史上最详细的ConcurrentHashMap详解--源码分析
2016-03-31 19:20
363 查看
ps.本文所有源码都是基于jdk1.6
首先说明一点,ConcurrentHashMap并不是可以完全替换Hashtable的,因为ConcurrentHashMap的get、clear函数是弱一致的(后面会说到),而Hashtable是强一致的。有作者是这么解释的:我们将“一致性强度”和“扩展性”之间的对比交给用户来权衡,所以大多数集合都提供了synchronized和concurrent两个版本。不过真正需要“强一致性”的场景可能非常少,我们大多应用中ConcurrentHashMap是满足的。
可以看到ConcurrentHashMap实际上就是一个Segment数组,那么Segment是什么呢?
那HashEntry又是什么呢?
HashEntry是一个单链表
所以ConcurrentHashMap的数据结构如下图:

这里每一个segment所指向的数据结构,其实就是一个Hashtable,所以说每一个segment都有一把独立的锁,来保证当访问不同的segment时互不影响。
1、段内加锁的:put,putIfAbsent,remove,replace等
2、不加锁的:get,containsKey等
3、整个数据结构加锁的:size,containsValue等
该方法也是在持有段锁的情况下执行的,首先判断是否需要rehash,需要就先rehash,扩容都是针对单个段的,也就是单个段的数据数量大于设定的量的时候会触发扩容。接着是找是否存在同样一个key的结点,如果存在就直接替换这个结点的值。否则创建一个新的结点并添加到hash链的头部,这时一定要修改modCount和count的值,同样修改count的值一定要放在最后一步。put方法调用了rehash方法,reash方法实现得也很精巧,主要利用了table的大小为2^n,和HashMap的扩容基本一样,这里就不介绍了。
还有一个叫putIfAbsent(K key, V value)的函数,这个函数的实现和put几乎一模一样,作用是,如果map中不存在这个key,那么插入这个数据,如果存在这个key,那么不覆盖原来的value,也就是不插入了。
为什么用这么方式删除呢,细心的同学会发现上面定义的HashEntry的key和next都是final类型的,所以不能改变next的指向,所以又复制了一份指向删除的结点的next。
读完上面代码我有一个疑问,就是如果找到的key对应的value是null的话,加锁再读一次,既然上面put操作不允许value是null,那读到的value为什么会有null的情况呢?我们分析一下这种情况,就是put操作和get操作同时进行的时候,可以分为两种情况:
1、put的key已经存在,由于value不是final的,可以直接更新,且value是volatile的,所以修改会立马对get线程可见,而不用等到put方法结束。
2、put的key不存在,那么将在链表表头插入一个数据,那么将new HashEntry赋值给tab[index]是否能立刻对执行get的线程可见呢,我们知道每次put完之后都要更新一个count变量(写),而每次get数据的时候,再最一开始都要读一个count变量(读),而且发现这个count是volatile的,而对同一个volatile变量,有volatile写 happens-before volatile读,所以如果写发生在读之前,那么new HashEntry赋值给tab[index]是对get线程可见的,但是如果写没有发生在读之前,就无法保证new HashEntry赋值给tab[index]要先于get函数的getFirst(hash),也就是说,如果某个Segment实例中的put将一个Entry加入到了table中,在未执行count赋值操作之前有另一个线程执行了同一个Segment实例中的get,来获取这个刚加入的Entry中的value,那么是有可能取不到的,这也就是get的弱一致性。但是什么时候会找到key但是读到的value是null呢,仔细看下put操作的语句:tab[index] = new HashEntry(key, hash, first, value),在这条语句中,HashEntry构造函数中对value的赋值以及对tab[index]的赋值可能被重新排序,举个例子就是这条语句有可能先执行对key赋值,再执行对tab[index]的赋值,最后对value赋值,如果在对tab和key都赋值但是对value还没赋值的情况下的get就是一个空值。
详细可以看看这篇文章:http://ifeve.com/concurrenthashmap-weakly-consistent/
这也就是说无锁的get操作是一个弱一致性的操作。
因为没有全局的锁,在清除完一个segments之后,正在清理下一个segments的时候,已经清理segments可能又被加入了数据,因此clear返回的时候,ConcurrentHashMap中是可能存在数据的。因此,clear方法是弱一致的。
如果我们要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,我们是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是拿到之后可能累加前使用的count发生了变化,那么统计结果就不准了。所以最安全的做法,是在统计size的时候把所有Segment的put,remove和clean方法全部锁住,但是这种做法显然非常低效,因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put , remove和clear方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。size()的实现还有一点需要注意,必须要先segments[i].count,才能segments[i].modCount,这是因为segment[i].count是对volatile变量的访问,接下来segments[i].modCount才能得到几乎最新的值,这里和get方法的方式是一样的,也是一个volatile写 happens-before volatile读的问题。
上面18行代码,抛出了一个问题,就是为什么会再算一遍,上面说只需要比较modCount不变不就可以了么?但是仔细分析,就会发现,在13行14行代码那里,计算完count之后,计算modCount之前有可能count的值又变了,那么18行的代码主要是解决这个问题。
注意上面代码15行处,里面有语句int c = segments[i].count; 但是c却从来没有被使用过,即使如此,编译器也不能做优化将这条语句去掉,因为存在对volatile变量count的读取,这条语句存在的唯一目的就是保证segments[i].modCount读取到几乎最新的值,上面有说道这个问题。
本文章参考文章:
1、http://ifeve.com/concurrenthashmap-weakly-consistent/
2、http://www.iteye.com/topic/344876
首先说明一点,ConcurrentHashMap并不是可以完全替换Hashtable的,因为ConcurrentHashMap的get、clear函数是弱一致的(后面会说到),而Hashtable是强一致的。有作者是这么解释的:我们将“一致性强度”和“扩展性”之间的对比交给用户来权衡,所以大多数集合都提供了synchronized和concurrent两个版本。不过真正需要“强一致性”的场景可能非常少,我们大多应用中ConcurrentHashMap是满足的。
ConcurrentHashMap的数据结构
不得不说,ConcurrentHashMap设计的相当巧妙,它有多个段,每个段下面都是一个Hashtable(相似),所以每个段上都有一把锁(分布式锁),各个段之间的锁互不影响,可以实现并发操作。话不多说,上代码。final Segment<K,V>[] segments;
可以看到ConcurrentHashMap实际上就是一个Segment数组,那么Segment是什么呢?
static final class Segment<K,V> extends ReentrantLock implements Serializable {
...
transient volatile HashEntry<K,V>[] table; //发现Segment实际上是HashEntry数组
...
}那HashEntry又是什么呢?
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
...
}HashEntry是一个单链表
所以ConcurrentHashMap的数据结构如下图:
这里每一个segment所指向的数据结构,其实就是一个Hashtable,所以说每一个segment都有一把独立的锁,来保证当访问不同的segment时互不影响。
ConcurrentHashMap的基础方法
基础方法分为这么几种:1、段内加锁的:put,putIfAbsent,remove,replace等
2、不加锁的:get,containsKey等
3、整个数据结构加锁的:size,containsValue等
构造函数
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException(); //参数合法性校验
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
//比如我输入的concurrencyLevel=12,那么sshift = 4,ssize =16,所以sshift是意思就是1左移了几次比concurrencyLevel大,ssize就是那个大于等于concurrencyLevel的最小2的幂次方的数
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1; //ssize = ssize << 1 , ssize = ssize * 2
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1; //segmentMask的二进制是一个全是1的数
this.segments = Segment.newArray(ssize); //segment个数是ssize,也就是上图黄色方块数,默认16个
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor);//上图浅绿色块的个数是cap,是一个2的幂次方的数,默认是1,也就是每个segment下都构造了cap大小的table数组
}
Segment(int initialCapacity, float lf) {
loadFactor = lf;
setTable(HashEntry.<K,V>newArray(initialCapacity));//构造了一个initialCapacity大小的table
}put函数
public V put(K key, V value) {
if (value == null)
throw new NullPointerException(); //明确指定value不能为null
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false); //segmentFor如下,定位segment下标,然后再put
}
final Segment<K,V> segmentFor(int hash) { //寻找segment的下标
return segments[(hash >>> segmentShift) & segmentMask]; //前面说了segmentMask是一个2进制全是1的数,那么&segmentMask就保证了下标小于等于segmentMask,与HashMap的寻下标相似。
}
//真正的put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); //先加锁,可以看到,put操作是在segment里面加锁的,也就是每个segment都可以加一把锁
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash(); //判断容量,如果不够了就扩容
HashEntry<K,V>[] tab = table; //将table赋给一个局部变量tab,这是因为table是volatile变量,读写volatile变量的开销很大,编译器也不能对volatile变量的读写做任何优化,直接多次访问非volatile实例变量没有多大影响,编译器会做相应优化。
int index = hash & (tab.length - 1); //寻找table的下标
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next; //遍历单链表,找到key相同的为止,如果没找到,e指向链表尾
V oldValue;
if (e != null) { //如果有相同的key,那么直接替换
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else { //否则在链表表头插入新的结点
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}该方法也是在持有段锁的情况下执行的,首先判断是否需要rehash,需要就先rehash,扩容都是针对单个段的,也就是单个段的数据数量大于设定的量的时候会触发扩容。接着是找是否存在同样一个key的结点,如果存在就直接替换这个结点的值。否则创建一个新的结点并添加到hash链的头部,这时一定要修改modCount和count的值,同样修改count的值一定要放在最后一步。put方法调用了rehash方法,reash方法实现得也很精巧,主要利用了table的大小为2^n,和HashMap的扩容基本一样,这里就不介绍了。
还有一个叫putIfAbsent(K key, V value)的函数,这个函数的实现和put几乎一模一样,作用是,如果map中不存在这个key,那么插入这个数据,如果存在这个key,那么不覆盖原来的value,也就是不插入了。
remove函数
>remove操作也交给了段内的remove,如下:
V remove(Object key, int hash, Object value) {
lock(); //段内先获得一把锁
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) { //如果找到该key
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next; //newFirst此时为要删除结点的next
for (HashEntry<K,V> p = first; p != e; p = p.next)
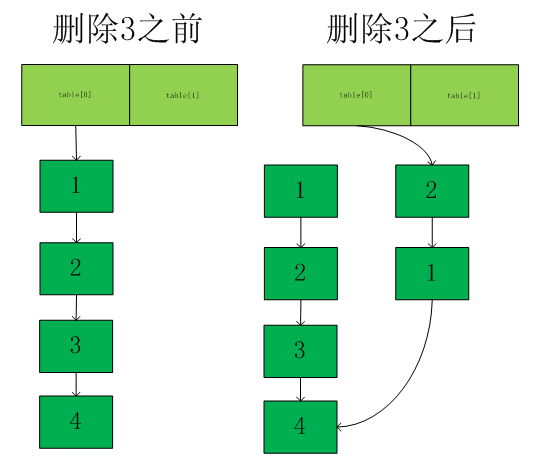
newFirst = new HashEntry<K,V>(p.key,p.hash,newFirst, p.value);//从头遍历链表将要删除结点的前面所有结点复制一份插入到newFirst之前,如下图
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}为什么用这么方式删除呢,细心的同学会发现上面定义的HashEntry的key和next都是final类型的,所以不能改变next的指向,所以又复制了一份指向删除的结点的next。
get函数
public V get(Object key) {
int hash = hash(key.hashCode()); //双hash,和HashMap一样,也是为了更好的离散化
return segmentFor(hash).get(key, hash); //先寻找segment的下标,然后再get
}
final Segment<K,V> segmentFor(int hash) { //寻找segment的下标
return segments[(hash >>> segmentShift) & segmentMask]; //前面说了segmentMask是一个2进制全是1的数,那么&segmentMask就保证了下标小于等于segmentMask,与HashMap的寻下标相似。
}
V get(Object key, int hash) {// count是一个volatile变量,count非常巧妙,每次put和remove之后的最后一步都要更新count,就是为了get的时候不让编译器对代码进行重排序,来保证
if (count != 0) {
HashEntry<K,V> e = getFirst(hash); //寻找table的下标,也就是链表的表头
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck 加锁读,这个加锁读不用重新计算位置,而是直接拿e的值
}
e = e.next;
}
}
return null;
}
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}读完上面代码我有一个疑问,就是如果找到的key对应的value是null的话,加锁再读一次,既然上面put操作不允许value是null,那读到的value为什么会有null的情况呢?我们分析一下这种情况,就是put操作和get操作同时进行的时候,可以分为两种情况:
1、put的key已经存在,由于value不是final的,可以直接更新,且value是volatile的,所以修改会立马对get线程可见,而不用等到put方法结束。
2、put的key不存在,那么将在链表表头插入一个数据,那么将new HashEntry赋值给tab[index]是否能立刻对执行get的线程可见呢,我们知道每次put完之后都要更新一个count变量(写),而每次get数据的时候,再最一开始都要读一个count变量(读),而且发现这个count是volatile的,而对同一个volatile变量,有volatile写 happens-before volatile读,所以如果写发生在读之前,那么new HashEntry赋值给tab[index]是对get线程可见的,但是如果写没有发生在读之前,就无法保证new HashEntry赋值给tab[index]要先于get函数的getFirst(hash),也就是说,如果某个Segment实例中的put将一个Entry加入到了table中,在未执行count赋值操作之前有另一个线程执行了同一个Segment实例中的get,来获取这个刚加入的Entry中的value,那么是有可能取不到的,这也就是get的弱一致性。但是什么时候会找到key但是读到的value是null呢,仔细看下put操作的语句:tab[index] = new HashEntry(key, hash, first, value),在这条语句中,HashEntry构造函数中对value的赋值以及对tab[index]的赋值可能被重新排序,举个例子就是这条语句有可能先执行对key赋值,再执行对tab[index]的赋值,最后对value赋值,如果在对tab和key都赋值但是对value还没赋值的情况下的get就是一个空值。
详细可以看看这篇文章:http://ifeve.com/concurrenthashmap-weakly-consistent/
这也就是说无锁的get操作是一个弱一致性的操作。
clear函数
public void clear() {
for (int i = 0; i < segments.length; ++i) //循环clear掉每个段中的内容
segments[i].clear();
}
void clear() {
if (count != 0) {
lock(); //段内加锁
try {
HashEntry<K,V>[] tab = table;
for (int i = 0; i < tab.length ; i++)
tab[i] = null;
++modCount;
count = 0; // write-volatile
} finally {
unlock();
}
}
}因为没有全局的锁,在清除完一个segments之后,正在清理下一个segments的时候,已经清理segments可能又被加入了数据,因此clear返回的时候,ConcurrentHashMap中是可能存在数据的。因此,clear方法是弱一致的。
size函数
public int size() {
final Segment<K,V>[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count; //循环相加每个段内数据的个数
mcsum += mc[i] = segments[i].modCount; //循环相加每个段内的modCount
}
if (mcsum != 0) { //如果是0,代表根本没有过数据更改,也就是size是0
for (int i = 0; i < segments.length; ++i) {
check += segments[i].count; //再次循环相加每个段内数据的个数,这里为什么会再算一次呢,后面会说
if (mc[i] != segments[i].modCount) {
check = -1; // force retry //如果modCount和之前统计的不一致了,check直接赋值-1,重新再来
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // Resort to locking all segments
sum = 0;
for (int i = 0; i < segments.length; ++i) //循环获取所有segment的锁
segments[i].lock();
for (int i = 0; i < segments.length; ++i) //在持有所有段的锁的时候进行count的相加
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i) //循环释放所有段的锁
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE) //return
return Integer.MAX_VALUE;
else
return (int)sum;
}如果我们要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,我们是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是拿到之后可能累加前使用的count发生了变化,那么统计结果就不准了。所以最安全的做法,是在统计size的时候把所有Segment的put,remove和clean方法全部锁住,但是这种做法显然非常低效,因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put , remove和clear方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。size()的实现还有一点需要注意,必须要先segments[i].count,才能segments[i].modCount,这是因为segment[i].count是对volatile变量的访问,接下来segments[i].modCount才能得到几乎最新的值,这里和get方法的方式是一样的,也是一个volatile写 happens-before volatile读的问题。
上面18行代码,抛出了一个问题,就是为什么会再算一遍,上面说只需要比较modCount不变不就可以了么?但是仔细分析,就会发现,在13行14行代码那里,计算完count之后,计算modCount之前有可能count的值又变了,那么18行的代码主要是解决这个问题。
containsValue函数
containsKey函数比较简单,也是不加锁的简易get,下面说一下containsValue有一个有意思的地方public boolean containsValue(Object value) {
if (value == null)
throw new NullPointerException();
// See explanation of modCount use above
final Segment<K,V>[] segments = this.segments;
int[] mc = new int[segments.length];
// Try a few times without locking
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
int sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
int c = segments[i].count; //注意这行,声明了一个c变量,并且赋值了,但是下面却完全没有用到。
mcsum += mc[i] = segments[i].modCount;
if (segments[i].containsValue(value))
return true;
}
boolean cleanSweep = true; //默认结构没变
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
int c = segments[i].count;
if (mc[i] != segments[i].modCount) { //如果结构变了,cleanSweep = false
cleanSweep = false;
break;
}
}
}
if (cleanSweep) //如果没变,直接返回false
return false;
}
// Resort to locking all segments
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
boolean found = false;
try {
for (int i = 0; i < segments.length; ++i) {
if (segments[i].containsValue(value)) {
found = true;
break;
}
}
} finally {
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
return found;
}注意上面代码15行处,里面有语句int c = segments[i].count; 但是c却从来没有被使用过,即使如此,编译器也不能做优化将这条语句去掉,因为存在对volatile变量count的读取,这条语句存在的唯一目的就是保证segments[i].modCount读取到几乎最新的值,上面有说道这个问题。
本文章参考文章:
1、http://ifeve.com/concurrenthashmap-weakly-consistent/
2、http://www.iteye.com/topic/344876

相关文章推荐
- 从源码安装Mysql/Percona 5.5
- 浅析Ruby的源代码布局及其编程风格
- asp.net 抓取网页源码三种实现方法
- JS小游戏之仙剑翻牌源码详解
- JS小游戏之宇宙战机源码详解
- jQuery源码分析之jQuery中的循环技巧详解
- 本人自用的global.js库源码分享
- java中原码、反码与补码的问题分析
- ASP.NET使用HttpWebRequest读取远程网页源代码
- PHP网页游戏学习之Xnova(ogame)源码解读(六)
- C#获取网页HTML源码实例
- PHP网页游戏学习之Xnova(ogame)源码解读(八)
- PHP网页游戏学习之Xnova(ogame)源码解读(四)
- JS小游戏之极速快跑源码详解
- JS小游戏之象棋暗棋源码详解
- android源码探索之定制android关机界面的方法
- 基于Android设计模式之--SDK源码之策略模式的详解
- Android游戏源码分享之2048
- C语言借助EasyX实现的生命游戏源码
- C实现的非阻塞方式命令行端口扫描器源码