最大间隔多超平面分类器(多线性SVM分类器)介绍及Matlab实现
2016-03-30 10:30
731 查看
一、最大间隔多超平面分类器介绍
最近在做论文复现的工作,论文的名称是“Disentangling Disease Heterogeneity with Max-Margin Multiple Hyperplane Classifier”,其目的是利用最大间隔多超平面分类器对疾病的异质性进行研究。所谓的最大间隔多超平面分类器就是多线性SVM分类器的另一种称呼。而多线性SVM也就是用多个线性SVM的组合来完成对线性不可分的数据集的分类任务。在使用SVM的传统的分类任务中,对于线性不可分的情况,通常会祭出核函数这个大杀器,往往会获得不错的结果。但是在一些情况下核函数并不是很适用。举个例子,比如在负例可以通过聚类分析的方法分成多个子类时,核函数并不能将聚类情况反映出来,而多线性SVM分类器却可以很好的解决这类问题。用论文中的一张图可以表示为: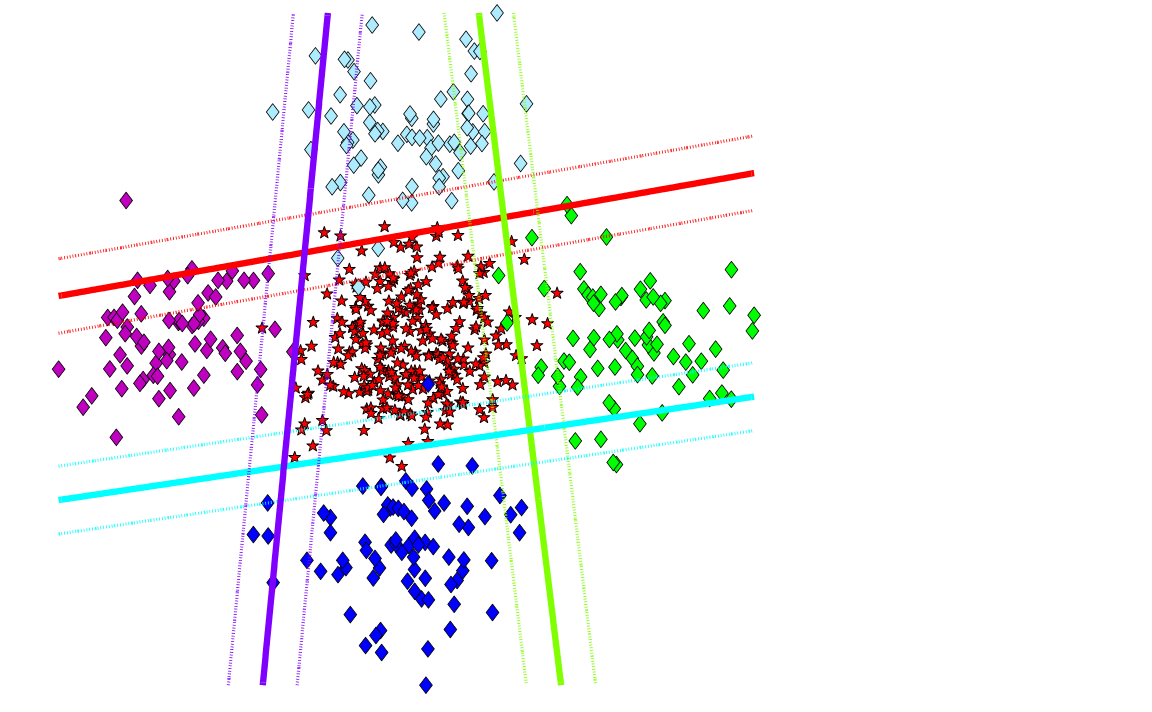
从图片上可以看出来,如果用核函数的话,会在正例外面形成一个圆圈,分类效果无疑很好但是却失去了对负例的聚类作用。当然也会有人说那我用核函数分类结束再使用聚类分析不就可以了吗,但是注意到多线性SVM分类器在分类的同时就可以完成聚类的任务,这在数据维度很高的情况下可以大大节省时间。
二、最大间隔多超平面分类器的实现
注意事项
实现本代码需采用libsvm-weights-3.20工具箱与传统libsvm不同的是,这个工具箱允许在训练过程中给出每个训练样本的权重
下载地址为:http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/weights/
由于最大间隔多超平面分类器的原理并不复杂,有想深入了解的朋友可以在http://link.springer.com/chapter/10.1007%2F978-3-319-24553-9_86下载这篇论文,其算法流程与最基本的线性SVM有相当多的相似之处,所以在此处略去对算法的推导过程。下面将完整给出最大间隔多超平面分类器的Matlab实现,所有的代码都是本人自己编写且调试通过的,有需要的同学可以放心的用:
Run_Max_Margin.m
% 最大间隔多超平面分类器主函数 乔锐
% 输入数据:m*n数据矩阵X,m维类标签向量y(+1,-1),惩罚参数C,超平面个数K
% 输出数据:d*K权重矩阵W(分类器),n-*K维聚类矩阵S-
clear, clc;
addpath(genpath('.'));
%%% *************************************************
%%% ************* Step 0: load data *****************
display('Step 0: load data');
%load('trainX.mat');
%load('trainY.mat');
load('training.mat');
[X] = Znormalized(data); % 对数据进行归一化操作
[~,n] = size(X); % 数据的维度
%%% ******************************************************
%%% ************* Step 1: initialization *****************
C = 1; % 惩罚参数C
K = 4; % 超平面个数K
N = 4; % 训练所需要的循环次数,保证收敛性
nn = sum(y == -1); % negative n 负例个数
pn = sum(y == 1); % positive n 正例个数
S = zeros(nn,K); % 聚类矩阵S-
W = zeros(n,K); % 存储K个分类器的权重向量的权重矩阵
B = zeros(K,1); % 存储K个分类器的K个偏置
for i = 1:nn % 对聚类矩阵S-进行随机初始化,保证每一行不出现全0的情况
S(i,:) = randi([0,1],1,K);
if sum(S(i,:)==1)==0
while 1==1
S(i,:) = randi([0,1],1,K);
if sum(S(i,:)==1)~=0
break;
end
end
end
end
%%% **************************************************
%%% ************* Step 2: start training *************
display('Step 2: start training...');
tic;
for i = 1:N % N次循环保证收敛性
[c] = wupdate(y,S,C,K); % weightedSVM权重更新
for j = 1:K
model = svmtrain(c(:,j), y, X, '-t 0');
[w,b] = calweight(model,n);
W(:,j) = w;
B(j) = b;
end
[S] = Supdate(S,W,B,X,y,K); % 对聚类矩阵S-进行更新
end
trainTime = toc;
%%% *************************************************
%%% ************* Step 3: start testing *************
display('Step 3: start testing...');
%load('testX.mat');
%load('testY.mat');
load('testing.mat');
[testX] = Znormalized(testdata); % 对数据进行归一化操作
[m,n] = size(testX);
predicty = zeros(m,1);
for i =1:m
result = zeros(K,1);
for j =1:K
result(j) = testX(i,:) * W(:,j) + B(j);
end
if min(result) >= 0
predicty(i) = 1;
else
predicty(i) = -1;
end
end
err = numel(find(testy ~= predicty)) / m;
%%% *************************************************
%%% ************ Step 4: show the result ************
display('Step 4: show the result...');
disp(['Training Took ' num2str(trainTime) ' seconds']);
disp(['The accuracy rate is: ' num2str(100 - 100 * err) '%']);
%% write file
fid = fopen('result.txt', 'a+');
fprintf(fid, 'acc = %0.3f%%, Training time: %d\n', 100 - 100 * err, trainTime);
fclose(fid);% z-normalized function % 对输入数据集进行z归一化操作,经过处理的数据满足标准正态分布,均值为0,标准差为1 % 输入矩阵大小为m*n,其中m代表样本个数,n代表特征维度 % 归一化操作针对所有样本的相应维度的特征,例如:所有样本的第一维度的特征 data(:,1) function [X] = Znormalized(data) [m,n] = size(data); means = zeros(n,1); stds = zeros(n,1); for i = 1:n means(i) = mean(data(:,i)); stds(i) = std(data(:,i)); for j = 1:m data(j,i) = (data(j,i) - means(i))/stds(i); end end X = data;
% weightedSVM权重更新函数 乔锐 % 输入数据:m维类标签向量y(+1,-1),聚类矩阵S,惩罚参数C,超平面个数K % 输出数据:m*K权重矩阵w function [w] = wupdate(y,S,C,K) m = size(y,1); w = ones(m,K); % 用于weightedSVM的权重矩阵 num = 1; % 聚类矩阵S-的行向量索引 for i =1:m % 对权重矩阵进行赋值 if y(i) == 1 w(i,:) = C/K; else w(i,:) = C*S(num,:); num = num + 1; end end
% 聚类矩阵S-更新函数 乔锐 % 输入: 原聚类矩阵S,存储K个分类器的权重向量的权重矩阵W 存储K个分类器的K个偏置的偏置向量B,数据矩阵X,类标签向量y,超平面个数K function [S] = Supdate(S,W,B,X,y,K) index = y == -1; % 找出负例的位置索引 newX = X(index,:); % 完全由负例构成的数据集newX [m,~] = size(newX); % 获得新数据集的样本数m和数据维度n for i = 1:m sumK = 0; for l = 1:K if (newX(i,:)*W(:,l) + B(l)) <= -1 sumK = sumK + 1 + newX(i,:)*W(:,l) + B(l); end end for j = 1:K if (newX(i,:)*W(:,j) + B(j)) > -1 S(i,j) = 0; else S(i,j) = (1 + newX(i,:)*W(:,j) + B(j)) / sumK; end end end
% libsvm分类器权重和偏置计算函数(线性核) 乔锐 % 输入:weightedSVM输出模型model,样本特征维度n function [w,b] = calweight(model,n) b = -model.rho; SV = full(model.SVs); coef = model.sv_coef; w = zeros(n,1); for i = 1:n w(i) = sum(coef.*SV(:,i)); end

相关文章推荐
- matlab集合经验模态分解EEMD工具包
- 模糊聚类FCM的MATLAB实现
- VS 调用 Matlab (混合编程)
- 傅立叶变换-MATLAB
- matlab 查看电脑系统性能(CPU,GPU),并开启并行运算
- Matlab调用C语言编写MEX文件
- matlab学习笔记
- 将MATLAB的变量数据导入到C/C++程序中的方法!
- matlab图像处理
- ubuntu15.04下Matlab R2012a的安装和GCC4.6配置
- MATLAB中MEX文件的编写与调试
- MATLAB中fopen、fprintf函数的用法
- MATLAB的一些基础知识
- MatLab 代码优化 Fast your MatLab code. (2) 寻找性能瓶颈
- Matlab---图像滤波之各种滤波器汇总实现
- Matlab编程实例(4) 相位角与相关系数曲线
- Matlab编程实例(3) 函数向左或向右平移N点 左移右移
- Matlab编程实例(2) 同期平均
- Matlab编程实例(1) 移动平均
- matlab 学习