hadoop的序列化和比较器
2016-04-11 18:02
375 查看
hadoop并没有使用java的序列化,而是使用自己的一套序列化方法,hadoop的序列化方法在org.apache.hadoop.io包里定义。 首先来看I/O接口的类图关系
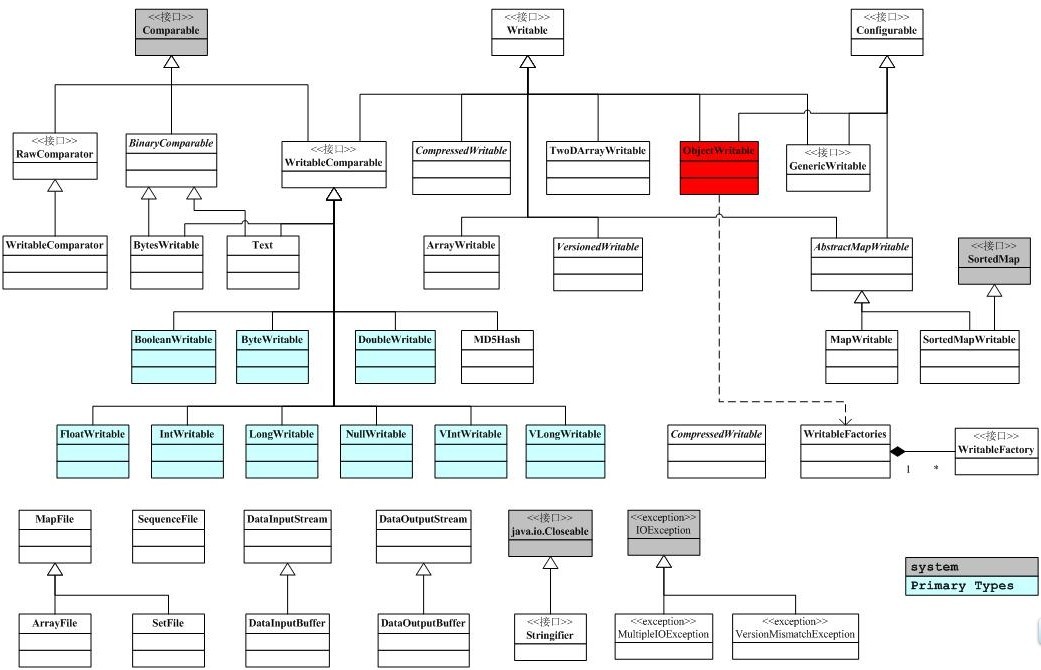
hadoop序列化的类以及比较器
1. Writable接口
只要继承了这个接口的类都可以实现序列化和反序列化。
2.Comparable接口
这个接口位于java.lang包。
3.RawComparator
RawComparator一个原生的比较器接口,用于序列化字节间的比较,即允许数据流中的比较,而不用反序列化为对象进行比较。
4.WritableComparator.
WritableComparator实现了RawComparator,该类类似于一个注册表,里面保存了所有Comparator的信息
hadoop序列化的类以及比较器
1. Writable接口
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
void write(DataOutput out) throws IOException;
//该方法实现对象的序列化
void readFields(DataInput in) throws IOException;
//该方法实现对象的反序列化
}只要继承了这个接口的类都可以实现序列化和反序列化。
2.Comparable接口
这个接口位于java.lang包。
3.RawComparator
RawComparator一个原生的比较器接口,用于序列化字节间的比较,即允许数据流中的比较,而不用反序列化为对象进行比较。
package org.apache.hadoop.io;
import java.util.Comparator;
import org.apache.hadoop.io.serializer.DeserializerComparator;
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}4.WritableComparator.
WritableComparator实现了RawComparator,该类类似于一个注册表,里面保存了所有Comparator的信息
package org.apache.hadoop.io;
import java.io.*;
import java.util.*;//java的实用工具包
import org.apache.hadoop.util.ReflectionUtils;
// registry寄存器,得到一个类的hashmap集合
public class WritableComparator implements RawComparator {
private static HashMap<Class, WritableComparator> comparators =
new HashMap<Class, WritableComparator>();
/**
hashMap作为容器类不安全,故使用synchronized同步
get方法根据key=class (c) 返回一个comparator,如果返回的是NULL则新建一个
*/
public static synchronized WritableComparator get(Class<? extends WritableComparable> c) {
WritableComparator comparator = comparators.get(c);
if (comparator == null)
comparator = new WritableComparator(c, true);
return comparator;
}
public static synchronized void define(Class c,
WritableComparator comparator) {
comparators.put(c, comparator);
//将c-comparator对放进注册表中,也使用同步
}
private final Class<? extends WritableComparable> keyClass;
private final WritableComparable key1;
private final WritableComparable key2;
private final DataInputBuffer buffer;
/** Construct for a {@link WritableComparable} implementation. */
protected WritableComparator(Class<? extends WritableComparable> keyClass) {
this(keyClass, false);
}
protected WritableComparator(Class<? extends WritableComparable> keyClass,
boolean createInstances) {
this.keyClass = keyClass; //根据createInstances来确定是否实例化key1,key2,keyClass
if (createInstances) {
key1 = newKey();
key2 = newKey();
buffer = new DataInputBuffer();
} else {
key1 = key2 = null;
buffer = null;
}
}
/** Returns the WritableComparable implementation class. */
public Class<? extends WritableComparable> getKeyClass() { return keyClass; } //返回类
/** Construct a new {@link WritableComparable} instance. */
public WritableComparable newKey() { //新建一个实例
return ReflectionUtils.newInstance(keyClass, null);
}
/** Optimization hook. Override this to make SequenceFile.Sorter's scream.
*
* <p>The default implementation reads the data into two {@link
* WritableComparable}s (using {@link
* Writable#readFields(DataInput)}, then calls {@link
* #compare(WritableComparable,WritableComparable)}.
*/
//比较的方法
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // compare them
}
/** Compare two WritableComparables.
*
* <p> The default implementation uses the natural ordering, calling {@link
* Comparable#compareTo(Object)}. */
@SuppressWarnings("unchecked")
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b); //比较的方法
}
public int compare(Object a, Object b) {
return compare((WritableComparable)a, (WritableComparable)b); //比较的方法
}
/** Lexicographic order of binary data. */
//比较二进制的数据
public static int compareBytes(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
int end1 = s1 + l1;
int end2 = s2 + l2;
for (int i = s1, j = s2; i < end1 && j < end2; i++, j++) {
int a = (b1[i] & 0xff);
int b = (b2[j] & 0xff);
if (a != b) {
return a - b;
}
}
return l1 - l2;
}
/** Compute hash for binary data. */
public static int hashBytes(byte[] bytes, int offset, int length) {
int hash = 1;
for (int i = offset; i < offset + length; i++)
hash = (31 * hash) + (int)bytes[i];
return hash;
}
/** Compute hash for binary data. */
public static int hashBytes(byte[] bytes, int length) {
return hashBytes(bytes, 0, length);
}
//以下为实现WritableComparator的各种实例
/** Parse an unsigned short from a byte array. */
public static int readUnsignedShort(byte[] bytes, int start) {
return (((bytes[start] & 0xff) << 8) +
((bytes[start+1] & 0xff)));
}
/** Parse an integer from a byte array. */
public static int readInt(byte[] bytes, int start) {
return (((bytes[start ] & 0xff) << 24) +
((bytes[start+1] & 0xff) << 16) +
((bytes[start+2] & 0xff) << 8) +
((bytes[start+3] & 0xff)));
}
/** Parse a float from a byte array. */
public static float readFloat(byte[] bytes, int start) {
return Float.intBitsToFloat(readInt(bytes, start));
}
/** Parse a long from a byte array. */
public static long readLong(byte[] bytes, int start) {
return ((long)(readInt(bytes, start)) << 32) +
(readInt(bytes, start+4) & 0xFFFFFFFFL);
}
/** Parse a double from a byte array. */
public static double readDouble(byte[] bytes, int start) {
return Double.longBitsToDouble(readLong(bytes, start));
}
public static long readVLong(byte[] bytes, int start) throws IOException {
int len = bytes[start];
if (len >= -112) {
return len;
}
boolean isNegative = (len < -120);
len = isNegative ? -(len + 120) : -(len + 112);
if (start+1+len>bytes.length)
throw new IOException(
"Not enough number of bytes for a zero-compressed integer");
long i = 0;
for (int idx = 0; idx < len; idx++) {
i = i << 8;
i = i | (bytes[start+1+idx] & 0xFF);
}
return (isNegative ? (i ^ -1L) : i);
}
public static int readVInt(byte[] bytes, int start) throws IOException {
return (int) readVLong(bytes, start);
}
}//将字节型的转化为VInt

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- 简单易懂云计算(转自天涯感谢原楼主iamsatisfied)
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 2011云计算知识库:盘点千奇百怪的云名称
- 单机版搭建Hadoop环境图文教程详解
- C#自定义序列化ISerializable的实现方法
- c#数据的序列化和反序列化(推荐版)
- hadoop常见错误以及处理方法详解
- c#序列化详解示例
- c#对象反序列化与对象序列化示例详解
- .net实现序列化与反序列化实例解析
- C#实现复杂XML的序列化与反序列化
- C#中Serializable序列化实例详解
- asp.net类序列化生成xml文件实例详解
- C#实现的json序列化和反序列化代码实例
- C#序列化与反序列化(Serialize,Deserialize)实例详解
- C#二进制序列化实例分析
- jQuery与Ajax以及序列化
- asp.net 序列化and反序列化演示