ThreadPoolExecutor运行机制
2016-04-01 15:45
183 查看
最近发现几起对ThreadPoolExecutor的误用,其中包括自己,发现都是因为没有仔细看注释和内部运转机制,想当然的揣测参数导致,先看一下新建一个ThreadPoolExecutor的构建参数:
[java] view
plain copy
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
看这个参数很容易让人以为是线程池里保持corePoolSize个线程,如果不够用,就加线程入池直至maximumPoolSize大小,如果还不够就往workQueue里加,如果workQueue也不够就用RejectedExecutionHandler来做拒绝处理。
但实际情况不是这样,具体流程如下:
1)当池子大小小于corePoolSize就新建线程,并处理请求
2)当池子大小等于corePoolSize,把请求放入workQueue中,池子里的空闲线程就去从workQueue中取任务并处理
3)当workQueue放不下新入的任务时,新建线程入池,并处理请求,如果池子大小撑到了maximumPoolSize就用RejectedExecutionHandler来做拒绝处理
4)另外,当池子的线程数大于corePoolSize的时候,多余的线程会等待keepAliveTime长的时间,如果无请求可处理就自行销毁
内部结构如下所示:
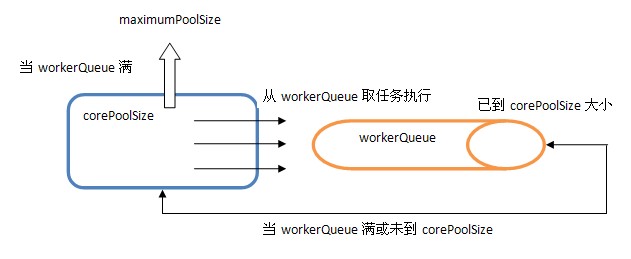
从中可以发现ThreadPoolExecutor就是依靠BlockingQueue的阻塞机制来维持线程池,当池子里的线程无事可干的时候就通过workQueue.take()阻塞住。
其实可以通过Executes来学学几种特殊的ThreadPoolExecutor是如何构建的。
[java] view
plain copy
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newFixedThreadPool就是一个固定大小的ThreadPool
[java] view
plain copy
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newCachedThreadPool比较适合没有固定大小并且比较快速就能完成的小任务,没必要维持一个Pool,这比直接new Thread来处理的好处是能在60秒内重用已创建的线程。
其他类型的ThreadPool看看构建参数再结合上面所说的特性就大致知道它的特性
[java] view
plain copy
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
看这个参数很容易让人以为是线程池里保持corePoolSize个线程,如果不够用,就加线程入池直至maximumPoolSize大小,如果还不够就往workQueue里加,如果workQueue也不够就用RejectedExecutionHandler来做拒绝处理。
但实际情况不是这样,具体流程如下:
1)当池子大小小于corePoolSize就新建线程,并处理请求
2)当池子大小等于corePoolSize,把请求放入workQueue中,池子里的空闲线程就去从workQueue中取任务并处理
3)当workQueue放不下新入的任务时,新建线程入池,并处理请求,如果池子大小撑到了maximumPoolSize就用RejectedExecutionHandler来做拒绝处理
4)另外,当池子的线程数大于corePoolSize的时候,多余的线程会等待keepAliveTime长的时间,如果无请求可处理就自行销毁
内部结构如下所示:
从中可以发现ThreadPoolExecutor就是依靠BlockingQueue的阻塞机制来维持线程池,当池子里的线程无事可干的时候就通过workQueue.take()阻塞住。
其实可以通过Executes来学学几种特殊的ThreadPoolExecutor是如何构建的。
[java] view
plain copy
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newFixedThreadPool就是一个固定大小的ThreadPool
[java] view
plain copy
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newCachedThreadPool比较适合没有固定大小并且比较快速就能完成的小任务,没必要维持一个Pool,这比直接new Thread来处理的好处是能在60秒内重用已创建的线程。
其他类型的ThreadPool看看构建参数再结合上面所说的特性就大致知道它的特性

相关文章推荐
- Qt带进度条的启动界面
- 如何成为一个程序员高手
- 支付宝php支付接口说明
- Java线程池(newCachedThreadPool、newFixedThreadPool、newScheduledThreadPool 、newSingleThreadExector )
- 出现( linker command failed with exit code 1)错误总结
- Cen 4000 tOS 7下载地址(ISO文件)
- 快排QuickSort
- Android启动安装程序
- 转:C++宏中的“#”与“##”用法
- ZOJ1109 Language of FatMouse
- tinycore Network card configuration during exec bootlocal.sh
- sqlserver 分区表
- 深入分析Java的序列化与反序列化
- JavaScript —— JS截取字符串substr 和 substring方法的区别
- zabbix3.0 LNMP安装部署 centos7
- 【HDU】 1022 Train Problem I
- 数据库连接池原理分析
- 自定义View学习之12/7(进度条之混合模式)
- [poj 2528] Mayor's posters 线段树+离散化
- hadoop_2_完全分布式高可用