如何理解过拟合、正则化和交叉验证
2016-03-28 10:39
459 查看
机器学习中大家经常会遇到过拟合问题,过拟合就是模型在训练集模型表现良好,但是在测试集就不行了。具体表现在训练集为追求好的效果(经验损失小,准确率高等),模型建立的过于复杂(下图3),能够很好反映已知数据,但泛化能力太差。学术点说就是empirical loss比较小,而Generalized loss比较大。
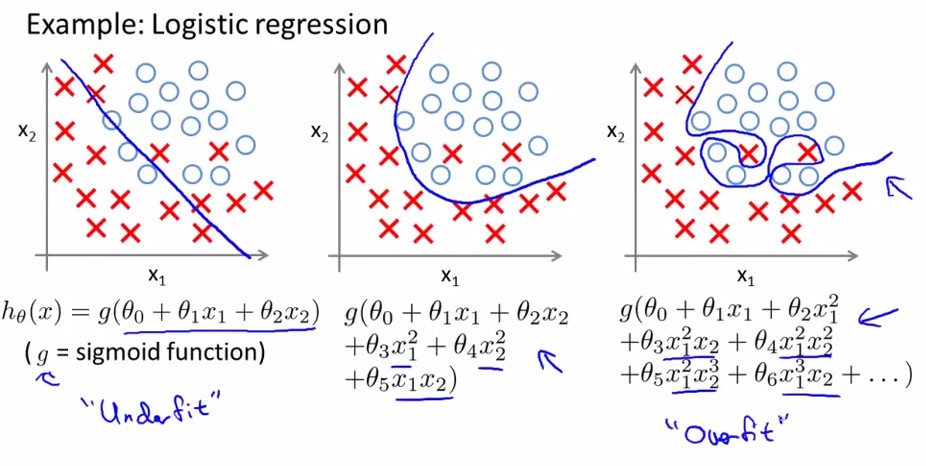
通常数据师在建模型时,基本都在遵循简化原则,即在拟合效果差不多的情况下,模型越简单则在测试集表现的越优(奥卡姆剃刀原理),这也就解释了决策树要“剪枝”的原因。但对于某些复杂问题,我们的模型相应的也会变得复杂,为解决因此带来的过拟合问题,我们采用交叉验证和正则化来解决。
交叉验证:(Cross Validation)
在验证模型时,我们会将训练集分为两部分,子训练集和测试集,线下验证模型优劣。通常采用7:3的划分方法,但大家都知道不同的划分策略,模型的准确性验证会不同。所以为解决因人工划分带来的随机性问题,选择交叉验证(CV),即不断的划分训练集(比例上子训练集大于测试集),反复测试,从有限的数据中尽可能获得多的有效信息,返回模型准确率的均值。通过交叉验证,如果模型的表现仍然很好,就认为该模型泛化能力也不差。
交叉验证目的:选出最优参数的模型。模型建立后,调参数是个很费时的过程,通过交叉验证我们可以得出最优参数的模型。
1.1 准备候选模型,M1,M2,M3,……(模型框架一致,只是参数不同)
1.2 对于每个模型,分别进行交叉验证,返回该模型的准确率或者错误率等信息(自己选择是计算accuracy还是error),其返回应该是交叉验证后得出的均值。
1.3 通过比较不同模型的accuracy或error,选择最佳模型。
交叉验证分类:留P验证(Leave-p-out Cross Validation)、k-fold交叉验证(K-fold Cross Validation)等。
2.1 留p验证(LpO CV)是指训练集上随机选择p个样本作为测试集,其余作为子训练集。时间复杂度为CpN,是阶乘的复杂度,不可取。
2.2 k-fold交叉验证就是将数据集平均分割成k份,依次选择一份作为测试集,其余作为子训练集,最后将得到的k个accuracy取平均。通常K取10,也就是经常听到的10折交叉验证。
正则化:
先给出知乎上一乎友的见解:
(https://www.zhihu.com/question/20700829/answer/21156998)
通俗解释:让模型参数不要在优化的方向上纵欲过度。
《红楼梦》里,贾瑞喜欢王熙凤得了相思病,病榻中得到一枚风月宝鉴,可以进入和心目中的女神XXOO,它脑子里的模型目标函数就是“最大化的爽”,所以他就反复去拟合这个目标,多次XXOO,于是人挂掉了,如果给他加一个正则化,让它爽,又要控制爽的频率,那么他可以爽得更久。
再补充一个角度:
正则化其实就是对模型的参数设定一个先验,这是贝叶斯学派的观点,不过我觉得也可以一种理解。
L1正则是laplace先验,l2是高斯先验,分别由参数sigma确定。
求不要追究sigma是不是也有先验,那一路追究下去可以天荒地老。

相关文章推荐
- An overview of gradient descent optimization algorithms
- oracle新增修改表字段+注释
- C语言之指针 到现在还是很模糊 ->
- ph56w 升级 php70w 一些 错误
- java 的hash,list , equal()复习
- Spring AOP的使用 基于XML
- algrothm_java命名
- 新浪分享 Insufficient app permissions!
- 富人和穷人你怎么看
- Cocos2d-x 3.2 打包Android平台APK
- linux 下计划任务的作法
- 【java】对数据库操作的那些事(包括数据库中的预处理)
- WEB安全:XSS漏洞与SQL注入漏洞介绍及解决方案(转)
- 直接插入排序
- 设计模式(九)装饰者模式(Decorator Pattern)
- 转载-STM32片上FLASH内存映射、页面大小、寄存器映射
- JDBC第三次学习
- 物理层
- POJ 3050 Hopscotch
- Cygwin下VI命令使用-修改文件