hadoop 学习自定义排序
2016-04-04 17:10
453 查看
自定义排序,是基于k2的排序,设现有以下一组数据,分别表示矩形的长和宽,先按照面积的升序进行排序。
现在需要重新定义数据类型,MR的key值必须继承WritableComparable接口,因此定义RectangleWritable数据类型如下:
其中,compareTo方法自定义排序规则,然后由框架进行排序。
map函数和Reduce函数并无大变化,还是按照WrodCount的思路进行,具体代码如下:
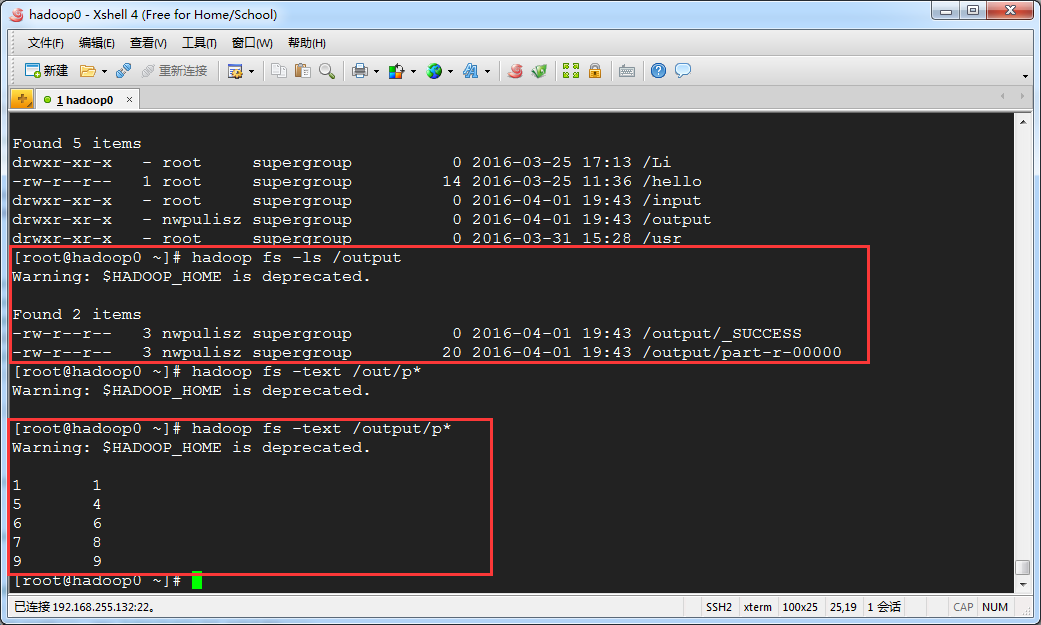
根据自定义结果,输出结果如下:
来自为知笔记(Wiz)
9 9 6 6 7 8 1 1 5 4
现在需要重新定义数据类型,MR的key值必须继承WritableComparable接口,因此定义RectangleWritable数据类型如下:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class RectangleWritable implements WritableComparable {
int length,width;
public RectangleWritable() {
super();
// TODO Auto-generated constructor stub
}
public RectangleWritable(int length, int width) {
super();
this.length = length;
this.width = width;
}
public int getLength() {
return length;
}
public void setLength(int length) {
this.length = length;
}
public int getWidth() {
return width;
}
public void setWidth(int width) {
this.width = width;
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(length);
out.writeInt(width);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.length=in.readInt();
this.width=in.readInt();
}
@Override
public int compareTo(Object arg0) {
// TODO Auto-generated method stub
RectangleWritable other = (RectangleWritable)arg0;
if (this.getLength() * this.getWidth() > other.length * other.width ) {
return 1;
}
if (this.getLength() * this.getWidth() < other.length * other.width ) {
return -1;
}
return 0;
}
@Override
public String toString() {
return this.getLength() + "\t" + this.getWidth();
}
}其中,compareTo方法自定义排序规则,然后由框架进行排序。
map函数和Reduce函数并无大变化,还是按照WrodCount的思路进行,具体代码如下:
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
public class SelfDefineSort {
/**
* @param args
* @author nwpulisz
* @date 2016.4.1
*/
static final String INPUT_PATH="hdfs://192.168.255.132:9000/input";
static final String OUTPUT_PATH="hdfs://192.168.255.132:9000/output";
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Path outPut_path= new Path(OUTPUT_PATH);
Job job = new Job(conf, "SelfDefineSort");
//如果输出路径是存在的,则提前删除输出路径
FileSystem fileSystem = FileSystem.get(new URI(OUTPUT_PATH), conf);
if(fileSystem.exists(outPut_path))
{
fileSystem.delete(outPut_path,true);
}
job.setJarByClass(RectangleWritable.class);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, outPut_path);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(RectangleWritable.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, RectangleWritable, NullWritable>{
protected void map(LongWritable k1, Text v1,
Context context) throws IOException, InterruptedException {
String[] splits = v1.toString().split("\t");
RectangleWritable k2 = new RectangleWritable(Integer.parseInt(splits[0]),
Integer.parseInt(splits[1]));
context.write(k2,NullWritable.get());
}
}
static class MyReducer extends Reducer<RectangleWritable, NullWritable,
IntWritable, IntWritable>{
protected void reduce(RectangleWritable k2,
Iterable<NullWritable> v2s,
Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
context.write(new IntWritable(k2.getLength()), new IntWritable(k2.getWidth()));
}
}
}根据自定义结果,输出结果如下:
来自为知笔记(Wiz)

相关文章推荐
- Linux内核转发技术
- CentOS6.5 ping: unknown host 解决方法
- -bash: rz: command not found
- nginx精准匹配, 一般匹配, 正则匹配
- Linux USB 驱动开发(五)—— USB驱动程序开发过程简单总结
- linux下查看主板内存槽与内存信息
- CopyOnWriteArrayList与Collections.synchronizedList的性能对比
- nginx重试机制-重新发起请求导致的问题
- OpenCV HOG
- Linux特殊权限之s、t、i、a
- CentOS正确关机方法
- Linux进程管理之“四大名捕”
- shell 中的for、while循环及if语句
- linux spi驱动
- nginx日志管理
- linux 仿windows pause指令
- nginx虚拟主机配置
- Linux上ln命令详细说明及软链接和硬链接的区别
- php5,Apache在windows 7环境搭建
- opencv 初学者常见问题