Crawler4j总结(2)
2016-04-02 14:26
225 查看
寻找crawler4j的遍历规则是(深度遍历还是广度遍历)?:
1.crawler4j主要要重写两个类controller和WebCrawler
设计思路是controller–>start–>thread–>Crawler(controller启动thread传递给Crawler4j);
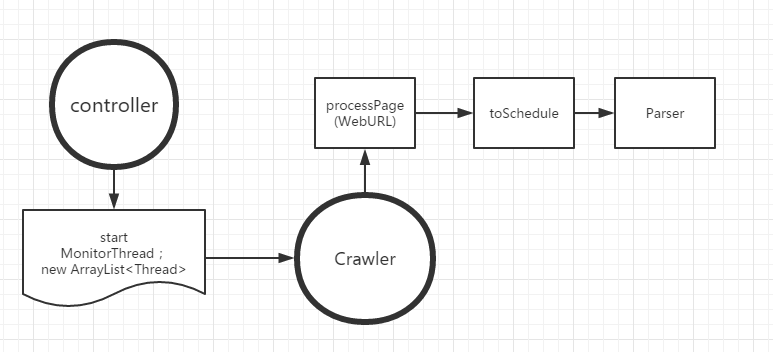
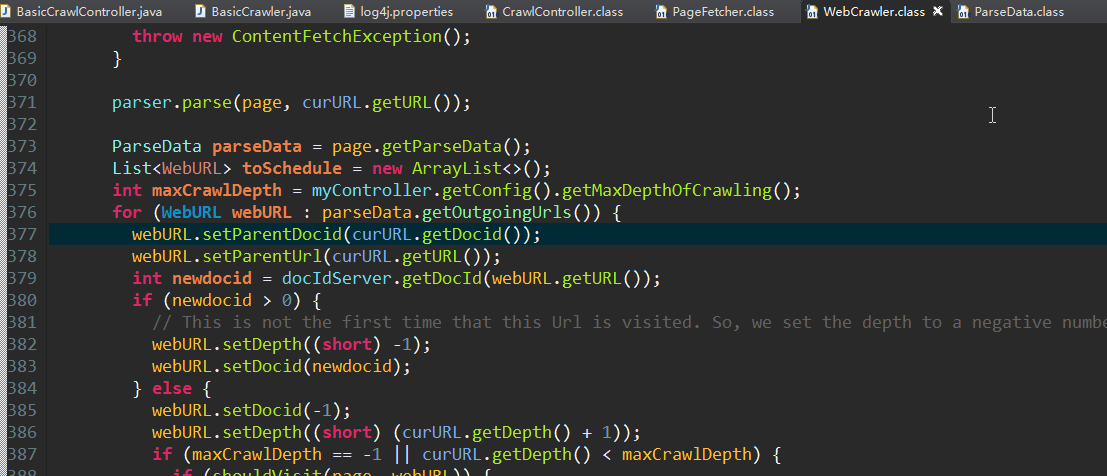
2.Crawler中包含processPage(WebUrl webUrl)这个方法;
将WebUrl中的outgoingUrl放到toschedule中。代码如图所示:
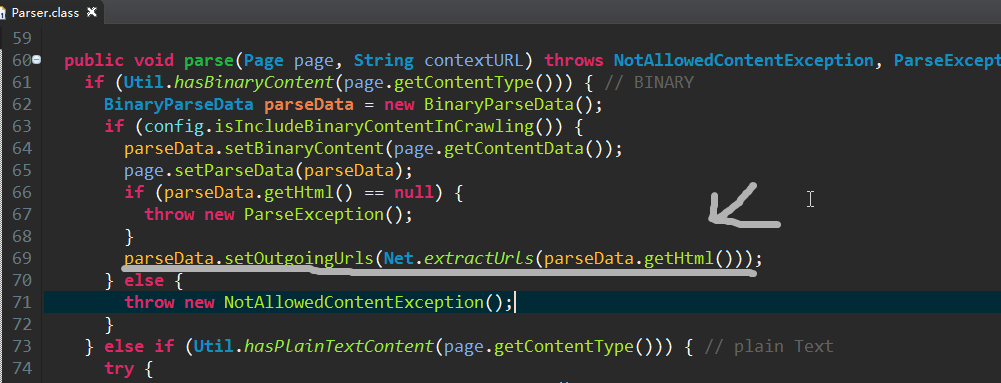
3.在parser.class中有个抽取url的方法
1.crawler4j主要要重写两个类controller和WebCrawler
设计思路是controller–>start–>thread–>Crawler(controller启动thread传递给Crawler4j);
2.Crawler中包含processPage(WebUrl webUrl)这个方法;
将WebUrl中的outgoingUrl放到toschedule中。代码如图所示:
3.在parser.class中有个抽取url的方法

相关文章推荐
- crawler4j抓取页面使用jsoup解析html时的解决方法
- 使用Crawler4j总结
- crawler4j打包与配置
- Crawler4j学习笔记-util
- 基于Crawler4j + jsoup实现爬虫
- crawler4j源码分析(五)Robots协议
- crawler4j配置
- 开源JAVA爬虫crawler4j源码分析
- Crawler4j快速入门实例
- crawler4j_01_authentication
- crawler4j_01_parser_ParseData,Parser
- crawler4j_01_parser_WebURL、FetcherResult、Page和ParseData
- Eclipse上crawler4j环境配置
- 详细教程 :crawler4j 爬取京东商品信息 Java爬虫入门 crawler4j教程
- JVM中的Stack和Heap
- static 用法
- apache flink 入门
- react-组件生命周期
- 可视化的数据结构 - 各种算法动画演示
- note(持续更新中)