Java中的Map
2016-03-24 23:03
555 查看
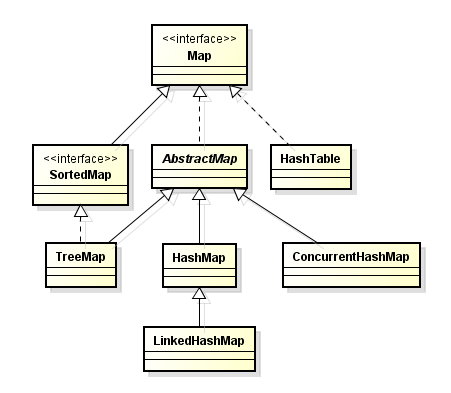
本文将讨论Java中的HashMap、LinkedHashMap、HashTable、ConcurrentHashMap。
由put方法可知,
1. HashMap支持null Key和null Value
2. HashMap线程不安全
创建一个新的HashMapEntry,next指向当前的table[index],即插入链表头。
LinkedHashMap重写了HashMap的addEntry和createEntry方法,在创建节点的同时,要将新的节点插入链表尾。
Android中的android.util.LruCache类使用了LinkedHashMap,并将accessOrder设为了true。这样就实现了LRU(Least Recent Used),当cache命中时,将对应节点移到链表尾,当cache容量满了之后,可以删除链表头节点。
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如果线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且不能使用get方法来获取元素,所以竞争越激烈效率越低。
如果一个对象有多个synchronized方法,某一时刻某个线程已经进入到了某个synchronized方法,那么在该方法没有执行完毕前,其他线程是无法访问该对象的任何synchronized方法的。
synchronized实例方法是给对象上锁,如果是不同的对象,则各个对象之间没有限制关系。
synchronized类方法是给Class对象上锁
ConcurrentHashMap使用了分段锁
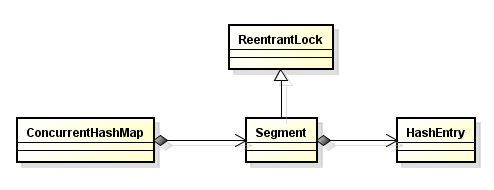
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。
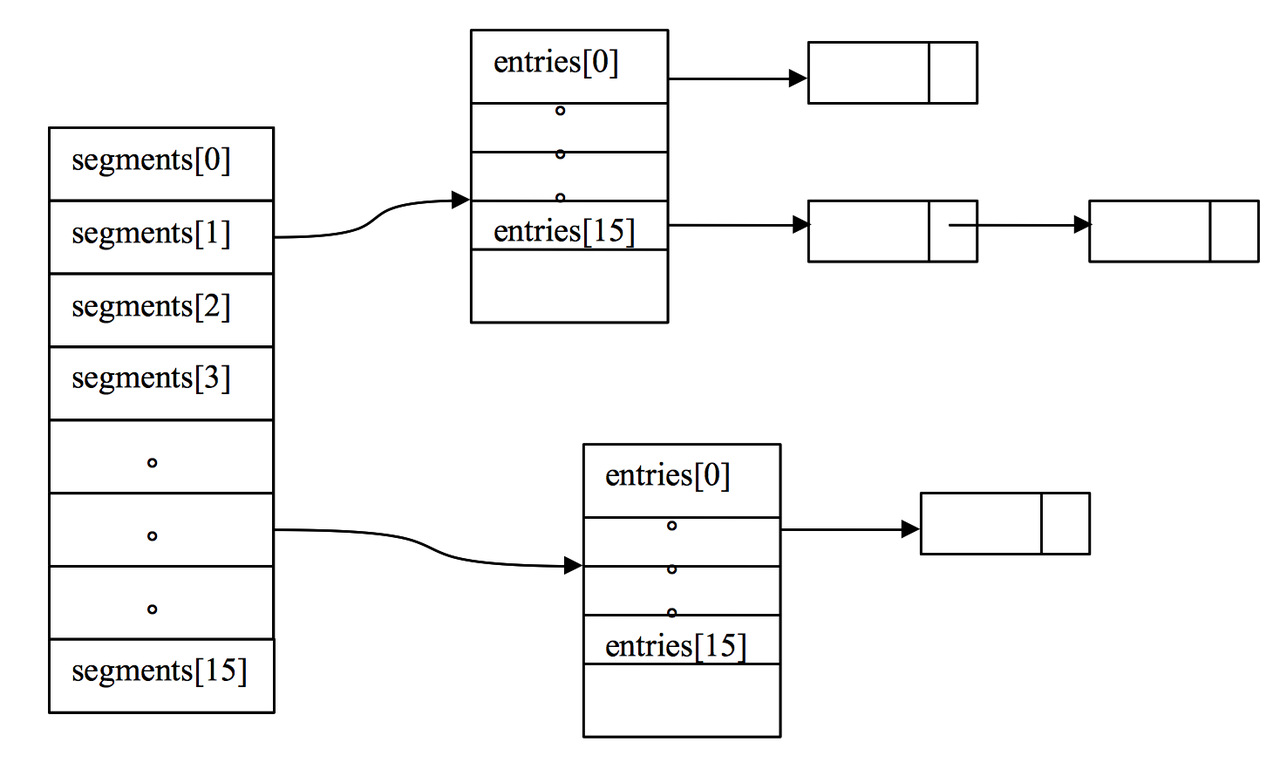
ConcurrentHashMap 在默认并发级别会创建包含 16 个 Segment 对象的数组。每个 Segment 的成员对象 table 包含若干个散列表的桶。每个桶是由 HashEntry 链接起来的一个链表。如果键能均匀散列,每个 Segment 大约守护整个散列表中桶总数的 1/16。
在 ConcurrentHashMap 中,线程对映射表做读操作时,一般情况下不需要加锁就可以完成,对容器做结构性修改的操作才需要加锁。
ConcurrentHashMap不支持null Key。
1. HashMap
HashMap采用链接法解决碰撞。静态内部类Entry中有一个next引用指向下一个hash值相同的节点,所以table的每一个元素指向一个hash值相同的链表。transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next; // 指向下一个hash值相同的节点
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
...
}由put方法可知,
1. HashMap支持null Key和null Value
2. HashMap线程不安全
@Override
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}创建一个新的HashMapEntry,next指向当前的table[index],即插入链表头。
void addEntry(K key, V value, int hash, int index) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}2. LinkedHashMap
HashMap的迭代顺序是不确定的,而LinkedHashMap实现了按插入顺序或按访问顺序迭代。LinkedHashMap继承于HashMap,其中静态内部类Entry继承于HashMap.Entry,添加了before和after两个引用,在哈希表的基础上又构成了双向循环链表结构。若accessOrder == true,即按照访问顺序迭代,则需在访问某个节点后将其移到链表尾,具体分析Entry的recordAccess()方法。/**
* 双向链表的头节点.
*/
private transient Entry<K,V> header;
/**
* 迭代顺序
* true : 访问顺序
* false : 插入顺序
*/
private final boolean accessOrder;
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
/**
* LinkedHashMap entry.
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after; // 当前节点的前节点和后节点
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
/**
* Removes this entry from the linked list.
*/
private void remove() {
before.after = after;
after.before = before;
}
/**
* Inserts this entry before the specified existing entry in the list.
*/
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
/**
* This method is invoked by the superclass whenever the value
* of a pre-existing entry is read by Map.get or modified by Map.set.
* If the enclosing Map is access-ordered, it moves the entry
* to the end of the list; otherwise, it does nothing.
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
// 若按照访问顺序迭代,则要将当前节点移到链表尾
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}LinkedHashMap重写了HashMap的addEntry和createEntry方法,在创建节点的同时,要将新的节点插入链表尾。
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 新创建的节点插入链表尾
e.addBefore(header);
size++;
}Android中的android.util.LruCache类使用了LinkedHashMap,并将accessOrder设为了true。这样就实现了LRU(Least Recent Used),当cache命中时,将对应节点移到链表尾,当cache容量满了之后,可以删除链表头节点。
3. Hashtable
由put方法可见,Hashtable与HashMap实现方式类似,都用了链接法解决冲突。同时给方法添加syncrhonized关键字实现线程安全。public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如果线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且不能使用get方法来获取元素,所以竞争越激烈效率越低。
如果一个对象有多个synchronized方法,某一时刻某个线程已经进入到了某个synchronized方法,那么在该方法没有执行完毕前,其他线程是无法访问该对象的任何synchronized方法的。
synchronized实例方法是给对象上锁,如果是不同的对象,则各个对象之间没有限制关系。
synchronized类方法是给Class对象上锁
4. ConcurrentHashMap
java.util.concurrent.ConcurrentHashMapConcurrentHashMap使用了分段锁
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。
ConcurrentHashMap 在默认并发级别会创建包含 16 个 Segment 对象的数组。每个 Segment 的成员对象 table 包含若干个散列表的桶。每个桶是由 HashEntry 链接起来的一个链表。如果键能均匀散列,每个 Segment 大约守护整个散列表中桶总数的 1/16。
在 ConcurrentHashMap 中,线程对映射表做读操作时,一般情况下不需要加锁就可以完成,对容器做结构性修改的操作才需要加锁。
ConcurrentHashMap不支持null Key。
参考资料
探索 ConcurrentHashMap 高并发性的实现机制
相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- android Google Map获取地理位置信息的方法
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- Spark RDD API详解(一) Map和Reduce
- PropertyChangeListener简单理解
- Python中map()函数浅析
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序