Python点滴(一)
2016-03-23 00:14
696 查看
以下实例展示了split()函数的使用方法:
以上实例输出结果如下:
调用mat()函数可以将数组转化为矩阵,
eval()函数十分强大,官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果;
a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]"
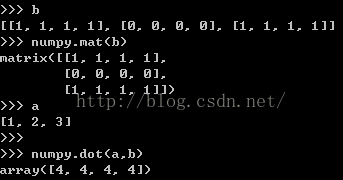
dot()的用法,可以理解为矩阵相乘
Neither argument is complex-conjugated:
>>>
For 2-D arrays it is the matrix product:
>>>
listFromLine[0:0] = ['1']可以在列表开头添加‘1’
enumerate 函数用于遍历序列中的元素以及它们的下标:
>>> for i,j in enumerate(('a','b','c')):
print i,j
0 a
1 b
2 c
ravel的用法
>>> a.ravel() # 平坦化数组
array([ 7., 5., 9., 3., 7., 2., 7., 8., 6., 8., 3., 2.])
>>> a.shape= (6, 2)
>>> a.transpose()
array([[ 7., 9., 7., 7., 6., 3.],
[ 5., 3., 2., 8., 8., 2.]])
numpy.fill的用法
shape的用法,返回的是(行数,列数)的形式
range的用法
Array=[2,3,9,1,4,7,6,8]
fig.add_subplot()的用法
参数349的意思是:将画布分割成3行4列,图像画在从左到右从上到下的第9块,如下图:


ax.scatter用来画散点图
以下展示了使用 uniform() 方法的实例:
以上实例运行后输出结果为:
>>> a = [11,22,33,44,11,22]
>>> b = set(a)
>>> b
set([33, 11, 44, 22])
矩阵相乘:

exp()的用法:
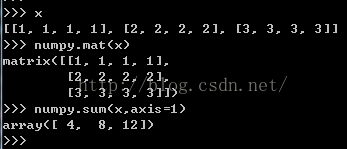
sum中axis=1求和的意义
numpy中repeat的用法
数组array与列表list中的元素删除是不同的:
list dictionary
键盘原始输入
字符串处理合并:
输入输出流
<span style="font-size:14px;">>>> D2={}
>>> for (k,v) in zip(keys,vals): D2[k]=v
...
>>> D2
{'toast': 5, 'eggs': 3, 'spam': 1}
>>>
>>>
>>> f=open('script1.py')
>>> lines=f.readline()
>>> lines
'import sys\n'
>>> lines=[line.rstrip() for line in lines]
>>> lines
['i', 'm', 'p', 'o', 'r', 't', '', 's', 'y', 's', '']
</span>
*args传参
<span style="font-size:14px;">>>> def min1(*args):
res=args[0]
for arg in args[1:]:
if arg<res:
res=arg
return res
>>> args=(2,3,4,5)
>>> min1(args)
(2, 3, 4, 5)
>>> </span>
<span style="font-size:14px;">#!/usr/bin/python
str = "Line1-abcdef \nLine2-abc \nLine4-abcd";
print str.split( );
print str.split(' ', 1 );</span>以上实例输出结果如下:
<span style="font-size:14px;">['Line1-abcdef', 'Line2-abc', 'Line4-abcd']</span>
<span style="font-size:14px;">['Line1-abcdef', '\nLine2-abc \nLine4-abcd']</span>
调用mat()函数可以将数组转化为矩阵,
eval()函数十分强大,官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果;
a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]"
<span style="font-size:14px;"><span style="font-family:Microsoft YaHei;"> b = eval(a) b [[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]]</span></span>
dot()的用法,可以理解为矩阵相乘
>>> np.dot(3, 4) 12
Neither argument is complex-conjugated:
>>>
>>> np.dot([2j, 3j], [2j, 3j]) (-13+0j)
For 2-D arrays it is the matrix product:
>>>
>>> a = [[1, 0], [0, 1]] >>> b = [[4, 1], [2, 2]] >>> np.dot(a, b) array([[4, 1], [2, 2]])
listFromLine[0:0] = ['1']可以在列表开头添加‘1’
enumerate 函数用于遍历序列中的元素以及它们的下标:
>>> for i,j in enumerate(('a','b','c')):
print i,j
0 a
1 b
2 c
ravel的用法
>>> a.ravel() # 平坦化数组
array([ 7., 5., 9., 3., 7., 2., 7., 8., 6., 8., 3., 2.])
>>> a.shape= (6, 2)
>>> a.transpose()
array([[ 7., 9., 7., 7., 6., 3.],
[ 5., 3., 2., 8., 8., 2.]])
numpy.fill的用法
>>> a = np.array([1, 2]) >>> a.fill(0) >>> a array([0, 0]) >>> a = np.empty(2) >>> a.fill(1) >>> a array([ 1., 1.])
shape的用法,返回的是(行数,列数)的形式
1 >>> a=mat([[1,2,3],[5,6,9]]); 2 >>> a 3 matrix([[1, 2, 3], 4 [5, 6, 9]]) 5 >>> shape(a)[0] //shape=[2,3] 6 2 7 >>> shape(a)[1] 8 3
range的用法
>>> range(1,10) ——>不包括10 [1, 2, 3, 4, 5, 6, 7, 8, 9] >>>range(1,10,2) ——>1到10,间隔为2(不包括10) [1, 3, 5, 7, 9] >>>range(10) ——>0到10,不包括10 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Array=[2,3,9,1,4,7,6,8]
>>>Array[0:] ——>切片从前面序号“0”开始到结尾,包括“0”位 [2, 3, 9, 1, 4, 7, 6, 8] >>>Array[:-1] ——>切片从后面序号“-1”到最前,不包括“-1”位 [2, 3, 9, 1, 4, 7, 6] >>>Array[3:-2] ——>切从前面序号“3”开始(包括)到从后面序号“-2”结束(不包括) [1, 4, 7] >>>Array[3::2] ——>从前面序号“3”(包括)到最后,其中分隔为“2” [1, 7, 8] >>>Array[::2] ——>从整列表中切出,分隔为“2” [2, 9, 4, 6] >>> Array[3::] ——>从前面序号“3”开始到最后,没有分隔 [1, 4, 7, 6, 8] >>> Array[3::-2] ——>从前面序号“3”开始,往回数第二个,因为分隔为“-2” [1, 3] >>> Array[-1] ——>此为切出最后一个 8 >>>Array[::-1] ——>此为倒序 [8, 6, 7, 4, 1, 9, 3, 2]
fig.add_subplot()的用法
import matplotlib.pyplot as plt from numpy import * fig = plt.figure() ax = fig.add_subplot(349) ax.plot(x,y) plt.show()
参数349的意思是:将画布分割成3行4列,图像画在从左到右从上到下的第9块,如下图:
import matplotlib.pyplot as plt from numpy import * fig = plt.figure() ax = fig.add_subplot(2,1,1) ax.plot(x,y) ax = fig.add_subplot(2,2,3) ax.plot(x,y) plt.show()
ax.scatter用来画散点图
以下展示了使用 uniform() 方法的实例:
#!/usr/bin/python # -*- coding: UTF-8 -*- import random print "uniform(5, 10) 的随机数为 : ", random.uniform(5, 10) print "uniform(7, 14) 的随机数为 : ", random.uniform(7, 14)
以上实例运行后输出结果为:
uniform(5, 10) 的随机数为 : 6.98774810047 uniform(7, 14) 的随机数为 : 12.2243345905
def __init__(self) 是类实体化时自动运行的初始化函数, def __init__(self)是初始化基类, self 就相当于一个对象,把每个变量初始化,下边就是调用方法了 , 对象.属性,对象.赋值。
set可以用来消除海量列表里的重复元素
>>> a = [11,22,33,44,11,22]
>>> b = set(a)
>>> b
set([33, 11, 44, 22])
矩阵相乘:
exp()的用法:
import math math.exp( x )
sum中axis=1求和的意义
numpy中repeat的用法
<span style="font-size:14px;">>>> repeat(1,4) array([1, 1, 1, 1]) >>> >>> a=[10,20] >>> repeat(a,[3,2]) array([10, 10, 10, 20, 20]) >>> b=[[10,20],[30,40]] >>> b [[10, 20], [30, 40]] >>> repeat(b,[3,2],axis=0) array([[10, 20], [10, 20], [10, 20], [30, 40], [30, 40]]) >>> repeat(b,[3,2],axis=1) array([[10, 10, 10, 20, 20], [30, 30, 30, 40, 40]])</span>
<span style="font-size:14px;">>>> a [[1, 2, 3], [4, 5, 6]] >>> numpy.argmax(a,axis=0) //axis=0表示一列一列的来进行比较输出最大值所对应的 行 array([1, 1, 1], dtype=int64) >>> numpy.argmax(a,axis=1) //axis=1表示一行一行的来进行比较输出最大值所对应的 列 array([2, 2], dtype=int64) >>> </span>
<span style="font-size:14px;">>>> mat([[1.0,1.2,2.0]])*(mat([[2.0,1.0,3.0]]).transpose()) matrix([[ 9.2]]) //注意始终是要有两个中括号的 >>> m=mat([[1.0,1.2,2.0]])*(mat([[2.0,1.0,3.0]]).transpose()) >>> m matrix([[ 9.2]]) >>> m.argmax(1) <strong>matrix([[0]], dtype=int64)</strong> >>> m.argmax(1)[0,0] 0 >>> >>> n=mat([[4,5,6,7]]) //一列一列的寻找最大值 >>> n.argmax(1)[0,0] //返回的依然是下角标 3 >>> </span>
数组array与列表list中的元素删除是不同的:
<span style="font-size:14px;">>>> import numpy
>>> numpy.arange(5)
array([0, 1, 2, 3, 4])
>>>
>>> a=[1,2,3]
>>> a.remove(1)
>>> a
[2, 3]
>>>
>>> a.pop(0) //角标位置
2
>>> a
[3]
>>>
>>>
>>> b=numpy.arange(5)
>>> b
array([0, 1, 2, 3, 4])
>>> b.pop(2)
Traceback (most recent call last):
File "<pyshell#13>", line 1, in <module>
b.pop(2)
AttributeError: 'numpy.ndarray' object has no attribute 'pop'
>>> help('numpy.delete')
Help on function delete in numpy:
numpy.delete = delete(arr, obj, axis=None)
Return a new array with sub-arrays along an axis deleted. For a one
dimensional array, this returns those entries not returned by
`arr[obj]`.
Parameters
----------
arr : array_like
Input array.
obj : slice, int or array of ints
Indicate which sub-arrays to remove.
axis : int, optional
The axis along which to delete the subarray defined by `obj`.
<strong>If `axis` is None, `obj` is applied to the flattened array.</strong>
Returns
-------
out : ndarray
A copy of `arr` with the elements specified by `obj` removed. Note
that `delete` does not occur in-place. If `axis` is None, `out` is
a flattened array.
See Also
--------
insert : Insert elements into an array.
append : Append elements at the end of an array.
Notes
-----
Often it is preferable to use a boolean mask. For example:
>>> mask = np.ones(len(arr), dtype=bool)
>>> mask[[0,2,4]] = False
>>> result = arr[mask,...]
Is equivalent to `np.delete(arr, [0,2,4], axis=0)`, but allows further
use of `mask`.
Examples
--------
>>> arr = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
>>> arr
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
>>> np.delete(arr, 1, 0) //一列一列的看
array([[ 1, 2, 3, 4],
[ 9, 10, 11, 12]])
>>> np.delete(arr, np.s_[::2], 1) //隔两个切片
array([[ 2, 4],
[ 6, 8],
[10, 12]])
>>> np.delete(arr, [1,3,5], None)
array([ 1, 3, 5, 7, 8, 9, 10, 11, 12])
>>> numpy.delete(b,[2],None)
array([0, 1, 3, 4])
>>>
>>>
>>> c=numpy.array([1,2,3],[4,5,6])
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
c=numpy.array([1,2,3],[4,5,6])
TypeError: data type not understood
>>>
>>> c=numpy.array([[1,2,3],[4,5,6]])
>>> c
array([[1, 2, 3],
[4, 5, 6]])
>>> numpy.mat(c)
matrix([[1, 2, 3],
[4, 5, 6]]) // 两个看起来比较相似
>>> </span><span style="font-size:14px;">>>>> a = [[1,2,3],[4,5,6],[7,8,9]] //列表形式 >>>> print a > [[1, 2, 3], [4, 5, 6], [7, 8, 9]] >>>> b = a.pop(1) >>>> print a > [[1, 2, 3], [7, 8, 9]] >>>> print b > [4, 5, 6] >>>> from numpy import array >>>> a = array([[1,2,3],[4,5,6],[7,8,9]]) >>>> print a > [[1 2 3] > [4 5 6] > [7 8 9]] >>>> b = a.pop(1) > > Traceback (most recent call last): > File "<pyshell#14>", line 1, in <module> > b = a.pop(1) > AttributeError: <strong>'numpy.ndarray' object has no attribute 'pop'</strong> >>>> > > So, what's the "right" way of doing this in numpy? The closest thing I can come up with, is In [1]: from numpy import * In [2]: a = array([[1,2,3],[4,5,6],[7,8,9]]) In [3]: b = a[1] In [4]: a = delete(a,[1], axis=0)</span>
list dictionary
<span style="font-size:14px;">>>> L=[1,2,3]
>>> D={'a':1,'b':2}
>>> A=L[:]
>>> B=D.copy()
>>> A[1]='Ni'
>>> A
[1, 'Ni', 3]
>>> L
[1, 2, 3]
>>> B['c']='spam'
>>> B
{'a': 1, 'c': 'spam', 'b': 2}
>>> D
{'a': 1, 'b': 2}
</span>键盘原始输入
<span style="font-size:14px;">>>> while True:
... reply=raw_input('Enter text:')
... if reply=='stop':break
... print reply.upper()
...
Enter text:jj
JJ
Enter text:kk
KK
Enter text:ll
LL
Enter text:jj
JJ
Enter text:aa
AA
Enter text:bb
BB
Enter text:c
C
Enter text:c
C
Enter text:e
E
Enter text:f
F
Enter text:stop
>>>
</span><span style="font-size:14px;">>>> L=[1,2,3,4] >>> while L: ... front,L=L[0],L[1:] ... print front,L ... 1 [2, 3, 4] 2 [3, 4] 3 [4] 4 [] </span>
字符串处理合并:
<span style="font-size:14px;">>>> S='spam' >>> S+='SPAM' >>> S 'spamSPAM' </span>
<span style="font-size:14px;">>>> L=[1,2,3,4] >>> L [1, 2, 3, 4] >>> L.extend([5,6]) >>> L [1, 2, 3, 4, 5, 6] >>> L+=[7,8] >>> L [1, 2, 3, 4, 5, 6, 7, 8] >>> </span>
输入输出流
<span style="font-size:14px;">>>> import sys
>>> temp=sys.stdout
>>> sys.stdout=open('log.txt','a')
>>> print 'spam'
>>> print 1,2,3
>>> sys.stdout.close()
>>> sys.stdout=temp
>>> print'back here'
back here
>>> print open('log.txt').read()
spam
1 2 3
</span><span style="font-size:14px;">>>> range(5),range(2,5),range(0,10,2) ([0, 1, 2, 3, 4], [2, 3, 4], [0, 2, 4, 6, 8]) >>> >>> >>> L=[1,2,3,4,5] >>> for i in range(len(L)): ... L[i]+=1 ... >>> L [2, 3, 4, 5, 6] </span>
<span style="font-size:14px;">字典压缩合成</span>
<span style="font-size:14px;">>>> keys=['spam','eggs','toast']
>>> vals=[1,3,5]
>>> zip(keys,vals)
[('spam', 1), ('eggs', 3), ('toast', 5)]
</span><span style="font-size:14px;">>>> D2={}
>>> for (k,v) in zip(keys,vals): D2[k]=v
...
>>> D2
{'toast': 5, 'eggs': 3, 'spam': 1}
>>>
>>>
>>> f=open('script1.py')
>>> lines=f.readline()
>>> lines
'import sys\n'
>>> lines=[line.rstrip() for line in lines]
>>> lines
['i', 'm', 'p', 'o', 'r', 't', '', 's', 'y', 's', '']
</span>
<span style="font-size:14px;">>>> def f1():
... x=88
... f2(x)
...
>>> def f2(x):
... print x
...
>>> f1()
88
>>>
...
>>>
>>> def func():
... x=4
... action=(lambda n:x**n)
... return action
...
>>>
>>> x=func() //实例化func()为x 然后自动传参
>>> print x(2)
16
>>>
>>> def f(a,b=2,c=3): print a,b,c
...
>>> f(4) //自动传参
4 2 3
>>>
>>> def f(a,*pargs,**kargs): print a,pargs,kargs
...
>>> f(1,2,3,x=1,y=2)
1 (2, 3) {'y': 2, 'x': 1} //元组的形式 字典的形式</span>*args传参
<span style="font-size:14px;">>>> def min1(*args):
res=args[0]
for arg in args[1:]:
if arg<res:
res=arg
return res
>>> args=(2,3,4,5)
>>> min1(args)
(2, 3, 4, 5)
>>> </span>

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- 肯特·贝克:改变人生的代码整理魔法