Unicode UTF-8与GB18030编码解析(golang)
2016-04-08 01:33
399 查看
最早接触到编码问题时,无非是关于『乱码』一词,当某个程序或者网页或者数据库或者IDE中一看出现了乱码,就马上知道这是字符编码与解码不匹配,改下编码就好,就因为这个事情太简单,容易解决,甚至在一段时间看到一段乱码文字形状,就知道这肯定是xxx编码转为yyy编码存储然后又用xxx来显示导致的。。。
从来没有去纠结到底为什么有这么多编码,到底为何需要转换?是怎么转换的?如何转换?为什么都通用utf-8还有很多新项目在用GBK呢?
折腾了1个晚上,我明白了。。。以下我都用我自己理解的语言来描述下,分享下
打印一个字符的Ascii码很简单
最早接触GB 2312一词也是在大学的时候,做网站,如果meta头里面不加上
通俗来讲,GB 2312规定的一个汉字用16个二进制的0或者1来存储,像一部几千字的新华字典,按照编号一个个的编了进去。
GB2312编码范围:A1A1(101010001 10100001)到FEFE,A1A1-B0A1之间的是特殊符号,还记得小时候有个输入法叫『智能ABC』么?输入法里面的v1-v9就会出来特殊符号(玩WOW的时候经常用来给昵称加特殊字符)正好就是GB2312编码表最前面的特殊字符部分。。


汉字的编码范围为B0A1-F7FE
B0A1是『啊』,B0A2是『阿』。。。。真的是按照新华字典方式,D7F9是『座』标准汉字的最后一个,D7F9-F7FE是那一堆不太常用,或者都没人认识的汉字。
突然想到了『汉卡』一词,不知道还有没有人记得这个东西,80年代到90年代初的计算机不支持中文,中国当年的很多计算机人才研制出来『汉卡』的硬件,插入到IBM的电脑上之后,就可以进行文字输入与显示,汉卡就是采用GB2312编码将汉字显示出来的硬件处理工具。在那个时期的所有计算机,都是要插入汉卡才能显示与输入汉字。联想Lenovo叫『联想』,就是因为柳传志的Team做了最早有联想功能的汉卡。
GB后来又有了新的发展,都是以GB2312为基础进行扩展,GBK是扩展升级版,GB18030是再扩展升级,支持的图形与文字越来越多。值得一说的是,GB2312与GBK对任意一个图形字符都采用两个字节表示。因为GB18030增加了繁体字、日韩、以及少数民族文字,超出了216 个,也是吸取了UTF-8的处理方式,是由1个、2个或4个字节组成。GB18030的设计初衷我猜测也是因为一个文件只能采用1中编码方式,如果中文中混合了日文、韩文等文字,那么就非常麻烦了,所以GB18030把中国的文章中可能出现的周边的最常用的语言文字都加入在内。
总结下GB编码:
1. 是中国人自己做的国家标准,没跟老外商量。不兼容国外其他标准。
2. GB标准是国家出的,在某些国家项目招标中是强制使用的
3. GB18030的编码最符合中文存储,占用空间最小,所以从成本考虑在中文字库芯片一般都是最高只支持GB18030。
4. GB18030兼容GBK,GBK兼容GB2312,所以GB2312可以随意转换为GBK或者GB18030不会有转换错误问题
Unicode就是这么诞生的,最初UCS-2所有字符都采用2个字节编码,理论上可以表示216 个,但中文的繁体与简体全部加起来有6-7万个,在UCS-2中去掉了不常用的汉字,当然简体中文中常用的字也就7000多个,去掉的无非是根本不会用到汉字以及做考古、科研、异形字。。。
后来发现2位不够,所以又推出来了UCS-4标准,全世界都用4个字节表示所有字符,好处是标准化,内容多,例如emoji表情符号都加入了进来,缺点就是所有字符都用4字节存储,占空间。
在这里要检讨下,之前写的不严谨,因为UTF-8意外编码很少用到,被网友指出错误,那就赶紧改正。
有人说Unicode编码实际上不能叫编码(这是个文学问题),Unicode是对ASCII的全球化扩展,它的使用共有两部分,一是给所有的字符指定一个唯一对应的数字(数学问题),二是将这个数字存储到内存的方法,即变量保存到内存的数据结构以及在传输时的编码(编码问题)
UTF的缩写是Unicode Transformation Format,它是Unicode的传输格式的一个标准
其实对于golang这个语言来讲,可以更好的理解Unicode编码,在所有的情况中,只要是涉及保存到内存中的数据,对于字符串都是UTF-8编码存储,然后取出来的时候,为了方便进行字符处理,for...range之后变成了Unicode的码点值的整型数据。
后面的UTF标准,都是对UCS-2、UCS-4进行的存储编码方式。
Unicode转UTF-8的方式如下:
UTF-8的编码存储空间更合理,但是进行编码的效率降低了,这就是所谓的用时间换空间。
还有个缺点对于几乎所有中文都分不到了0000 0800-0000 FFFF区间,也就是说,中文在UTF-8里面几乎占用的都是3个字节。所以如果存储中文要比GB编码的多50%的存储空间。
貌似大部分的常用字符都是在0x10000以下。
但是对于0x10000以上的编码与Unicode码点值并不相同,甚至可能是4个字节。
Unicode 中字为U+4E2D,UTF-32为00004E2D
为了能够识别当前编码采用什么类型,在文件头部加入BOM来区分,BOM只能区分Unicode系列的编码方式
Golang中stirng变量支持UTF-8以及Unicode的编码,所以在定义string时可以有以下几种
以上方法中,第一个必须将文件或者编辑器设置为UTF-8否则将无法运行。其他两种没有此限制
Go source code is always UTF-8.
如果文件字符内容采用了非UTF-8编码存储,或者说是用UTF-8解码解不了的,那么将在编译过程中报错。
golang的string变量都默认以UTF-8进行编码存储,所以在计算str长度时为19
下图是Go数据底层的存储


上图部分来自于build-web-application-with-golang
说起golang的字符Unicode编码就不能不说Rune,Rune在golang里面是int32类型的别名(不知道为啥不是uint32),主用用来记录字符的码点值即unicode字符类型编码。Go里面也有直接定义数值类型:rune, int8, int16, int32, int64和byte, uint8, uint16, uint32, uint64。byte是uint8的别称。没有C的Char类型,但是可以类似char的方式来使用:
也就是说,类似C的单引号的字符,在golang里面依旧兼容,只是用int来代替,并且C的是单字符的ASCII码,而Golang为32位字节的Unicode码点值。
以上代码将输出:

rune作为数据类型有2个类型转换方法
前者是传入的字符、int类型,后者可以传入的是字符串类型,返回的是rune切片。
rune的问题,上面打印过
for ... range的遍历也是采用rune的方式,每次都是返回的rune类型的码点值,index则仍然按照utf-8的字符存储方式计算
运行结果为:
结果是a1=a2 但是b1!=b2
Printf的实现原理是将变量的存储类型byte转换为了前面的自定义类型%x,a1与a2在内存中的一个是o的unicode编码int类型,值为111,另外一个是字符串o的utf-8编码也是111,他们在转换为16进制时都为6f
b1与b2就不同了:
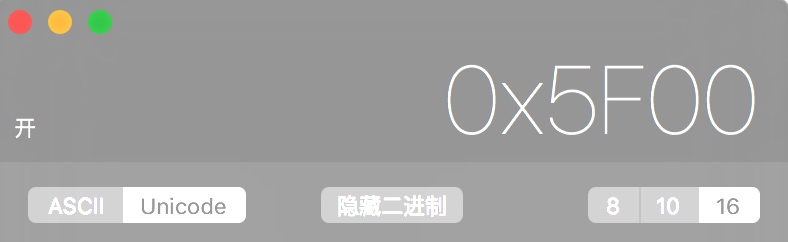
b1是字符『开』的unicode码点值int32=24320
b2在内存中存储的是字符开的UTF-8编码也就是,汉字是三个字节即
首先说明下,在百度里面搜索UTF-8转汉字的基本都是Unicode.



上图可以看出,5F00实际上是开字的Unicode码点值。
如何快速的验证一个utf-8编码,这里有个技巧:
下面是一个百度的搜索地址:
https://www.baidu.com/s?wd=%E5%BC%80%E6%BA%90%E4%B8%AD%E5%9B%BD
将每个字节用%隔开进行拼接,例如:『开』的UTF-8编码为e5bc80那么就是%E5%BC%80,后面相同。打开浏览器之后,就可以看到这个UTF-8编码是什么字符了。这也是各种语言版本中
反之操作也可以,使用百度搜索个关键词,那么在url get参数wd就是关键词的utf-8编码。但是一般目前主流的浏览器都会自作多情的将URL地址栏里面的UTF-8编码转化为字符串显示出来(Urldecode过)
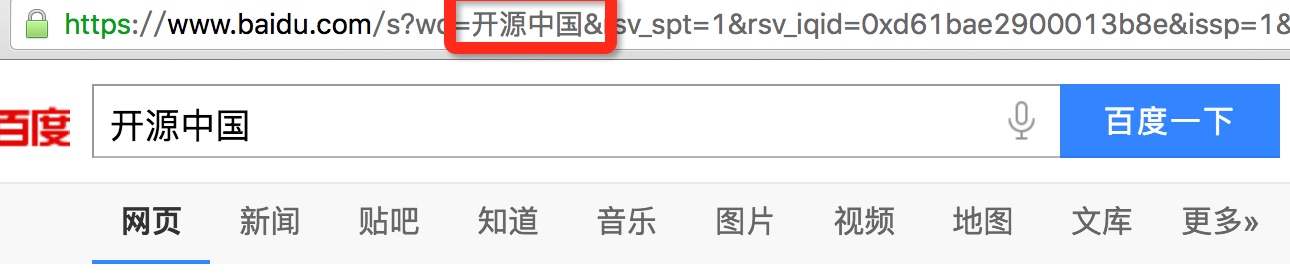

所以只要复制下链接,粘贴到记事本区域就可以看到真实的URL地址
GBK与Unicode编码转换的原理无非是将A编码的UNICODE码点值,拿出来去Table查一下,查出A的GBK编码二进制表示形式,然后保存到一个新的变量,存储该二进制数据。
golang有现成的编码转换类库
顺便说句题外话,七牛是个值得尊敬的研发企业,整个团队为golang在中国的发展做了很多贡献。
其中bfaa为开字的GBK编码
汉字编码查询转化网站
OK,结束语,这篇文字写了好几天,因为最近工作太忙总是被打断。随着年龄的增加,越来越感觉到『积累』的重要性,所以以后我觉得还是坚持把博客写下去,通过写这篇文章也是更加夯实了一些技术知识,算是有一个去积累的目标与让自己积累的过程。
从来没有去纠结到底为什么有这么多编码,到底为何需要转换?是怎么转换的?如何转换?为什么都通用utf-8还有很多新项目在用GBK呢?
折腾了1个晚上,我明白了。。。以下我都用我自己理解的语言来描述下,分享下
ASCII编码
美国人发明计算机,美国人用八位表示1字节,8位的数据可以有28 =256 种状态描述事物。首先他添加进去了26个字母包括大小写,然后标点符号,换行符...然后用掉了128个,把这种做法取了个很吊名字叫『Ascii』,是『美国信息互换标准代码』的缩写。这也是我们小时候学习计算机的Ascii码表,当时貌似在C语言课本附录里面。打印一个字符的Ascii码很简单
fmt.Printf("%d", 'A')GB系列编码
很明显,这个American Standard 从未考虑中国人的感受,你可以显示字母就完事了,中国的国粹汉字咋整?所以在中国的一群人开始做自己的编码,那是在1980年,做出来的是GB 2312-80也就是GB2312,实现原理是用两个字节表示汉字,127以下的还是按照ASCII标准,因为有了2个字节,理论上可以有216 -128 = 65535-128种表示汉字的方式。最早接触GB 2312一词也是在大学的时候,做网站,如果meta头里面不加上
charset=gb2312那网页显示就是乱码,因为早期的浏览器默认编码是ISO-xxx,如果不在页面强制标示为gb2312,那么就会被使用ISO的方式来解析gb2312编码后的中文,肯定会出现一堆不知道什么语言的文字。
通俗来讲,GB 2312规定的一个汉字用16个二进制的0或者1来存储,像一部几千字的新华字典,按照编号一个个的编了进去。
GB2312编码范围:A1A1(101010001 10100001)到FEFE,A1A1-B0A1之间的是特殊符号,还记得小时候有个输入法叫『智能ABC』么?输入法里面的v1-v9就会出来特殊符号(玩WOW的时候经常用来给昵称加特殊字符)正好就是GB2312编码表最前面的特殊字符部分。。

汉字的编码范围为B0A1-F7FE
B0A1是『啊』,B0A2是『阿』。。。。真的是按照新华字典方式,D7F9是『座』标准汉字的最后一个,D7F9-F7FE是那一堆不太常用,或者都没人认识的汉字。
突然想到了『汉卡』一词,不知道还有没有人记得这个东西,80年代到90年代初的计算机不支持中文,中国当年的很多计算机人才研制出来『汉卡』的硬件,插入到IBM的电脑上之后,就可以进行文字输入与显示,汉卡就是采用GB2312编码将汉字显示出来的硬件处理工具。在那个时期的所有计算机,都是要插入汉卡才能显示与输入汉字。联想Lenovo叫『联想』,就是因为柳传志的Team做了最早有联想功能的汉卡。
GB后来又有了新的发展,都是以GB2312为基础进行扩展,GBK是扩展升级版,GB18030是再扩展升级,支持的图形与文字越来越多。值得一说的是,GB2312与GBK对任意一个图形字符都采用两个字节表示。因为GB18030增加了繁体字、日韩、以及少数民族文字,超出了216 个,也是吸取了UTF-8的处理方式,是由1个、2个或4个字节组成。GB18030的设计初衷我猜测也是因为一个文件只能采用1中编码方式,如果中文中混合了日文、韩文等文字,那么就非常麻烦了,所以GB18030把中国的文章中可能出现的周边的最常用的语言文字都加入在内。
总结下GB编码:
1. 是中国人自己做的国家标准,没跟老外商量。不兼容国外其他标准。
2. GB标准是国家出的,在某些国家项目招标中是强制使用的
3. GB18030的编码最符合中文存储,占用空间最小,所以从成本考虑在中文字库芯片一般都是最高只支持GB18030。
4. GB18030兼容GBK,GBK兼容GB2312,所以GB2312可以随意转换为GBK或者GB18030不会有转换错误问题
U系列编码
Unicode系列
其实类似中国这样做法的有很多,作为ISO这样的组织其实不希望每个国家采用每个国家自己的编码方式,一定要像秦始皇那样统一大家的所有编码方式。Unicode就是这么诞生的,最初UCS-2所有字符都采用2个字节编码,理论上可以表示216 个,但中文的繁体与简体全部加起来有6-7万个,在UCS-2中去掉了不常用的汉字,当然简体中文中常用的字也就7000多个,去掉的无非是根本不会用到汉字以及做考古、科研、异形字。。。
后来发现2位不够,所以又推出来了UCS-4标准,全世界都用4个字节表示所有字符,好处是标准化,内容多,例如emoji表情符号都加入了进来,缺点就是所有字符都用4字节存储,占空间。
在这里要检讨下,之前写的不严谨,因为UTF-8意外编码很少用到,被网友指出错误,那就赶紧改正。
有人说Unicode编码实际上不能叫编码(这是个文学问题),Unicode是对ASCII的全球化扩展,它的使用共有两部分,一是给所有的字符指定一个唯一对应的数字(数学问题),二是将这个数字存储到内存的方法,即变量保存到内存的数据结构以及在传输时的编码(编码问题)
UTF的缩写是Unicode Transformation Format,它是Unicode的传输格式的一个标准
其实对于golang这个语言来讲,可以更好的理解Unicode编码,在所有的情况中,只要是涉及保存到内存中的数据,对于字符串都是UTF-8编码存储,然后取出来的时候,为了方便进行字符处理,for...range之后变成了Unicode的码点值的整型数据。
后面的UTF标准,都是对UCS-2、UCS-4进行的存储编码方式。
UTF-8
Unicode是国际化标准但是这种编码方式很难推广,UTF-8诞生就是解决了他占用空间问题,采用变长的编码方式,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示。所以作为国际化标准的很容易被推广起来。Unicode转UTF-8的方式如下:
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
还有个缺点对于几乎所有中文都分不到了0000 0800-0000 FFFF区间,也就是说,中文在UTF-8里面几乎占用的都是3个字节。所以如果存储中文要比GB编码的多50%的存储空间。
UTF-16
是Unicode的其中一个使用方式,现在大多数UTF-16也是2个byte组成的。Unicode值小于0x10000的用等于该值的16位整数来表示。貌似大部分的常用字符都是在0x10000以下。
Unicode 『中』字为U+4E2D,UTF-16为4E2D
但是对于0x10000以上的编码与Unicode码点值并不相同,甚至可能是4个字节。
UTF-32
Unicode的UTF-32编码就是其对应的 32位无符号整数,定长4位。可以这么理解UTF-32实际上就是UCS-4的直接表达方式。Unicode 中字为U+4E2D,UTF-32为00004E2D
BOM字节序
填充方式可以不一样,于是就出现了Big-Endian,Little-Endian的术语.Big-Endian就是从左到右,Little-Endian是从右到左| Unicode编码 | UTF-16LE | UTF-16BE | UTF32-LE | UTF32-BE |
|---|---|---|---|---|
| 0x006C49 | 49 6C | 6C 49 | 49 6C 00 00 | 00 00 6C 49 |
| 0x020C30 | 43 D8 30 DC | D8 43 DC 30 | 30 0C 02 00 | 00 02 0C 30 |
| BOM头 | 编码格式 |
|---|---|
| EF BB BF | UTF-8 |
| FE FF | UTF-16/UCS-2, little endian |
| FF FE | UTF-16/UCS-2, big endian |
| FF FE 00 00 | UTF-32/UCS-4, little endian. |
| 00 00 FE FF | UTF-32/UCS-4, big-endian. |
Experiment
首先Golang中stirng变量支持UTF-8以及Unicode的编码,所以在定义string时可以有以下几种
//print oschina开源中国 var str = "oschina开源中国" //基于unicode UCS-2的码点值定义 var str2 = "\u006f\u0073\u0063\u0068\u0069\u006e\u0061\u5f00\u6e90\u4e2d\u56fd" //基于unicode UCS-4的码点值定义 var str3 = "\U0000006f\U00000073\U00000063\U00000068\U00000069\U0000006e\U00000061\U00005f00\U00006e90\U00004e2d\U000056fd"
以上方法中,第一个必须将文件或者编辑器设置为UTF-8否则将无法运行。其他两种没有此限制
Go source code is always UTF-8.
如果文件字符内容采用了非UTF-8编码存储,或者说是用UTF-8解码解不了的,那么将在编译过程中报错。
golang的string变量都默认以UTF-8进行编码存储,所以在计算str长度时为19
//oschina开源中国 7个英文+ 4个汉字 = 7 + 12 = 19
fmt.Printf("%d", len(str))下图是Go数据底层的存储

上图部分来自于build-web-application-with-golang
先从最简单的Unicode开始:
Rune说起golang的字符Unicode编码就不能不说Rune,Rune在golang里面是int32类型的别名(不知道为啥不是uint32),主用用来记录字符的码点值即unicode字符类型编码。Go里面也有直接定义数值类型:rune, int8, int16, int32, int64和byte, uint8, uint16, uint32, uint64。byte是uint8的别称。没有C的Char类型,但是可以类似char的方式来使用:
var x = 'o' var x2 = "o" var x3 = '开' fmt.Println(reflect.TypeOf(x)) //print int32 值为111 fmt.Println(reflect.TypeOf(x2)) //print string fmt.Println(reflect.TypeOf(x3)) //print int32 值为24320
也就是说,类似C的单引号的字符,在golang里面依旧兼容,只是用int来代替,并且C的是单字符的ASCII码,而Golang为32位字节的Unicode码点值。
可以支持单个中文字符,golang作为一个新时代的语言,它扩展了原始char的标示范围,将Unicode编码替换了C的ASCII码。打印一个Unicode码点值使用%#U或%U格式如下:
var x3 = '开'
fmt.Printf("%#U", x3)以上代码将输出:
U+5F00 '开'

rune作为数据类型有2个类型转换方法
rune()与
[]rune()
前者是传入的字符、int类型,后者可以传入的是字符串类型,返回的是rune切片。
rune的问题,上面打印过
var str = "oschina开源中国"的len为19,如果想要打印字符的数量,可以通过将utf-8编码存储的字符串转为rune切片类型,然后再计算下切片的长度就可以知道是多少个unicode字符了。
var str = "oschina开源中国"
fmt.Printf("string '%s' 有%d个字 \n", str, len([]rune(str)))
//输出:string 'oschina开源中国' 有11个字for ... range的遍历也是采用rune的方式,每次都是返回的rune类型的码点值,index则仍然按照utf-8的字符存储方式计算
const site = "oschina开源中国"
for index, runeValue := range site {
fmt.Printf("%#U starts at byte position %d\n", runeValue, index)
}运行结果为:
U+006F 'o' starts at byte position 0 U+0073 's' starts at byte position 1 U+0063 'c' starts at byte position 2 U+0068 'h' starts at byte position 3 U+0069 'i' starts at byte position 4 U+006E 'n' starts at byte position 5 U+0061 'a' starts at byte position 6 U+5F00 '开' starts at byte position 7 U+6E90 '源' starts at byte position 10 U+4E2D '中' starts at byte position 13 U+56FD '国' starts at byte position 16
UTF-8编码
首先我真的很想给golang的应聘者出个面试题目fmt.Printf("%x\n", var)是打印var的16进制编码,那么以下四个输出,a1,a2的关系还有b1,b2的关系是怎么样的?var a1 = 'o'
var a2 = "o"
var b1 = '开'
var b2 = "开"
fmt.Printf("%x\n", a1)
fmt.Printf("%x\n", a2)
fmt.Printf("%x\n", b1)
fmt.Printf("%x\n", b2)结果是a1=a2 但是b1!=b2
Printf的实现原理是将变量的存储类型byte转换为了前面的自定义类型%x,a1与a2在内存中的一个是o的unicode编码int类型,值为111,另外一个是字符串o的utf-8编码也是111,他们在转换为16进制时都为6f
b1与b2就不同了:
b1是字符『开』的unicode码点值int32=24320
b2在内存中存储的是字符开的UTF-8编码也就是,汉字是三个字节即
e5 bc 80所以打印的结果也是
e5bc80
首先说明下,在百度里面搜索UTF-8转汉字的基本都是Unicode.


上图可以看出,5F00实际上是开字的Unicode码点值。
如何快速的验证一个utf-8编码,这里有个技巧:
下面是一个百度的搜索地址:
https://www.baidu.com/s?wd=%E5%BC%80%E6%BA%90%E4%B8%AD%E5%9B%BD
将每个字节用%隔开进行拼接,例如:『开』的UTF-8编码为e5bc80那么就是%E5%BC%80,后面相同。打开浏览器之后,就可以看到这个UTF-8编码是什么字符了。这也是各种语言版本中
urlencode函数干的事情。
反之操作也可以,使用百度搜索个关键词,那么在url get参数wd就是关键词的utf-8编码。但是一般目前主流的浏览器都会自作多情的将URL地址栏里面的UTF-8编码转化为字符串显示出来(Urldecode过)

所以只要复制下链接,粘贴到记事本区域就可以看到真实的URL地址
GBK编码
Unicode与UTF-8是一对一的关系,即通过简单的编码原理就可以写出编码算法,但是unicode与GBK就不一样了,GBK是根据汉语拼音来编码的,unicode对中文是按照偏旁与笔画进行编码,也就是说你无法根据文字的偏旁与笔画推导出他的发音,只能搞个目录的东西类似于字典的目录一样,去查一下通过部首查拼音,通过拼音查部首。还好最早微软就把字典给公开了出来,也就是CP936与自家UCS-2的对照文本,基本这个文本,就可以很容易的看到每一个GBK编码的字符与Unicode码之间的对应关系。就是几万个字节而已的一个Table.GBK与Unicode编码转换的原理无非是将A编码的UNICODE码点值,拿出来去Table查一下,查出A的GBK编码二进制表示形式,然后保存到一个新的变量,存储该二进制数据。
golang有现成的编码转换类库
import ( "github.com/qiniu/iconv" ... )
顺便说句题外话,七牛是个值得尊敬的研发企业,整个团队为golang在中国的发展做了很多贡献。
var str = "开源中国"
cd, err := iconv.Open("gbk", "utf-8") // convert utf-8 to gbk
if err != nil {
fmt.Println("iconv.Open failed!")
return
}
defer cd.Close()
gbk := cd.ConvString(str)
fmt.Printf("%x", gbk)
//will print bfaad4b4d6d0b9fa6f其中bfaa为开字的GBK编码
汉字编码查询转化网站
OK,结束语,这篇文字写了好几天,因为最近工作太忙总是被打断。随着年龄的增加,越来越感觉到『积累』的重要性,所以以后我觉得还是坚持把博客写下去,通过写这篇文章也是更加夯实了一些技术知识,算是有一个去积累的目标与让自己积累的过程。

相关文章推荐
- Google Test(GTest)使用方法和源码解析——死亡测试技术分析和应用
- Google Test(GTest)使用方法和源码解析——模板类测试技术分析和应用
- GooglePlayServicesClient找不到
- Google Test(GTest)使用方法和源码解析——参数自动填充技术分析和应用
- Google Test(GTest)使用方法和源码解析——自定义输出技术的分析和应用
- Google Test(GTest)使用方法和源码解析——预处理技术分析和应用
- Google Test(GTest)使用方法和源码解析——断言的使用方法和解析
- Google Test(GTest)使用方法和源码解析——Listener技术分析和应用
- Google Test(GTest)使用方法和源码解析——结果统计机制分析
- Google Test(GTest)使用方法和源码解析——自动调度机制分析
- Google Test(GTest)使用方法和源码解析——概况
- django 1.8 日志配置
- Django模板中的复数显示及国际化
- 在visual studio 2013下使用Google Mock
- Google推荐的图片加载库Glide介绍
- Django中的Model(字段) - 第五轻柔的code - 博客园
- [HDU 4855] Goddess (极角排序+三分)
- Django中的Model(操作表) - 第五轻柔的code - 博客园
- 筛素数——POJ 2909 Goldbach's Conjecture
- Google Chrome源码剖析【五】:插件模型