Kafka and Samza: Real-time stream processing
2016-03-23 11:00
363 查看
As we known, for big data analysis, we have those two already learned[1]:
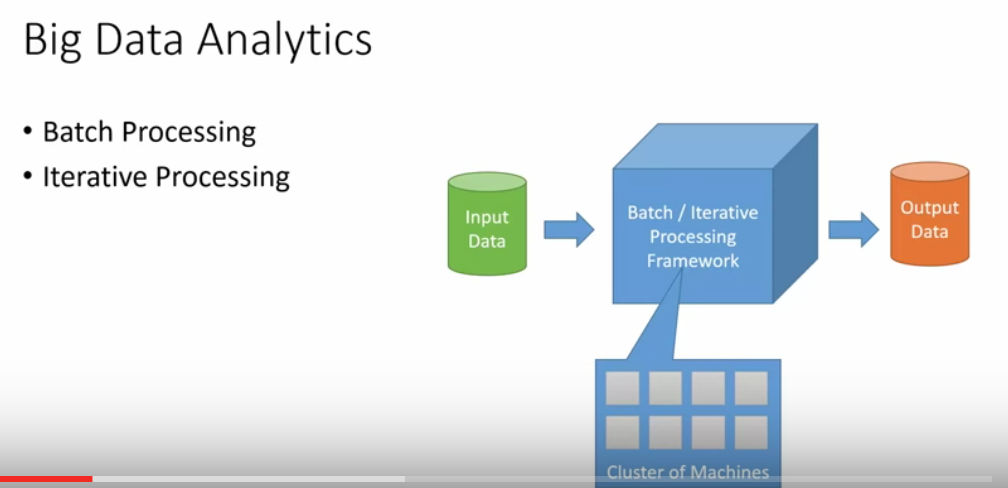
Batch Processing is map-reduce. And Iterative Processing is Spark. These two have one thing in common which is what they are processing is a fixed data. Once the processing job starts, you cannot change the input data at all. This gives some disadvantage
for real time data analysis.
Now, for real time analysis, we introduce stream processing. Here is a concept of stream processing[1]:
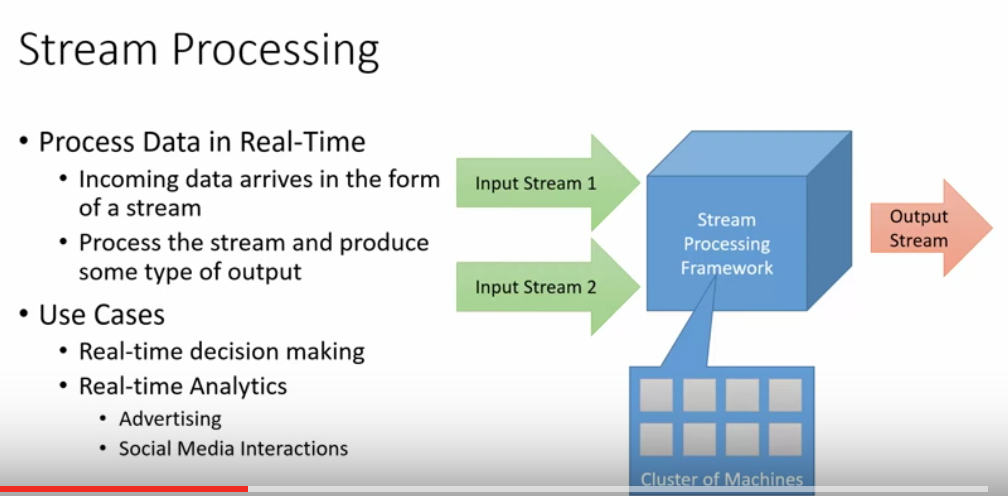
In our situation of Kafka + Samza, Samza is the processing framework. Kafka only is a source of organising stream as topics and messages. Now, let's take a look of the details.
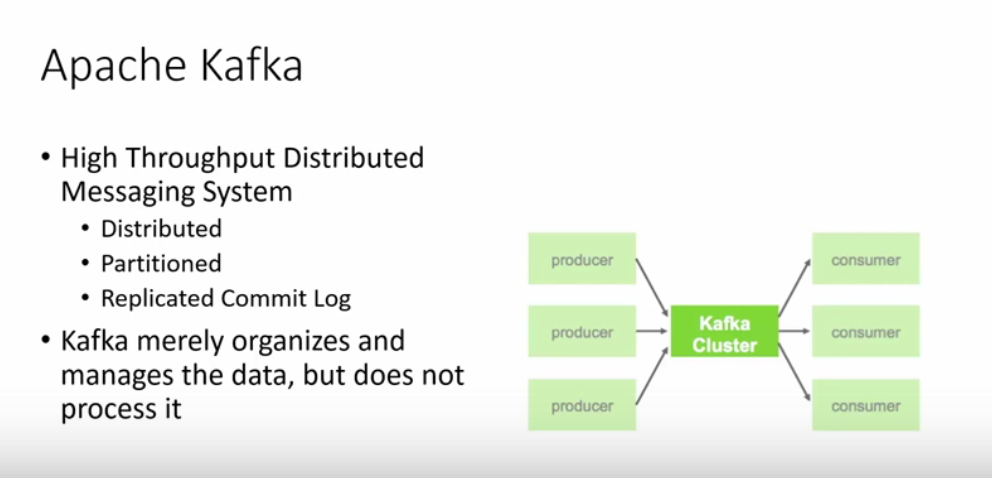
Here is some concepts in Kafka:
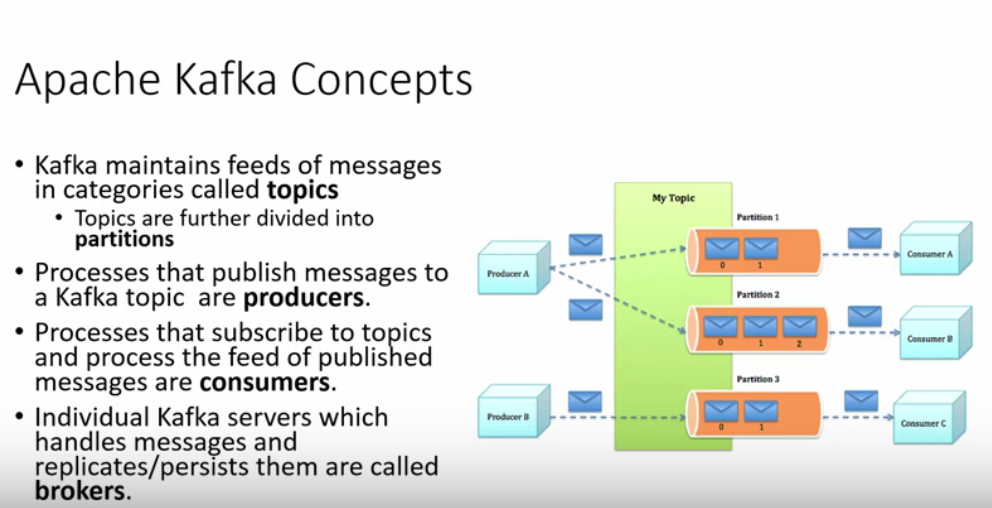
Here are some basic concepts about Samza:
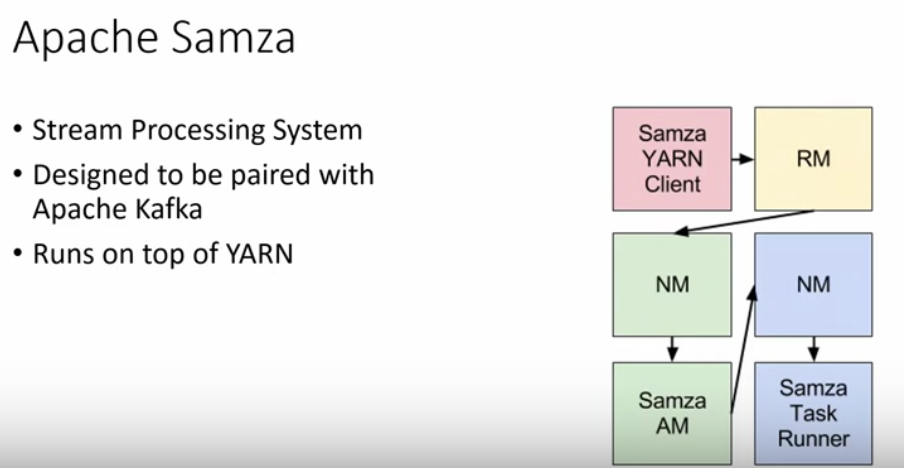
NM = Node Manager; RM = Resource Manager.
Here is a typical job of Samza:
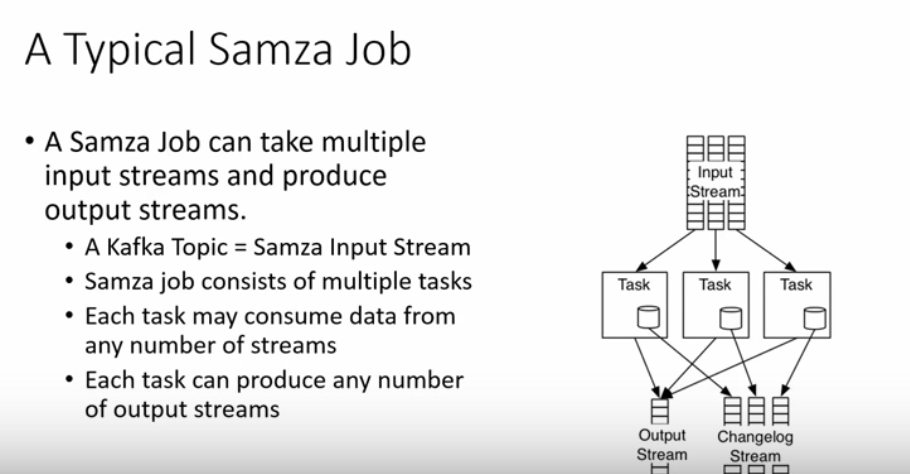
In general, one task in Samza is one consumer in Kafka. One stream in the input streams is one partition of topic in kafka.
Reference:
[1] 15619 Cloud Computing CMU
Batch Processing is map-reduce. And Iterative Processing is Spark. These two have one thing in common which is what they are processing is a fixed data. Once the processing job starts, you cannot change the input data at all. This gives some disadvantage
for real time data analysis.
Now, for real time analysis, we introduce stream processing. Here is a concept of stream processing[1]:
In our situation of Kafka + Samza, Samza is the processing framework. Kafka only is a source of organising stream as topics and messages. Now, let's take a look of the details.
Here is some concepts in Kafka:
Here are some basic concepts about Samza:
NM = Node Manager; RM = Resource Manager.
Here is a typical job of Samza:
In general, one task in Samza is one consumer in Kafka. One stream in the input streams is one partition of topic in kafka.
Reference:
[1] 15619 Cloud Computing CMU

相关文章推荐
- Kafka 之 中级
- Linux下Kafka单机安装配置方法(图文)
- Kafka使用入门教程第1/2页
- Logstash 与Elasticsearch整合使用示例
- Kafka+Log4j实现日志集中管理
- Kafka深度解析
- Kafka设计解析(三)- Kafka High Availability (下)
- kafka+storm初探
- storm集群 + kafka单机性能测试
- flume、kafka、storm常用命令
- kafka 一些基本知识
- Kafka入门经典教程
- Kafka初步学习总结
- note of kafka learning (first part, before replication)
- flume部署
- Kafka集群安装
- Kafka的副本策略——《Learning Apache Kafka》学习笔记(原书第三章第4节)
- kafka性能测试
- kafka集群搭建