hadoop2.2 伪分布式环境
2016-04-07 10:20
344 查看
在安装JDK之前,请确认系统是32还是64,根据系统版本,选择JDK版本、Hadoop版本
下面是以在CentOS-6.5-x86_64系统上安装为例
安装前准备
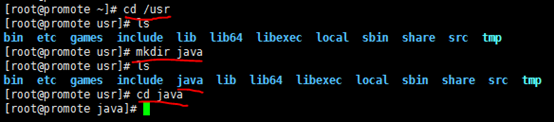
在"/usr"下创建java目录,并cd到该目录,如下
确认防火墙关闭
防火墙关闭后的效果如下

具体操作,请查看"XX/XX/XX/ notes/防火墙.docx"
确认安装openssh-server、openssh-clients,具体操作,请参考"XX/XX/XX/notes/安全登录ssh.docx"文件
JDK安装
上传JDK
使用rz命令,进行文件上传,效果如下图

rz安装过程,请参考"XX/XX/XX/上传下载lrzsz"
rz具体操作,请参考"XX/notes/command/上传下载rz、sz命令.docx"
解压"jdk-7u79-linux-x64.gz"
输入"tar -zxvf jdk-7u79-linux-x64.gz"命令进行解压,如下图

解压后的效果

tar具体操作,请参考"XX/notes/command/打包tar命令.docx"
设置JDK环境变量
在"/etc/profile.d"下创建"java.sh"脚本来配置环境变量


通过source命令,使"java.sh"生效;使用java –version看看jdk是否安装成功,如下

具体配置环境变量,请参考"XX\jdk\环境变量.docx"
ip与hostname做关联
输入"ifconfig",查看系统ip

建议改成静态ip,具体操作,请参考相应系统下的"通信配置.docx"
编辑hosts文件,如下

主机名是"ljc",效果如下

保存,退出
创建hadoop用户
创建hadoop用户组

创建hadoop用户

设置hadoop密码
SSH配置
切换到hadoop用户
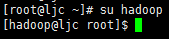
输入"ssh-keygen -t rsa",生成秘钥

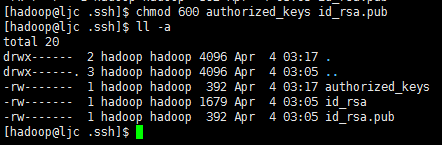
进入到.ssh目录,使用"cp id_rsa.pub authorized_keys"命令,把公钥复制到认证文件(authorized_keys)中,如下所示

确保.ssh目录的权限是700(使用chmod 700 .ssh命令修改),确保authorized_key、id_rsa.pub文件的权限是600(使用chmod 600 authorized_keys id_rsa.pub命令修改),如下所示

Hadoop环境配置
切换到"/usr/java"目录下,将准备好hadoop安装包"hadoop-2.2.0-x64.tar.gz"上传,如下所示
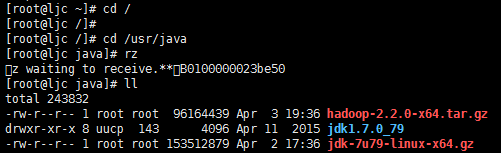
将"hadoop-2.2.0-x64.tar.gz"文件进行解压


将"hadoop-2.2.0"改为"hadoop",如下所示

使用chown命令,修改hadoop的权限,如下

创建hadoop数据目录并修改/data目录的所有人为hadoop、组为hadoop,如下所示

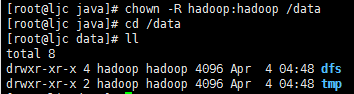
/data/dfs/name:namenode的文件目录
/data/dfs/data:datanode的文件目录
/data/tmp:存放数据的公共目录
修改hadoop配置文件

修改内容如下:
core-site.xml
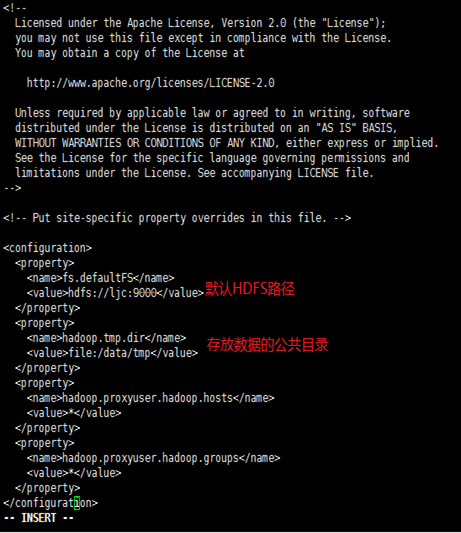
hdfs-site.xml

mapred-site.xml
根据mapred-site.xml.template复制一份,并改名为mapred-site.xml


yarn-site.xml

slaves

设置hadoop环境变量
以root用户,编辑"/etc/profile",如下所示

在文件最后添加如下内容

保存,退出
使用source命令,使文件生效

测试运行
切换到hadoop用户下

格式化namenode,如下所示
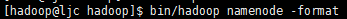
启动集群,如下所示
查看集群启动情况,如下,说明集群启动成功

在window下,配置hostname与ip的对应关系,便于我们的访问
修改"C:\Windows\System32\drivers\etc\hosts"文件,如下

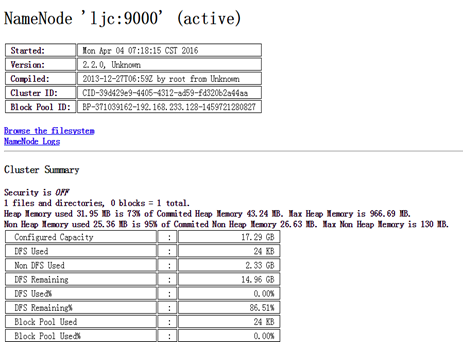
输入http://ljc:50070/dfshealth.jsp,查看namenode、文件系统的状态
使用hadoop自带的WordCount程序来测试运行一下
创建测试文件ljc.txt,在当前目录下已给出
在hdfs上创建buaa目录,如下

将刚刚创建的ljc.txt上传到hdfs中的/buaa目录下,如下

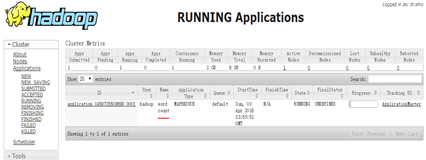
打开http://ljc:8088/cluster/apps,动态查看作业运行情况

单击"RUNNING",发现没有正在运行的程序

输入"bin/hadoop -jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /buaa/ljc.txt /buaa/wordcount-out",运行wordcount程序,如下所示

单击"RUNNING",查看作业运行状态
运行完成,单击"FINSHED",如下

输入http://ljc:50070/dfshealth.jsp,查看运行结果
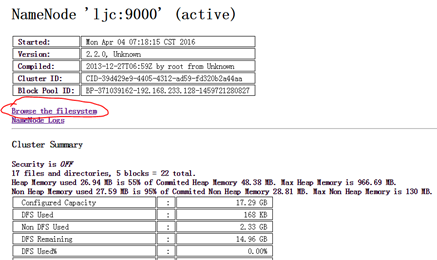
单击"Browse the filesystem",打开如下界面

单击"buaa",打开如下界面

单击"wordcount-out",打开如下界面

单击"part-r-00000",打开如下界面

和我们从ljc.txt文件看出来的结果是一致的
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【刘超★ljc】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
下面是以在CentOS-6.5-x86_64系统上安装为例
安装前准备
在"/usr"下创建java目录,并cd到该目录,如下
确认防火墙关闭
防火墙关闭后的效果如下
具体操作,请查看"XX/XX/XX/ notes/防火墙.docx"
确认安装openssh-server、openssh-clients,具体操作,请参考"XX/XX/XX/notes/安全登录ssh.docx"文件
JDK安装
上传JDK
使用rz命令,进行文件上传,效果如下图
rz安装过程,请参考"XX/XX/XX/上传下载lrzsz"
rz具体操作,请参考"XX/notes/command/上传下载rz、sz命令.docx"
解压"jdk-7u79-linux-x64.gz"
输入"tar -zxvf jdk-7u79-linux-x64.gz"命令进行解压,如下图
解压后的效果
tar具体操作,请参考"XX/notes/command/打包tar命令.docx"
设置JDK环境变量
在"/etc/profile.d"下创建"java.sh"脚本来配置环境变量
通过source命令,使"java.sh"生效;使用java –version看看jdk是否安装成功,如下
具体配置环境变量,请参考"XX\jdk\环境变量.docx"
ip与hostname做关联
输入"ifconfig",查看系统ip
建议改成静态ip,具体操作,请参考相应系统下的"通信配置.docx"
编辑hosts文件,如下
主机名是"ljc",效果如下
保存,退出
创建hadoop用户
创建hadoop用户组
创建hadoop用户
设置hadoop密码
SSH配置
切换到hadoop用户
输入"ssh-keygen -t rsa",生成秘钥
进入到.ssh目录,使用"cp id_rsa.pub authorized_keys"命令,把公钥复制到认证文件(authorized_keys)中,如下所示
确保.ssh目录的权限是700(使用chmod 700 .ssh命令修改),确保authorized_key、id_rsa.pub文件的权限是600(使用chmod 600 authorized_keys id_rsa.pub命令修改),如下所示
Hadoop环境配置
切换到"/usr/java"目录下,将准备好hadoop安装包"hadoop-2.2.0-x64.tar.gz"上传,如下所示
将"hadoop-2.2.0-x64.tar.gz"文件进行解压
将"hadoop-2.2.0"改为"hadoop",如下所示
使用chown命令,修改hadoop的权限,如下
创建hadoop数据目录并修改/data目录的所有人为hadoop、组为hadoop,如下所示
/data/dfs/name:namenode的文件目录
/data/dfs/data:datanode的文件目录
/data/tmp:存放数据的公共目录
修改hadoop配置文件
修改内容如下:
core-site.xml
hdfs-site.xml
mapred-site.xml
根据mapred-site.xml.template复制一份,并改名为mapred-site.xml
yarn-site.xml
slaves
设置hadoop环境变量
以root用户,编辑"/etc/profile",如下所示
在文件最后添加如下内容
保存,退出
使用source命令,使文件生效
测试运行
切换到hadoop用户下
格式化namenode,如下所示
启动集群,如下所示
查看集群启动情况,如下,说明集群启动成功
在window下,配置hostname与ip的对应关系,便于我们的访问
修改"C:\Windows\System32\drivers\etc\hosts"文件,如下
输入http://ljc:50070/dfshealth.jsp,查看namenode、文件系统的状态
使用hadoop自带的WordCount程序来测试运行一下
创建测试文件ljc.txt,在当前目录下已给出
在hdfs上创建buaa目录,如下
将刚刚创建的ljc.txt上传到hdfs中的/buaa目录下,如下
打开http://ljc:8088/cluster/apps,动态查看作业运行情况
单击"RUNNING",发现没有正在运行的程序
输入"bin/hadoop -jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /buaa/ljc.txt /buaa/wordcount-out",运行wordcount程序,如下所示
单击"RUNNING",查看作业运行状态
运行完成,单击"FINSHED",如下
输入http://ljc:50070/dfshealth.jsp,查看运行结果
单击"Browse the filesystem",打开如下界面
单击"buaa",打开如下界面
单击"wordcount-out",打开如下界面
单击"part-r-00000",打开如下界面
和我们从ljc.txt文件看出来的结果是一致的
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【刘超★ljc】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

相关文章推荐
- 在linux中使用sar调优系统性能
- centos 常用命令
- DOCKER源码分析(一):DOCKER架构
- hadoop mapreduce核心功能描述
- NopCommerce架构分析之(四)基于路由实现灵活的插件机制
- OpenCV 函数学习笔记
- linux loop device介绍
- 让boost property_tree支持中文路径
- 使用PipWork解决docker 网络连接问题
- 检测通过什么平台打开网站
- 如何在Linux上安装服务器管理软件Cockpit
- nginx 中的ctx什么意思
- Docker问题(Get http:///var/run/docker.sock/v1.20/version:dial unix /var/run/docker.sock: no such file)
- linux修改硬盘已挂载目录
- Tomcat与jdk在Linux上的安装与配置
- Docker常用命令
- Apache开发模块
- [POJ 2391]Ombrophobic Bovines[最大流][二分答案]
- linux第七章笔记
- mac 配置hadoop 2.6(单机和伪分布式)