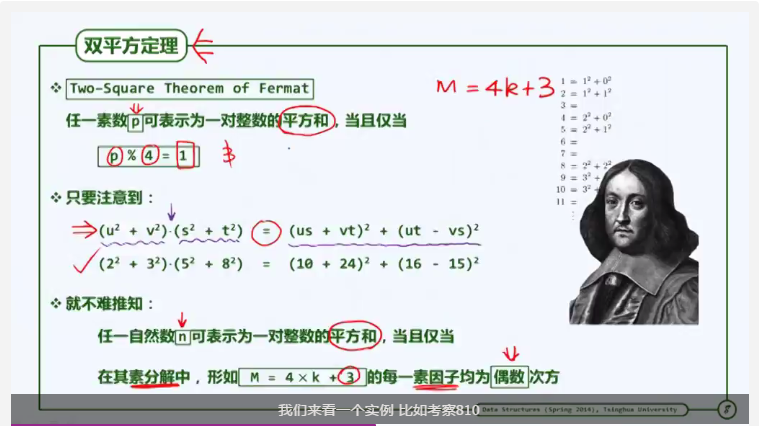
具体证明过程如下(呵呵,记住就好了):

通排序、计数排序
通排序、计数排序的性能不完全取决于待排序元素的规模n,也取决于待排序元素的取值范围M。这种算法的渐进时间复杂度为O(n+M)。这种算法适用于M和n同阶或低阶的情况。
桶排序、计数排序的原理是利用散列,以字符排序为例:
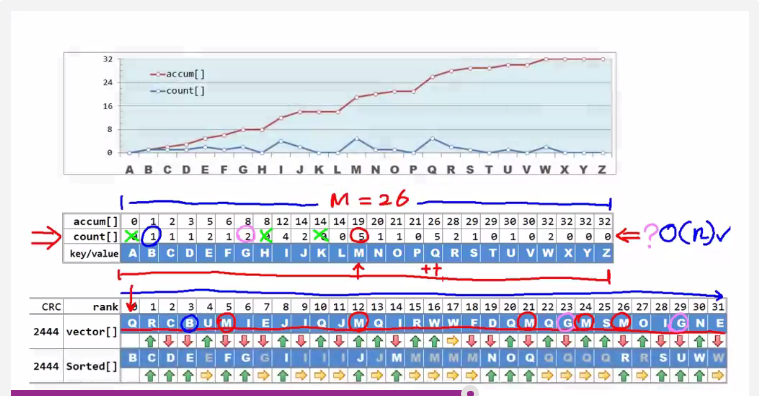
1. 建立长度为26(字符总数)的散列表,其值包括count(计数)和accum(累计),count表示当前字母出现的次数,accum表示当前字符在输入序列中的次序。accum是前面所有字符的count的总和。
2. count的计算可以在o(n)的时间内完成:遍历待排序数组,在散列表对应位置累加计数即可。
3. accum的计算可以在o(M)时间(即常数时间)内完成,只要将count累加即可。
4. 通过count值和accum值,即可确定当前字符在排序后的位置范围。
5. 这里只是说明桶排序对散列表的应用。更多桶排序、计数排序的原理参考

相关文章推荐
- 深入浅出Hive企业级架构优化、Hive Sql优化、压缩和分布式缓存(企业Hadoop应用核心产品)
- 深入浅出OpenStack云计算平台管理(nova-compute/network)
- 深入浅出Hive企业级架构优化、Hive Sql优化、压缩和分布式缓存(企业Hadoop应用核心产品)
- 深入浅出OpenStack云计算平台管理(nova-compute/network)
- 玩转大数据:深入浅出大数据挖掘技术(Apriori算法、Tanagra工具、决策树)
- 玩转大数据:深入浅出大数据挖掘技术(Apriori算法、Tanagra工具、决策树)
- 数据层交换和高性能并发处理(开源ETL大数据治理工具--KETTLE使用及二次开发 )
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析)
- 数据层交换和高性能并发处理(开源ETL大数据治理工具--KETTLE使用及二次开发 )
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析)
- 大数据高并发系统架构实战方案(LVS负载均衡、Nginx、共享存储、海量数据、队列缓存)
- 大数据高并发系统架构实战方案(LVS负载均衡、Nginx、共享存储、海量数据、队列缓存)
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
- 回溯法解决迷宫问题(方法2--栈)
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
- 深入浅出Hadoop实战开发(HDFS实战图片、MapReduce、HBase实战微博、Hive应用)
- 深入浅出Hadoop实战开发(HDFS实战图片、MapReduce、HBase实战微博、Hive应用)
- HBase零基础高阶应用实战(CDH5、二级索引、实践、DBA)
- HBase零基础高阶应用实战(CDH5、二级索引、实践、DBA)
- 大数据就是这么任性第一季数据结构和算法(一线经验、权威资料、知识新鲜、实践性强、全程源码)